
오늘의 TIL
- SQL 튜닝 (실제 실행계획 보기)
- 집합연산자로 데이터의 교집합을 출력하기 (INTERSECT) (교집합)
- 집합연산자로 데이터의 차이를 출력하기 (MINUS) (차집합)
- DB링크 만들기 (다른 db접속)
- 서브쿼리 사용하기 1 (단일행 서브쿼리) single row subquery
- 서브 쿼리 사용하기 2(다중행 서브쿼리) multiple row subquery
- 서브 쿼리 사용하기 3(NOT IN)
- 서브 쿼리 사용하기 4(다중 컬럼 서브쿼리) multiple column subquery
어제 마지막 문제
문제 348. (오늘의 마지막 문제) 다음과 같이 결과를 출력하세요
직업별 부서번호별 토탈월급들을 출력하는데,
맨 옆과 맨 아래에 집계값이 각각 나오게 출력하시오
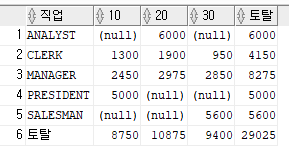
-- sum + decode
select nvl(job,'토탈') as 직업 ,
sum(decode(deptno,10,sal,null)) as "10",
sum(decode(deptno,20,sal,null)) as "20",
sum(decode(deptno,30,sal,null)) as "30",sum(sal)as 토탈
from emp
group by rollup (job);-- pivot (서브쿼리랑 pivot 사용하는 방법 -> 굳이 안써도됨)
select nvl(job,'토탈')as 직업 , sum("10") as "10" , sum("20") as "20" , sum("30") as "30", sum(토탈) as 토탈
from (select job, deptno, sal, sum(sal) over (partition by job) as 토탈
from emp )
pivot (sum(sal) for deptno in(10,20,30))
group by rollup (job)
order by job asc;※ 어차피 pivot 을 사용해도, 오라클이 sum+decode 로 바꿔서 수행함
-> Query transfromation
SQL -> parsing -> Query transfromation -> 실행계획 생성
(기계어로 변환) (오라클이 SQL을 재작성)
(오타 등 체크) (쿼리변화)
full outer join -> union all 로 쿼리변화됨
insert into emp(empno,ename,sal)
values (1234, 'JACK', 70);
문제 349. (SQL 튜닝 방법)
아래의 SQL을 집합 연산자 (union, union all) 와 right outer join 과 left outer join 으로 수행하시오select e.ename, d.loc from emp e full outer join dept d on (e.deptno = d.deptno);select e.ename, d.loc from emp e left outer join dept d on (e.deptno = d.deptno) union select e.ename, d.loc from emp e right outer join dept d on (e.deptno (+) = d.deptno);rowid 써서 정렬 맞춰주는 방법이 있음!!
rowid 번호를 from 절에 서브쿼리로 넣은 다음에 정렬해주고,
select 절에는 rowid 를 안보이게 하면 정렬이 됨!
=> 요런 과정을 튜닝 이라고 함
rowid
: 테이블의 행의 논리적 주소 (file번호# + block번호# + row번호#)
데이터를 insert 하면 생김. (책의 페이지 번호 같은!)
새로 추가하면 마지막에 생김
SQL 튜닝 (실제 실행계획 보기)
무조건 짧은 sql이 좋은것 아님.
메모리 block의 갯수가 적은 sql이 좋음
/+ gather_plan_statistics
-> 지금 db의 성능을 느리게하는 sql이 뭔지 고민해보기전 쓰는거
실제 실행 계획 : SQL을 실제로 실행하고 실행된 SQL의 실행계획 확인
select /*+ gather_plan_statistics */ ename, sal
from emp
where ename='SCOTT';
SELECT * FROM TABLE(dbms_xplan.display_cursor(null,null,'ALLSTATS LAST')); 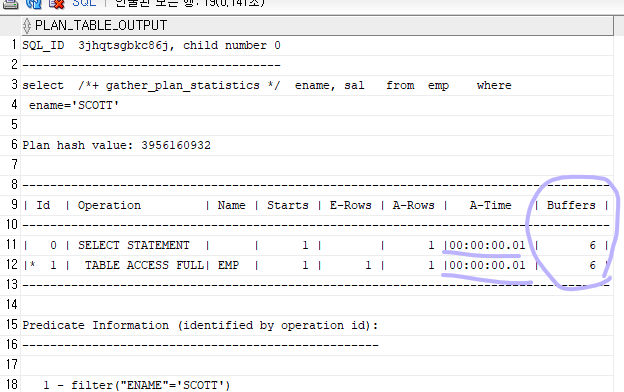
buffers 의 숫자가 작을수록 좋은 sql이다!
