리샘플링은 시계열의 빈도를 변환하는 '과정'을 말한다.
'댜운샘플링'은 상위 빈도의 데이터를 하위 빈도로 계산하는 것을 말하며 '업샘플링'은 그 반대 과정이다.
resample
resample은 빈도 변환과 관련된 연산을 수행하는데 groupby와 비슷하게 동작하는데 데이터를 빈도로 그룹짓고 함수를 적용하는 식이다.
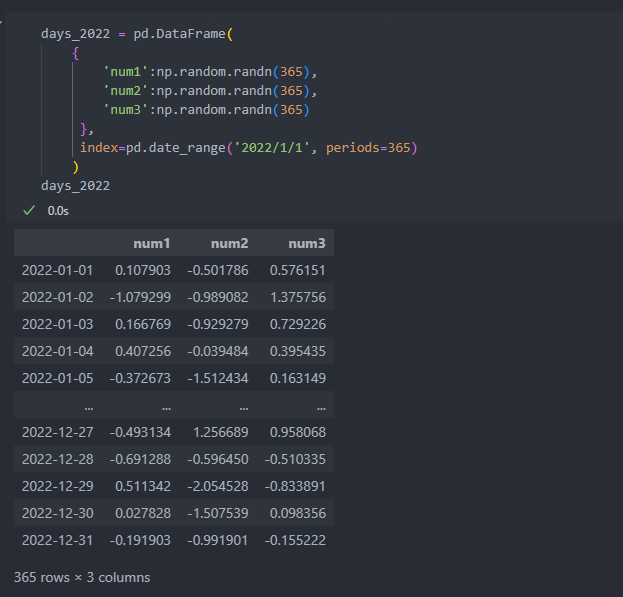
365일을 '월' 기준으로 그룹지으면 
groupby와 같이 반복이 가능한 객체로 바뀌며 '월'을 기준으로 묶어서 12회 반복하며 1회 반복마다 월로 묶여있음을 알 수 있다. 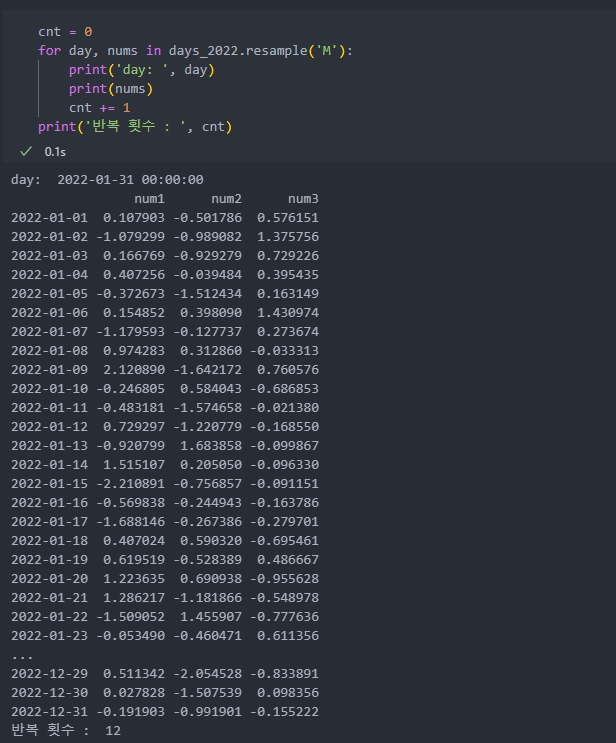
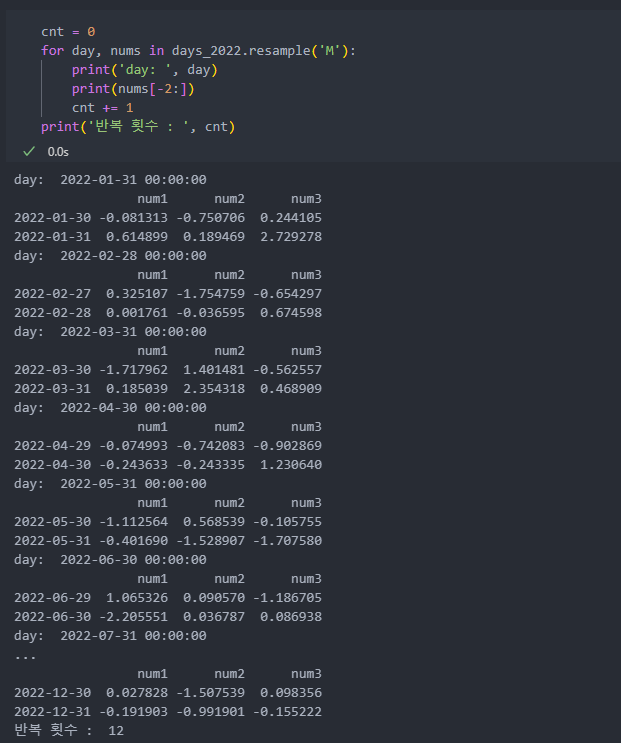
이렇게 리샘플된 객체는 월을 기준으로 월별 합을 구할 수도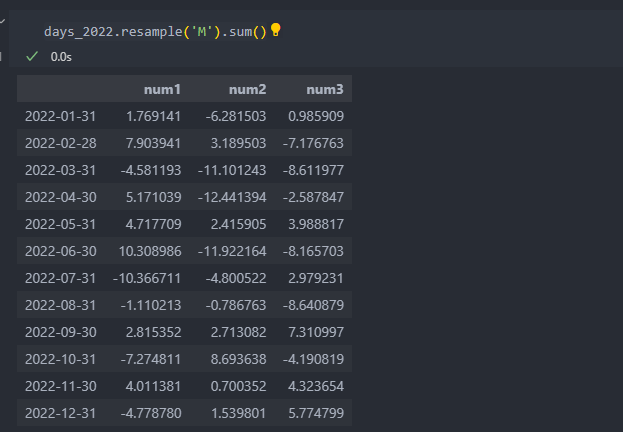 count 함수도 적용할 수 있다.
