파이썬에서 hash로 이루어진 자료구조로는 set()과 dict() 자료구조가 있다.
잠시 Hash에 대해 간략히 알아보고 문제풀이로 넘어가보자.
1.1 Hashing
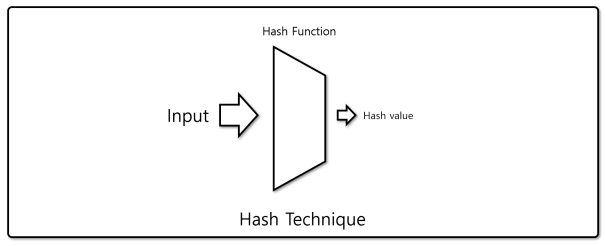
해싱은 위의 그림과 같이 데이터가 입력이 되면 Hash Function(해시 함수)를 통해서 일정한 길이의 값으로 변환하는 것을 말한다. 파이썬에서 내장 함수로 해시 함수를 재공한다. 아래의 예와 같이 무작위의 숫자가 출력이 되면 bucket_size(bucket: 출력이 된 해쉬 값을 담을 배열)에 따라 저장이 된다. 예로 bucket가 5라면 '출력된 수'를 5로 나눈 나머지(%)의 값은 0 ~ 4 사이의 값을 지니게 되고 배열의 길이 즉, bucket_size는 5가 된다.print(hash('a')) 출력 : 1532533538094313450 print(hash('b')) 출력 : 6999430534811155991
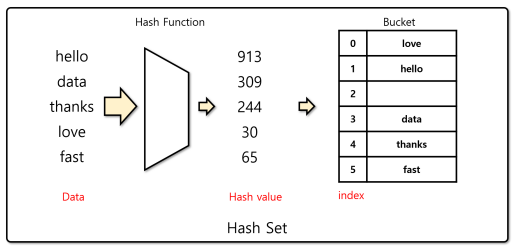
1.2 Hash Set
해시 셋은 bucket_size를 이용해 자료를 저장할 때 index를 위에서 말한 것처럼 버킷의 크기로 나눈 나머지 값으로 한다. 이런 방법은 파이썬에서 'set 자료구조'로 구현이 되어 있으며, 같은 값이 들어오면 항상 같은 인덱스에 같은 값이 들어가게 됨으로 중복을 허용하지 않고 자료를 빠르게 탐색한다. 빅오 표기법으로 표현하면 O(1) 상수시간의 연산 횟수를 가진다.
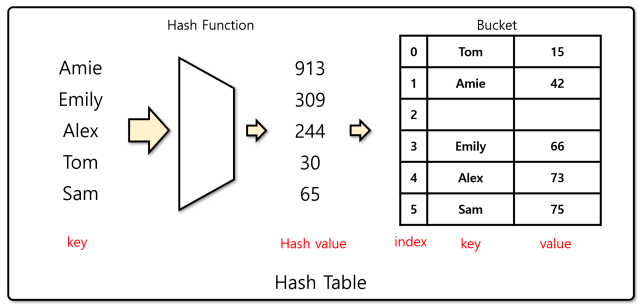
1.3 Hash Table
해시 셋과 같은 동작을 하는데 인덱스에 값만 넣는 것이 아닌 key와 value로 짝을 이루어 저장한다. 이런 방법은 파이썬에서 'dict 자료구조'로 구현이 되어 있으며, key 값은 중복이 되지 않지만 value는 중복을 허용하기에 지속적인 업데이트가 가능하다.
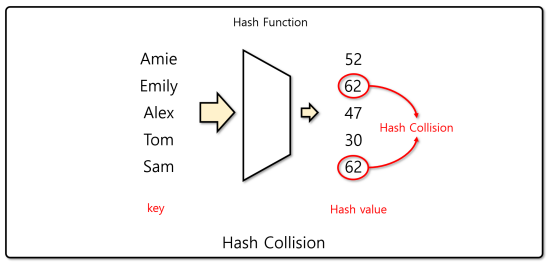
1.4 Hash Collision
살펴보면 '다른 값'이 들어오더라도 해싱의 '값이 같거나' bucket_size로 나눈 '나머지가 같은' 경우가 발생할 수 있는데, 이 때 해시충돌이 발생했다고 한다. 해결법은 여러가지가 있지만 대표적으로 해싱 인덱스에 제곱을 하거나 Linked List를 추가할 수도 있는 등의 방법이 있다.
2. 문제
문제1 : 용배는 편지를 쓰는데 습관처럼 자주 쓰는 문자가 있다. 중복되는 문자를 제거하고, 보기 좋게 오름차순으로 출력하시오.
문제2 : 용배에게 문자암호가 전달되었는데 가장 많이 중복되는 문자들을 없애야 그 뜻이 드러나는 암호문이다. 암호문을 출력하시오.
2.1 풀이
풀이1 : 내장함수 set을 쓰면 매우 간단히 출력이 가능하다.
def solution(n): for i in sorted(set(n)): print(i, end=' ') n = ['a', 't', 'g', 'h', 'y', 'o', 'g', 'r', 'h', 'i', 'x', 'z', 'h', 'y', 'o', 'g', 'r', 'h', 'i'] solution(n) 출력: a g h i o r t x y z풀이2 : collctions 모듈의 defaultdict(입력되는 key의 value값을 0으로초기화) 사용한다.
문자를 반복문으로 변수에 할당하면서, 할당될 때마다 해당 문자의 value값을 1씩 증가시키면 2번 반복되면 2를 3번 반복되었다면 3을 할당하는 씩으로 진행한다. 해당 value에 할당이 될 때 해당 value가 현재까지의 반복 횟수보다 높은 value라면 maxN을 높은 value값으로 업데이트한다.
그리고 다시 반복문을 처음부터 실행하면서 가장 높은 maxN보다 작은 value값을 지닌 문자만 출력하게 한다.import collections def solution(call): answer = '' hs = collections.defaultdict(int)# 어떤 key가 입력될 시 value를 '0'으로 초기화한다. 초기화된 수에 더할 수도 있고 새로운 value값을 업데이트한다. maxH = -1 for i in call: hs[i] += 1 # 문자가 입력될 때마다 value 값을 1씩 더한다 if hs[i] > maxH: # 반복문을 통해 가장 많이 반복되는 횟수를 찾아낸다. maxH = hs[i] for id, va in enumerate(call): if maxH > hs[va]: # 가장 많이 반복된 횟수를 기준으로 다시 문자들을 반복시키면서, 가장 큰 값보다 작은 문자들만 출력한다. answer += call[id] return answer n = 'abxdeydeabz' print(solution(n))
3. 기타
- collections 모듈의 defaultdict(int) : value를 정수화 시키면서 key의 value를 0으로 초기화.
딕셔너리 자료구조는 key:value 값 쌍으로 입력해줘야 하는데, defaultdict는 key값만 넣어도 자동으로 value를 지정해준다. 그래서 위의 문제와 같이 key값을 넣는 동시에 key의 value 값이 0으로 초기화되며 0이 된 값에 1을 더해줄 수가 있다. 이렇게 key값만 입력해서 연산을 해야하는 경우에 자주 쓰인다.import collections n = ['a', 'b', 'c'] hs = collections.defaultdict(int) for i in n: print(hs[i], end=' ') 출력: 0 0 0
- collections 모듈의 Counter : key값(문자)의 수를 value로 알려주는 객체 반환
import collections n = 'abxdeydeabz' hs = collections.Counter(n) print(hs) 출력: Counter({'a': 2, 'b': 2, 'd': 2, 'e': 2, 'x': 1, 'y': 1, 'z': 1})