튜닝전
select /*+ gather_plan_statistics */ ename, loc
from (
select e.rowid as rw, e.ename, d.loc
from emp e left outer join dept d
on ( e.deptno = d.deptno )
union
select e.rowid as rw, e.ename, d.loc
from emp e right outer join dept d
on ( e.deptno = d.deptno )
order by rw asc
); 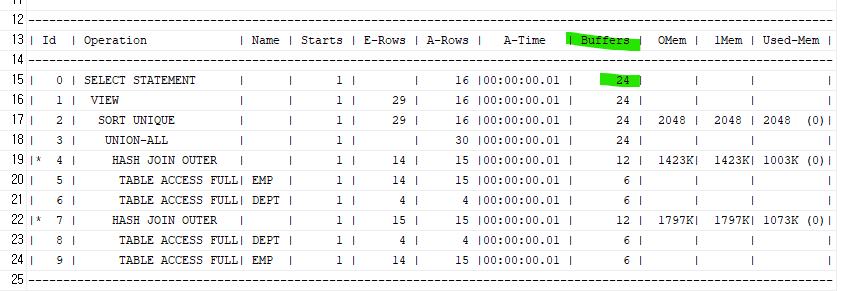
튜닝후
select /*+ gather_plan_statistics */ e.ename, d.loc
from emp e full outer join dept d
on ( e.deptno = d.deptno ); 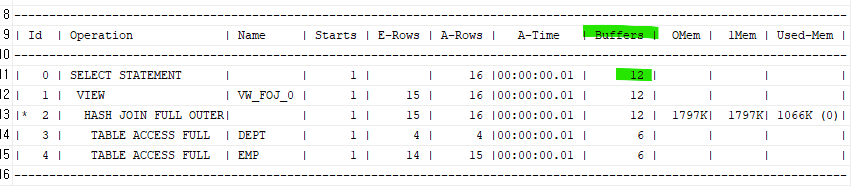
069. 집합연산자로 데이터의 교집합을 출력하기 (INTERSECT) (교집합)
- union all
- union
- intersect : 교집합
- minus
예제.
select deptno, sum(sal)
from emp
where deptno in (10,20)
group by deptno
intersect
select deptno, sum(sal)
from emp
where deptno in (20,30)
group by deptno;
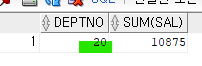
- 운영 DB, 테스트 DB (운영DB를 넣고 테스트해보는 DB)가 있는데
운영DB와 테스트DB를 비슷하게 맞추기위해 계속 테스트 db에 insert 시킨다.
이 때, 운영db와 테스트db의 차이를 보기 위해서 intersect가 쓰인다.
문제 350.
market_2017 과 market_2022 의 건수를 각각 count 하시오select count(*) from market_2017; -> 316078 select count(*) from market_2022; -> 312811
문제 351.
market_2017 테이블에서 상호명이 카페베네를 포함하고 있는 상가업소번호, 상호명을 출력하시오select 상가업소번호, 상호명 from market_2017 where 상호명 like '%카페베네%';-> 72개
문제 352.
market_2022 테이블에서 상호명이 카페베네를 포함하고 있는 상가업소번호, 상호명을 출력하시오select 상가업소번호, 상호명 from market_2022 where 상호명 like '%카페베네%';-> 51개
문제 353.
2022년도에 있는 상호명 카페베네가 2017년도에도 있었던 상가업소번호와 상호명을 출력하시오 (두개의 교집합 구하는)select 상가업소번호, 상호명 from market_2017 where 상호명 like '%카페베네%' intersect select 상가업소번호, 상호명 from market_2022 where 상호명 like '%카페베네%';A 테이블에 있는 데이터중에 B 테이블에도 있는 데이터 구하는거!
