
1. 정렬
정렬(Sorting)은 데이터를 사용자가 설정한 기준에 따라서 순서대로 나열하는 것을 말한다. 보통은 문제의 조건에 따라서 오름차순이나 내림차순으로 정렬을 한다. 정렬되는 데이터는 꼭 하나의 '수' 혹은 '문자' 뿐만 아니라, 데이터 값이 2개가 입력된 튜플 자료형이 하나의 값으로써 사용자의 설정에 따라서 정렬되기도 한다. 단순히 정렬을 해야 하는 경우라면 내장 함수 sort, sorted를 사용하는데, 문제의 조건에 따라서 직접 정렬을 시켜야 하는 경우도 있기에 여러가지 방법으로 데이터를 정렬하는 법을 살펴보자.
특히 선택, 삽입, 버블, 계수정렬은 for 반복문을 통해 정렬을 시키는데 반해, 병합정렬과 퀵정렬은 재귀함수를 통한 반복문을 실행시키기에 앞의 4가지 방법보다 연산이 빠르다는 장점이 있지만 재귀함수의 이해가 선행되지 않으면 이해하기 조금 어렵다는 단점이 있다. 먼저 앞선 4가지를 살펴보고 그 다음 병합과 퀵정렬을 살펴보겠다.
2. 버블정렬
버블(거품)정렬은 선택 정렬과 매우 흡사하며 연산 횟수도 같다. 버블정렬은 데이터를 순서대로 살펴보며 바로 앞의(인접한) 원소와 현재 인덱스의 원소의 수를 비교하여 조건에 따라서 자리를 교환하며 정렬하는 방법이다. 그림과 같이 리스트를 앞에서부터 시작하여 인덱스가 증가함에 따라서 인덱스의 앞의 수와 비교하여 앞의 수가 현재의 수보다 작다면 교체하는 식으로 진행한다.
그림과 같이 리스트를 앞에서부터 시작하여 인덱스가 증가함에 따라서 인덱스의 앞의 수와 비교하여 앞의 수가 현재의 수보다 작다면 교체하는 식으로 진행한다.
import random
def Bsort(nums):
for i in range(len(nums) - 1):
for j in range(i + 1, len(nums)):
if nums[i] > nums[j]:
nums[i], nums[j] = nums[j], nums[i] # 가장 작은 수를 찾았을 때마다 업데이트(가장 작은 수 j를 minN으로 업데이트와 연산 횟수가 같다)
return nums
if __name__ == '__main__':
nums = random.sample(range(0, 10), 10)
print('Before:', nums)
print('After:', Bsort(nums))
출력:
Before: [5, 9, 3, 7, 8, 2, 6, 4, 0, 1]
After: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
# 버블정렬과 선택정렬은 매우 흡사하다.
# 아래는 선택정렬이다.
# 가장 작은 수를 찾은 후 바꿀 것인지(선택정렬), 작은 수가(가장 작든 아니든, 현재보다 작다면) 나타날 때마다 바꿀 것인지(버블정렬)
import random
def Ssort(nums):
for i in range(len(nums) - 1): # i는 가장 작은 수가 교체될 인덱스 번호.
minN = i # 일단 i 를 가장 작은 값으로 초기화하여 다음 반복문을 통해서 nums[i]보다 작은 수를 찾아간다.
for j in range(i + 1, len(nums)): # i의 다음 인덱스부터 끝까지 탐색한다.
if nums[minN] > nums[j]: # 현재 nums[i]보다 nums[j]가 더 작다면, 이제는 인덱스 j 값을 가장 작은 값으로 업데이트한다.
minN = j
nums[minN], nums[i] = nums[i], nums[minN] # 첫번째 안쪽 반복문이 끝이나면 가장 작은 수를 찾았을 것이다.
return nums # 가장 작은 수와 가장 작은 수가 들어갈 인덱스 i의 데이터를 교체한다.
if __name__ == '__main__':
nums = random.sample(range(0, 10), 10)
print('Before:', nums)
print('After:', Ssort(nums))
출력:
Before: [8, 5, 1, 2, 3, 6, 7, 0, 4, 9]
After: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]3. 계수정렬(Count Sort)
계수정렬은 선택, 삽입 버블정렬처럼 데이터의 값을 비교(비교에 기반한 정렬)한 뒤 교체하는 것이 아니라, 별도의 크기(예: 가장 큰 값 + 1)의 리스트를 선언한 후, 정렬이 되지 않은 배열을 처음부터 순회하며 얻어진 데이터를 별도로 선언한 리스트에 정보를 담아서 출력하는 형식이다. 별도 크기의 리스트를 선언해야하기에 공간복잡도에 의해 데이터의 값 자체(가장 큰 수)가 1백만 혹은 1천만이 넘어가는 데이터를 정렬할 때에는 알맞지 않는 정렬이다. 데이터의 값 자체가 크지 않으면서 데이터의 같은 수가 많이 반복이 된다든지 아니면 데이터의 갯수가 많아도 빠르게 동작한다는 장점이 있다.