count 함수도 적용할 수 있다. 
kind
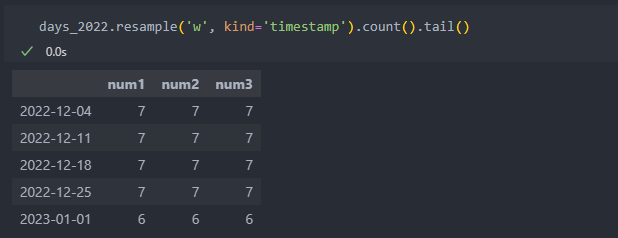
'kind' 메서드 인자로 기간 혹은 타임스탬프별로 집계할 것인지 구분할 수 있다.

label
default(label='rigth')
집계된 결과의 라벨을 결정한다.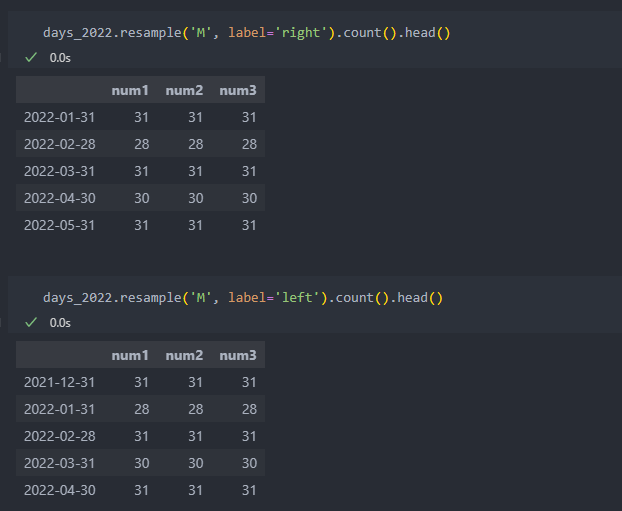
다운샘플링
시계열 데이터를 하위 빈도로 집계할 때 시간, 월 등의 간격으로 데이터를 나눈다. 이 때 각 간격의 양쪽 끝은 한쪽만 포함하고 있다.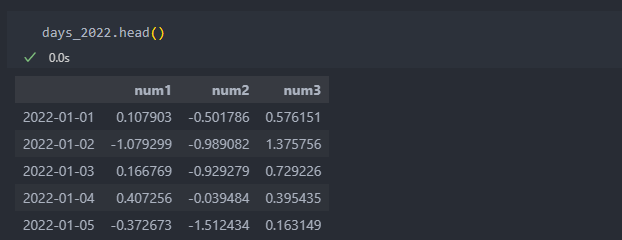 1월 1일은 시계열 데이터의 시작으로 달, 혹은 주로 묶을 때 항상 앞쪽(배열로 나열했을 때 왼쪽)에 자리잡는다. 아래와 같이 1/1과 1/2이 묶여서 계산됨을 알 수 있다.
1월 1일은 시계열 데이터의 시작으로 달, 혹은 주로 묶을 때 항상 앞쪽(배열로 나열했을 때 왼쪽)에 자리잡는다. 아래와 같이 1/1과 1/2이 묶여서 계산됨을 알 수 있다.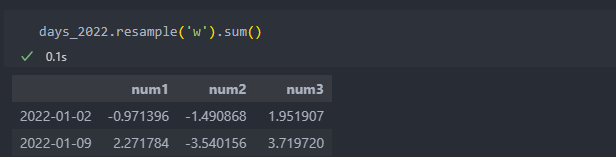 하지만 closed 인자를 바꾸어 1/1을 오른쪽으로 묶이게 되게 할 수 있다.