070. 집합연산자로 데이터의 차이를 출력하기 (MINUS) (차집합)
A -> 10,20,30
B -> 20,30,40
A-B = 10 만 나온다 (40은 X)
오라클이 차집합을 구할 때는 내부적으로 정렬을 하고 차집합을 구한다.
내부적으로 정렬하는 집합연산자는, 'union', 'intersect', 'minus'
(union all 빼고 다)
문제 354.
2017년도에는 존재했는데 2022년도에 사라진 카페베네 매장은 총 몇개인가?select count(*) from ( select 상호명 from market_2017 where 상호명 like '%카페베네%' minus select 상호명 from market_2022 where 상호명 like '%카페베네%' );from 절에 있는 결과를 count 해라!
(서브쿼리사용)
문제 355.
이번에는 스타벅스도 사라진 매장이 몇개인지 확인하시오select count(*) from ( select 상가업소번호, 상호명 from market_2017 where 상호명 like '%스타벅스%' minus select 상가업소번호, 상호명 from market_2022 where 상호명 like '%스타벅스%' );상가업소번호 넣고 안넣고에 따라 왜 결과가 달라지늬???
DB링크 만들기 (다른 db접속)
문제 356.
짝꿍의 데이터베이스의 emp 테이블을 조회하기 위해서
짝꿍의 아이피 주소를 알아내시오내 pc의 ip주소 알아내는 방법 : 도스창 열고 ipconfig
192.168.19.27
짝꿍 : 192.168.19.24
문제 357.
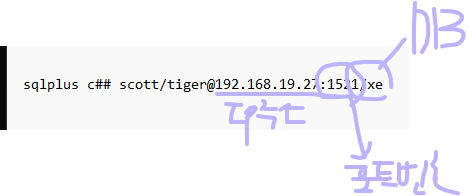
자기 자신의 아이피주소로 자기 자신의 DB에 접속이 되는지를 먼저 확인합니다.
-> 도스창을 열고 아래와 같이 접속합니다.
sqlplus c##scott/tiger@192.168.19.27:1521/xe
문제 358.
짝꿍 데이터베이스로 접속되는지 확인
(SQL> exit) 한다음 ip 다시 입력
sqlplus c##scott/tiger@192.168.19.24:1521/xe
문제 359.
내 sqldeveloper 에서 아래와 같이 짝꿍 db의 테이블들을 조회할 수 있는 db링크 를 생성합니다.create public database link dblink21 connect to C##scott identified by tiger using '192.168.19.24:1521/xe' ;Database link DBLINK21이(가) 생성되었습니다.
※ 조회하는 법 : select * from emp@dblink21;
문제 360.
내 emp 테이블에 랜덤으로 데이터를 한건 입력하시오insert into emp(empno, ename, sal, job, deptno) values (1234, 'suzy', 6000, 'singer', '75'); commit;
문제 361.
짝꿍의 emp 테이블과 나의 emp테이블의 데이터의 차이가 뭐가 있는지 조회하시오select * from emp@dblink21 minus select * from emp;

071. 서브쿼리 사용하기 1 (단일행 서브쿼리)
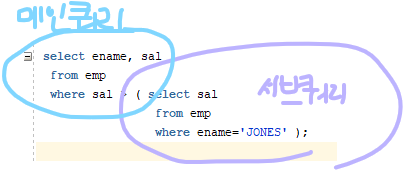
예제. JONES 보다 더 많은 월급을 받는 사원들의 이름과 월급을 출력하시오
select ename, sal
from emp
where sal > 'JONES'; 로 하면 안됨
JONES 의 월급을 먼저 구해야함!
select sal
from emp
where ename='JONES';select ename, sal from emp where sal > ( select sal from emp where ename='JONES' );
메인쿼리 = outer 쿼리
서브쿼리 = inner 쿼리
문제 362. scott 과 같은 월급을 받는 사원들의 이름과 월급을 출력하시오
select ename, sal from emp where sal = ( select sal from emp where ename='SCOTT' );
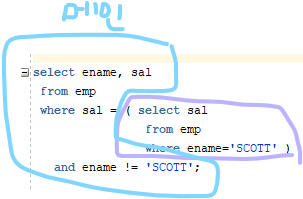
문제 363. 위의 결과를 다시 출력하는데 SCOTT 은 제외하고 출력하시오
select ename, sal from emp where sal = ( select sal from emp where ename='SCOTT' ) and ename != 'SCOTT';
문제 364.
