pandas는 기본적으로 Series(시리즈)와 DataFrame(데이터프레임) 이 두 가지가 핵심 자료구조다.
1. Series
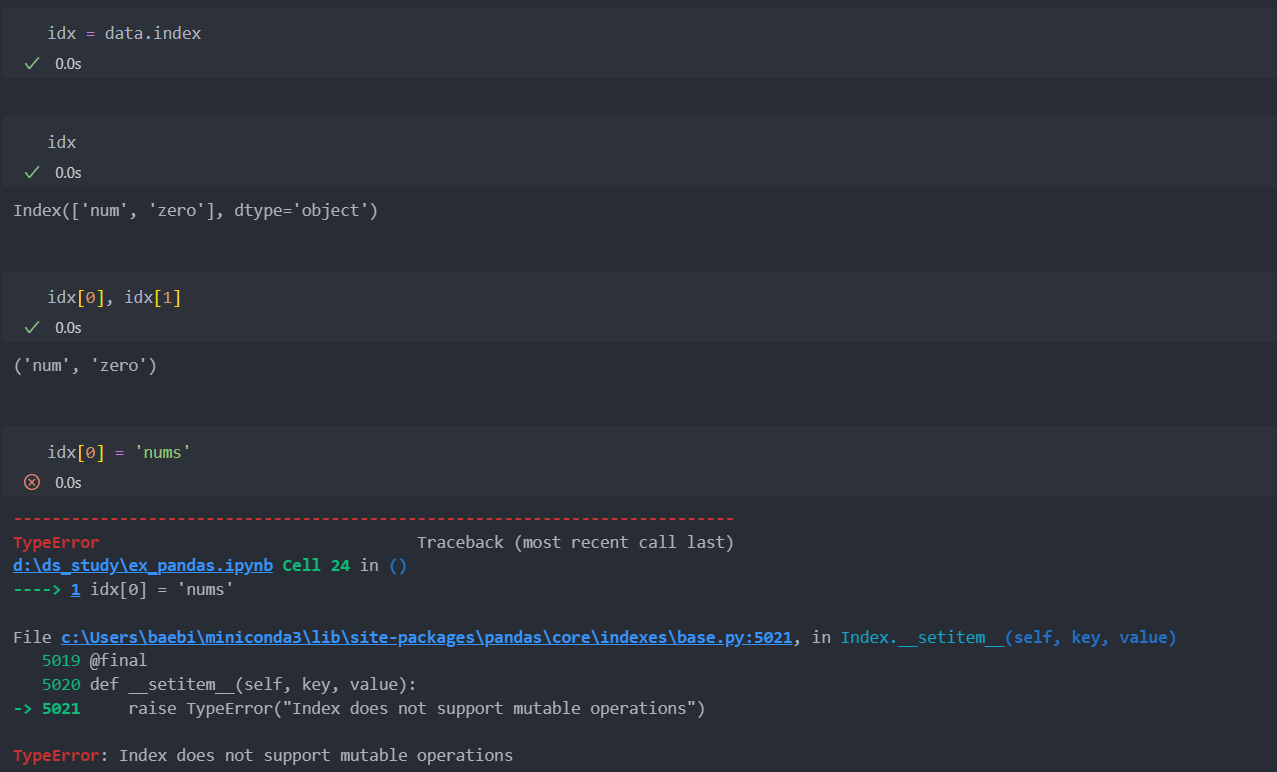
Series는 일련의 객체를 담을 수 있는 1차원 배열 같은 자료구조다. 그리고 index(색인)과 value(정보, 값)을 가지고 있다. Series는 배열 데이터로 생성하며 index값을 지정하지 않았을 시 정수가 순서로 붙는다. 왼쪽은 인덱스, 오른쪽은 해당 값을 보여준다.
in:
s = pd.Series([5, 1, 2, 4, 3])
s
out:
0 5
1 1
2 2
3 4
4 3
dtype: int64index와 value는 지원하는 속성을 통해서 확인할 수 있다.
in:
s.index
out:
RangeIndex(start=0, stop=5, step=1)
in:
s.values
out:
array([5, 1, 2, 4, 3], dtype=int64)index는 직접 지정할 수 있다.
in:
s = pd.Series([5, 1, 2, 4, 3], index=['a', 'b', 'c', 'd', 'e'])
s
out:
a 5
b 1
c 2
d 4
e 3
dtype: int64index를 활용하여 값을 확인할 수 있다.
in:
s.a # 색인 활용
out:
5
in:
s['a'] # 슬라이싱 활용
out:
5
in:
Series는 불리언(논리 연산자) 혹은 수학적 산술을 지원한다.
in:
s*2
out:
a 10
b 2
c 4
d 8
e 6
dtype: int64
in:
2 in s
out:
True
in:
s = pd.Series(
{
'a':10,
'b':100,
'c':1000,
'd':10000,
'e':np.nan
}
)
s
out:
a 10.0
b 100.0
c 1000.0
d 10000.0
e NaN
dtype: float64
in:
s.isnull()
out:
a False
b False
c False
d False
e True
dtype: bool2. DataFrame
DataFrame은 표와 같은 시트 형식의 형태를 띄는 자료구조이다. 그리고 인덱스와 컬럼을 가지며 각 컬럼은 서로 다른 종류의 값들도 담을 수 있다.