계수정렬이 진행하는 방법은 별도로 선언한 리스트의 인덱스를 활용하는 것이다. 정렬되지 않은 데이터의 값은 별도의 리스트의 인덱스가 되고, 그 인덱스의 값(0으로 초기화 된)에 +1을 해준다. 모든 탐색이 끝났다면 해당 리스트의 인덱스의 값 안에는 탐색한 숫자의 빈도수가 담겨있고 해당 인덱스 값에 이 빈도수를 곱하여 인덱스 0부터 출력하면 된다.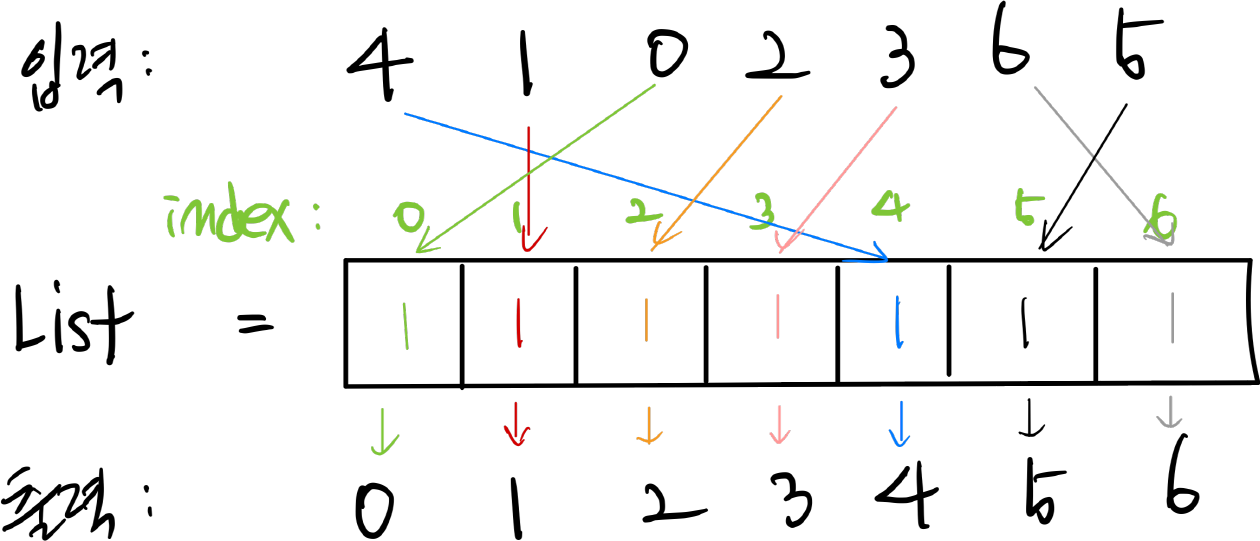 그림과 같이 정렬되지 않은 데이터 값이 입력이 되면, 데이터를 순서대로 탐색하며 해당 데이터 값을 리스트의 인덱스로 치환하여 1을 더해준다. 중복이 있다 하더라도 중복된 수 만큼, 즉 'index x index값'만큼 리스트를 순차적으로 탐색하며 출력하면 정렬된 데이터가 반환된다.
그림과 같이 정렬되지 않은 데이터 값이 입력이 되면, 데이터를 순서대로 탐색하며 해당 데이터 값을 리스트의 인덱스로 치환하여 1을 더해준다. 중복이 있다 하더라도 중복된 수 만큼, 즉 'index x index값'만큼 리스트를 순차적으로 탐색하며 출력하면 정렬된 데이터가 반환된다.
import random
def Csort(nums):
answer = []
for i in nums:
clist[i] += 1 # nums의 값을 clist의 인덱스 값으로 치환하여 1씩 더한다.
for idx, val in enumerate(clist): # clist의 인덱스(원래의 값)와 val(빈도수)을 불러와서
for i in range(val): # val(빈도수)만큼 반복하여 idx(원래의 값)을 출력하도록.
answer.append(idx)# 문제의 형식에 따라서 바로 출력하든, 리스트에 담든 조건에 따라서
return answer
if __name__ == '__main__':
nums = []
for _ in range(20):
n = random.randint(0, 10)
nums.append(n)
clist = [0] * (max(nums) + 1) # 가장 큰 수 보다 1 더 크게(파이썬은 0부터 시작한다)
print('Before:', nums)
print('After:', Csort(nums))
출력:
Before: [9, 8, 10, 1, 7, 0, 8, 5, 3, 3, 4, 9, 1, 6, 2, 7, 6, 10, 3, 8]
After: [0, 1, 1, 2, 3, 3, 3, 4, 5, 6, 6, 7, 7, 8, 8, 8, 9, 9, 10, 10]단순히 정렬을 하기 위해서는 내장함수 sort, sorted나 라이브러리써서 해결하면 될 것이다. 하지만 문제에서 요구하는 것이 단순 정렬이 아닌, 위 정렬들의 알고리즘의 개념을 적용할 수 있는 것인지 묻는 문제가 많이 나온다. 반복문의 사용과 빈도수, 최대값 혹은 최소값을 구해야 하는 문제들, 그리고 계수정렬 때처럼 리스트의 값이 아닌 리스트의 인덱스 자체를 활용해야만 풀 수 있는 문제들이다. 익숙해질 때 까지 여러 방법으로 정렬해보도록 하자.