ALLEN 보다 늦게 입사한 사원들의 이름과 입사일을 출력하시오select ename, hiredate from emp where hiredate > ( select hiredate from emp where ename = 'ALLEN' );
문제 365.
서울시 물가 데이터 테이블을 구성하시오
https://cafe.daum.net/oracleoracle/SDMs/1
문제 366.
price 테이블에서 a_price 의 최대값을 출력하시오select max(a_price) from price;
문제 368.
서울시 물가 데이터중에 가장 가격(a_price) 이 비싼
생필품명(a_name), 그 가격(a_price) 를 출력하시오select a_name, a_price from price where a_price = ( select max(a_price) from price);
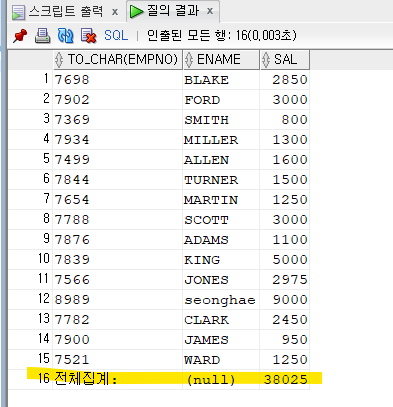
▣ (7월 4일 점심시간 문제) 아래의 SQL의 결과를 집합 연산자(union all 이나 union) 로 구현하시오.
select nvl( to_char( empno), '전체집계:' ) as empno, ename, sum(sal) as sal from emp group by grouping sets( (empno, ename), () );내 답 !!
select to_char(empno), ename, sum(sal) as sal from emp group by empno , ename union all select nvl( to_char( null), '전체집계:' ) as empno, to_char(null) as ename, sum(sal) as sal from emp;
- 그룹바이를 밑에도 쓰면 표가 두개가 나오고 , 그룹바이를 밑에 쓰지 않으면 16번 행만 붙이는 것!
여기까지 친규 블로그 긁어왔슴다...!
주희 벨로그
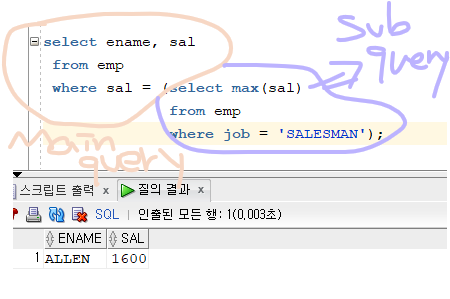
문제 369. (단일행 서브쿼리) 직업이 salesman인 사원들중에 최대월급을 받는 사원의 이름, 월급을 출력
select ename, max(sal) from emp where job = 'SALESMAN'; // 이렇게 쓰면 에러난다. 이름은 많기때문에. group by ename // 그룹바이를 쓰면 max값은 안나오고 직업별 최대월급이 나온다.select ename, sal from emp where sal = (select max(sal) from emp where job = 'SALESMAN');
select ename, sal from emp where sal = (select max(sal) from emp where job = 'SALESMAN') and job = 'SALESMAN';
- AND를 써서 직업이 salesman인 사람들중 이라는 것을 확실하게 쓰기
- and를 쓰지 않으면, 다른 직업중 1600이 출력될 수 있다
문제 370. 위 결과를 서브쿼리 이용하지 말고 order by... fetch row를 이용해서 수행
select ename, max(sal) from emp where job = 'SALESMAN' group by ename order by 2 desc fetch first 1 rows only;
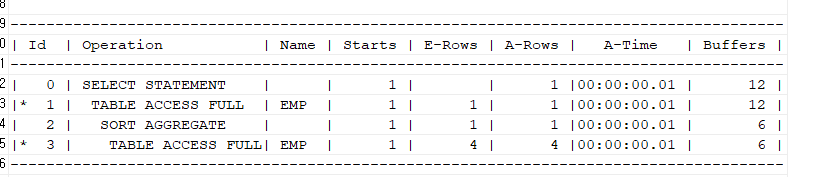
문제 371. 위 2개의 sql의 buffer 갯수 확인
select /*+ gather_plan_statistics */ename, sal from emp where sal = (select max(sal) from emp where job = 'SALESMAN') and job = 'SALESMAN'; SELECT * FROM TABLE(dbms_xplan.display_cursor(null,null,'ALLSTATS LAST'));
- /+ gather_plan_statistics / 이 힌트는, 현SQL에 대한 실행계획에 대한 통계정보를 볼때 사용하는 힌트!