하지만 closed 인자를 바꾸어 1/1을 오른쪽으로 묶이게 되게 할 수 있다.
closed
closed의 default(label='left')인데, 'right'으로 주게 되면 1/1은 오른쪽으로 포함되게 되어 그룹 연산이 달라지게 된다. 그리고 1/2부터 5일씩 연산이 이루어진다. 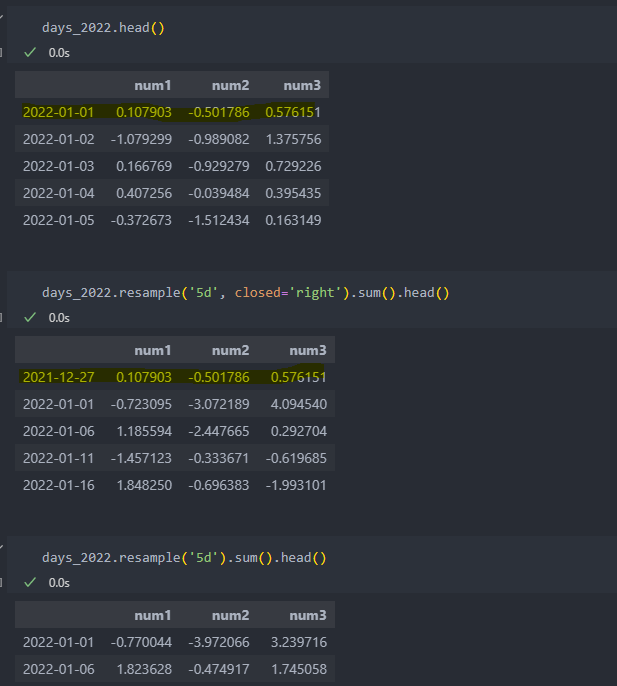
업샘플링
업샘플링을 할 때에는 집계 연산이 되지 않고, 함수에 따라서 0 혹은 NaN값을 반환한다.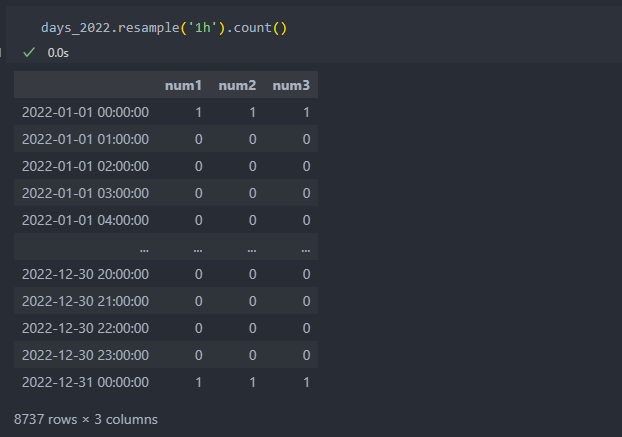
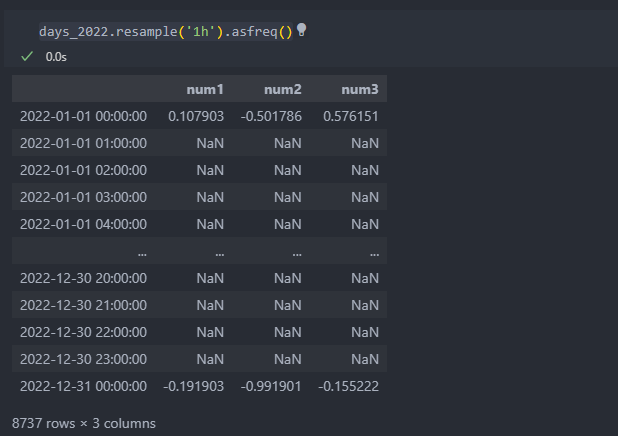 보통 asfreq을 사용하여 NaN값을 채우는 방향으로 사용한다.
보통 asfreq을 사용하여 NaN값을 채우는 방향으로 사용한다.  모두 채우는 것이 아닌 보간하여 범위를 지정할 수 있다.
모두 채우는 것이 아닌 보간하여 범위를 지정할 수 있다.
rolling
rolling에 기간을 넣으면 해당 기간 만큼의 window가 생성된다.
rolling은 기간 만큼의 window가 생성되기에 '시점지점'에서 'rolling 기간'까지 결측치가 발생하게 된다. 아래는 3일 window로 엮어서 평균을 구하는 것인데 앞의 2일은 결측치가 생길 수 밖에 없다. 1/3일부터 계속 3일 간의 평균을 반환하게 되며, 예로 3일간의 매출의 추이 혹은 주식 차트에서 많이 활용된다.
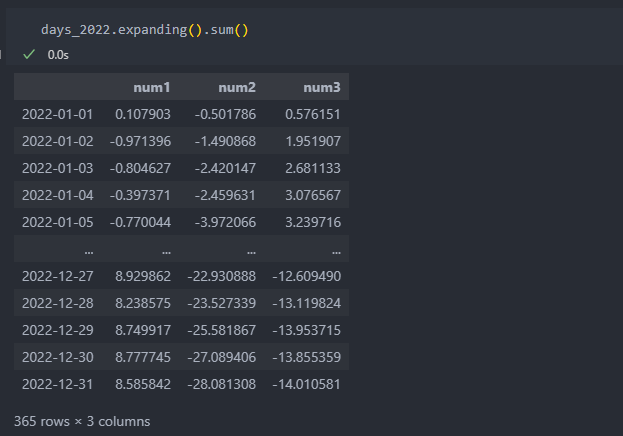
expanding
expanding은 시작 지점부터 끝에 이르기까지 창의 크기를 점점 늘려나간다.