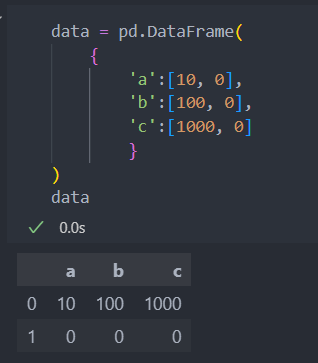
인덱스 값은 정수로 자동 생성되며, 직접 지정할 수도 있다.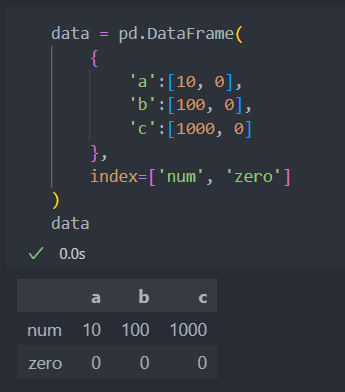
컬럼값의 순서를 지정한 순서대로 나열할 수 있다.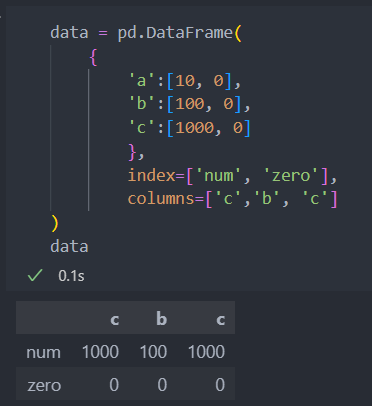
새로운 컬럼을 삽입할 수도 있다. 새로 삽입된 컬럼은 data가 생성될 시 해당 index를 가진 값이 없었기에 결측치 가 생긴다.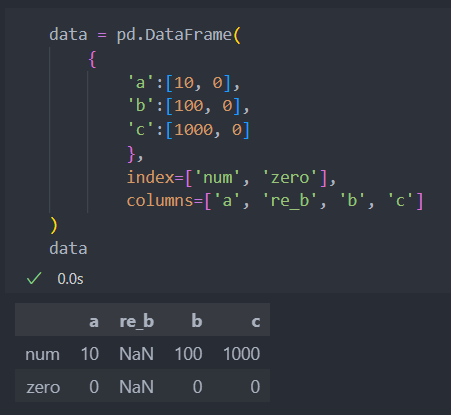
또한 nan값을 채울 수도 있다.(fillna(value) : value에 값을 지정하면 nan값에 해당 값이 삽입된다)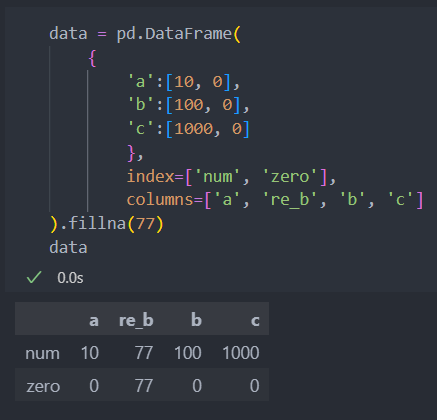
그리고 Series처럼 DataFrame의 컬럼의 값을 사전 형식의 표기법으로 불러오거나 속성 형식으로 불러올 수 있다.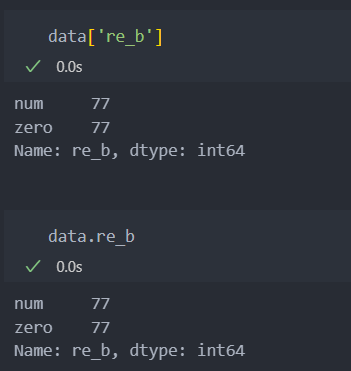
데이터의 인덱스와 컬럼의 위치를 뒤집을 수 있다.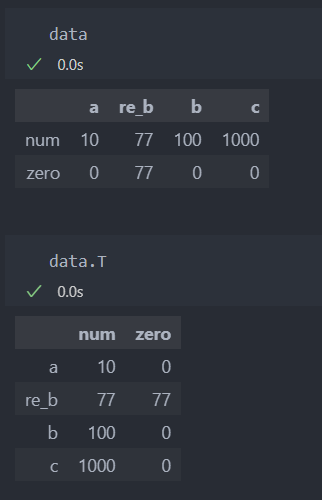
판다스는 각 로우와 컬럼에 대한 축을 기준으로 데이터를 저장하는데, 인덱스의 객체는 변경이 안 된다.