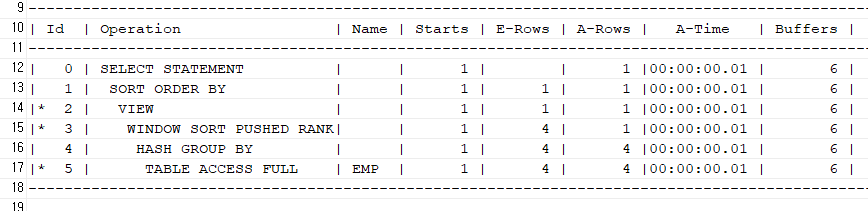
맨 위에 buffers 확인해보면 12개select /*+ gather_plan_statistics */ ename, max(sal) from emp where job = 'SALESMAN' group by ename order by 2 desc fetch first 1 rows only; SELECT * FROM TABLE(dbms_xplan.display_cursor(null,null,'ALLSTATS LAST'));
위코드의 buffers의 갯수는 6개임. 밑 코드가 더 빠르다 !!
문제 372. DALLAS의 부서번호 출력
SELECT DEPTNO FROM DEPT WHERE LOC = 'DALLAS';
문제 373. 달라스의 부서번호에서 근무하는 사원들의 이름과 월급 출력
select ename, sal from emp where DEPTNO = (SELECT DEPTNO FROM DEPT WHERE loc = 'DALLAS');
문제 374. 위 결과를 join으로 츌력
select e.ename, e.sal from emp e, dept d where e.deptno = d.deptno and d.loc = 'DALLAS';
문제 375. king의 사원번호가 mgr 번호인 사원들 출력
select ename from emp where mgr = ( select empno from emp where ename = 'KING' );
서브 쿼리 사용하기 2(다중 행 서브쿼리)
예제. 사원번호가 7788,7902,7369 번인 사원의 사원번호, 사원이름을 출력
select ename, empno from emp where empno in ( 7788,7902,7369 );
예제. 이름이 SCOTT인 사원과 월급이 같은 사원들의 이름, 월급 출력
select ename, sal from emp where sal = ( select sal from emp where ename = 'SCOTT');
- 쿼리 자체를 넣지 않으면 스캇의 월급이 얼만지 구한 후에 WHERE SSAL = 3000;이라고 써줘야함. 번거롭
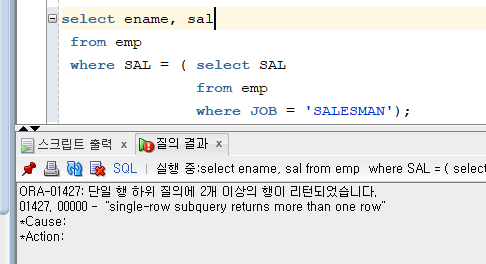
예제. 직업이 SALESMAN 인 사원들과 월급이 같은 사원들의 이름, 월급을 출력
- 위 문제와 똑같이 코딩했는데 에러가 난다. -> 서브쿼리문에서 2개이상의 행이 리턴된 것이다.
직업이 SALESMAN인 사람들의 월급이 하나이상 나왔는데 웨어절에=을 써줘서 에러난것.
->IN써줘야한다
서브쿼리 종류 2가지?
단일행 서브쿼리: 서브쿼리에서 메인쿼리로 하나의 값이 리턴되는 경우
단일행 서브쿼리 연산자 := , >, <, >=, <=, !=, <>, ^=다중행 서브쿼리: 서브쿼리에서 메인쿼리로 여러개의 값이 리턴되는 경우
다중행 서브쿼리 연산자 :in, not in, >all, <all, >any, <any
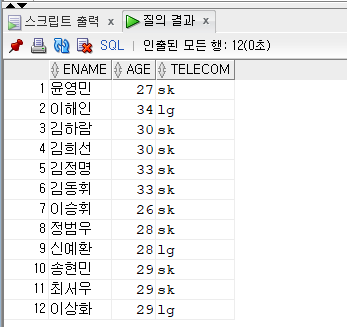
문제 376. 우리반 테이블에서 통신사가 KT인 학생들과 나이가 같은 학생들의 이름, 나이를 출력
select ename, age, telecom from emp17 where age in (select age from emp17 where telecom = 'kt');
문제 377. 위 결과를 다시 출력하는데, 이번에는 통신사가 kt인 학생들과 나이가 같지 않은 학생들의 이름, 나이 출력
select ename, age, telecom from emp17 where age not in (select age // not in !!! from emp17 where telecom = 'kt');
서브 쿼리 사용하기 3(NOT IN)
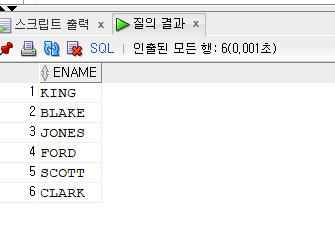
예제. 관리자인 사원들의 이름을 출력하시오
(job이 매니저가 아니라 사원번호가 자기 부하직원들의 mgr 번호인 사원들을 출력 )
select ename from emp where empno in( select mgr // 자신의empno = 다른사람mgr 이면 관리자임 from emp);
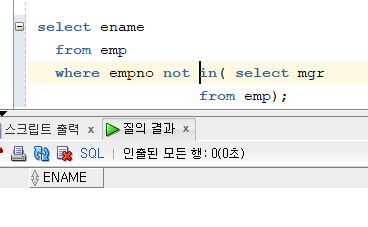
예제. 관리자가 아닌 사원들의 이름 출력 (자기밑에 직속 부하가 없는 일반 사원들)
- 이렇게 not in 쓰면 된다고 생각하지만 이렇게하면 선택된 레코드가 없다고 나온다.
-> mgr중에 null값이 있어서 그렇다.
in이나 =any 는
where empno = 7788 or empno = 7902 or empno = null과 같이 해석이 된다.
null은 알 수 없는 값이라서 true, false 둘다 되지만 or때문에 하나만 true여도 모두 true가 된다.
그래서not in이 아닌in은 잘 나왔던 것.not in 은
where empno != 7788 and empno != 7902 and empno != null로 해석이 된다.
ture and, ture and true 도 되는데 null은 true, false 알 수 없으니까 false를 만났을 때 false로 출력이 되어 null때문에 데이터가 아예 나오지 않았던 것이다.not in null처리!!!!
select ename from emp where empno not in( select mgr from emp where mgr is not null);또는
select ename from emp where empno not in( select nvl(mgr, -1) // null값일때 -1을 출력하게 만든다. from emp);
- null값을 0을 출력하면 혹시 mgr 번호가 0인 사람이 있을 수 있으니, 없을만한거를 넣어준다.
※ 다중행 서브쿼리문 작성시 not in을 사용하면 null때문에 데이터출력이 안될 수 있다. 서브쿼리에 null처리를 잘 해주어 null값이 리턴되지 않도록 하자.
서브쿼리 추가 multiple column subquery
서브쿼리 종류 3가지?
1. single row subquery : 서브쿼리에서 메인쿼리로 하나의 값이 리턴되는 경우
2. multiple row subquery : 서브쿼리에서 메인쿼리로 여러개의 값이 리턴되는 경우
3. multiple column subquery : 서브쿼리에서 메인쿼리로 여러개의 컬럼값이 리턴되는 경우
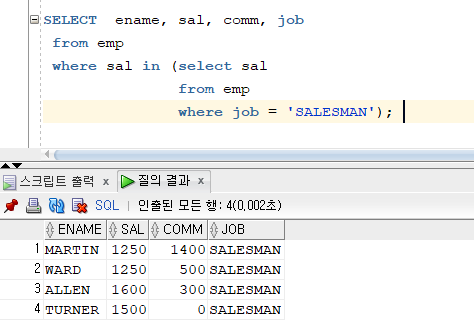
문제 378. 직업이 SALESMAN인 사원들과 월급이 같은 사원들의 이름, 월급, 커미션, 직업 출력
SELECT ename, sal, comm, job from emp where sal in (select sal from emp where job = 'SALESMAN');
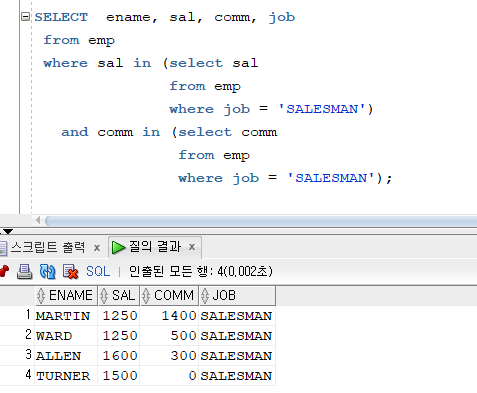
문제 379. 직업이 salesman인 사원들과 월급이 같고, 커미션도 같은 사원들의 이름, 월급, 커미션, 직업 출력
SELECT ename, sal, comm, job from emp where sal in (select sal from emp where job = 'SALESMAN') and comm in (select comm from emp where job = 'SALESMAN');
- 월급도 같고 커미션도 같은 조건이 있으니 and로 이어서 코딩해준다.
-> multiple column subquery !!- 우리가 한 방식은 non pair wise 방식이다.
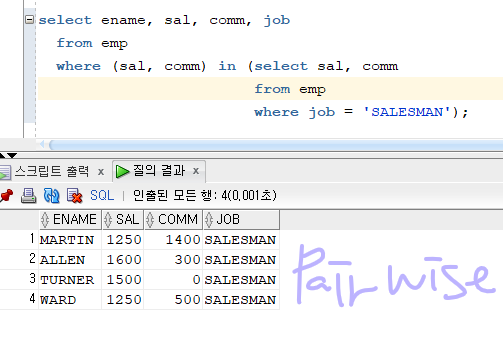
★오라클에만 있는 pair wise 방식 -> mySQL 에서 된다!★
select ename, sal, comm, job
from emp
where (sal, comm) in (select sal, comm
from emp
where job = 'SALESMAN');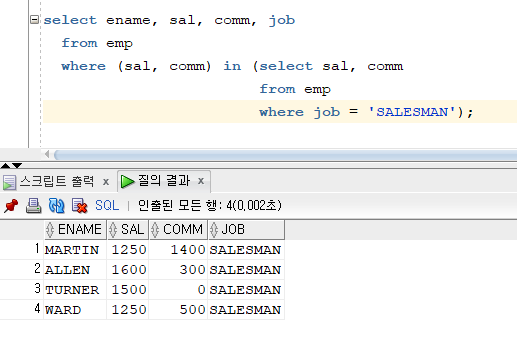
- 위 코드랑 비교해보면 결과는 같지만 코드 길이가 훨씬 짧다.
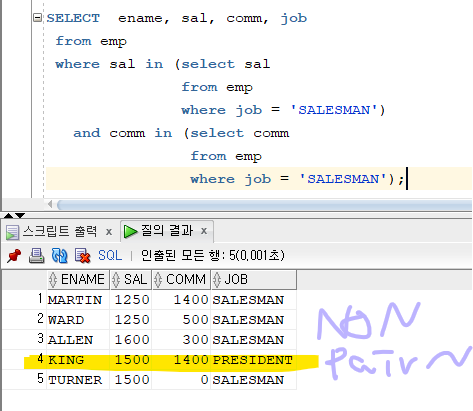
짧은게 중요한게 아니고, 대용량 데이터일 때 결과가 다르게나온다 !!! -> 정렬만 다르다. - 데이터를 검색하는 방법이 서로 다르다!
update emp set sal = 1500 where ename = 'KING'; update emp set comm = 1400 where ename = 'KING'; commit;킹의 데이터를 바꾸고 위 코드 다시 출력해보았을 때, non pairwise 에서만 KING의 데이터가 나온다.
※ pairwise 방식보다 non pairwise방식이 데이터를 더 많이 검색한다.non pariwise vs pair wise sal comm sal comm 1250 1400 1250 1400 1250 500 1250 500 1600 300 1600 300 1500 0 1500 0 1250 300 1250 0 1600 1400 1600 500 1600 0 1500 1400 1500 500 1500 300non pariwise 는 모든 경우의수가 나온다.
문제 380. 최신 mySQL 버전에서는 pairwise 방식이 되는지 확인하기( 됩니다요 )
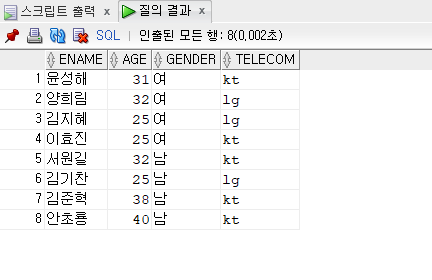
문제 381. 우리반에서 통신사가 kt인 학생들과 나이가 같고, 성별이 같은 학생들의 이름, 나이, 성별, 통신사 출력
non pairwiseselect ename, age, gender, telecom from emp17 where age in (select age from emp17 where telecom = 'kt') and gender in (select gender from emp17 where telecom = 'kt');
pairwiseselect ename, age, gender, telecom from emp17 where (age,gender) in (select age,gender from emp17 where telecom = 'kt');
- 검색 차이가 있으니, 업무에 맞추어 SQL 을 작성해야 한다.
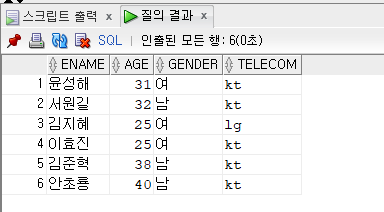
문제 382. 우리반 테이블에서 통신사가 lg인 학생들과 나이가 같은 학생들의 이름, 나이, 통신사 출력
문제 383. (집합 연산자)아래의 SQL을 튜닝하시오!
select deptno, to_char(null)as job, sum(sal) from emp group by deptno union select to_number(null) as deptno , job, sum(sal) from emp group by job;
- 하나는 부서번호별 토탈월급, 하나는 직업별 토탈월급
튜닝후 : select 절 한번만 나오게 하기!!select deptno , job , sum(sal) from emp group by grouping sets((deptno), (job)) order by deptno, job;
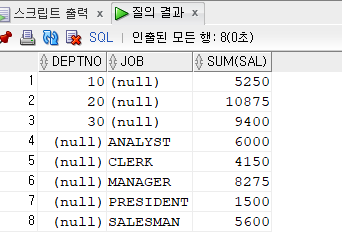
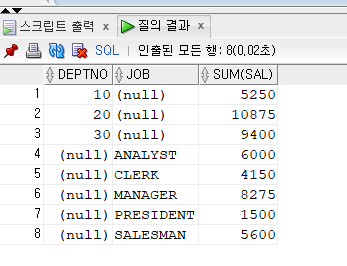
문제 384. 아래의 SQL의 튜닝후 SQL를 작성
튜닝전
select deptno, to_char(null)as job, sum(sal) from emp group by deptno union select to_number(null) as deptno , job, sum(sal) from emp group by job union select null, null, sum(sal) from emp;튜닝후
select deptno , job , sum(sal) from emp group by grouping sets((deptno), (job), ()) order by deptno, job;
문제 385. 아래의 sql의 튜닝 전 sql을 작성하세요 (union을 사용)
튜닝전
select gender, to_char(null) as telecom , round(avg(age)) from emp17 group by gender union select to_char(null) as gender, telecom, round(avg(age)) from emp17 group by telecom union select null, null, round(avg(age)) from emp17;튜닝후
select gender, telecom, avg(age) from emp17 group by grouping sets((gender), (telecom),()); order by gender, telecom;
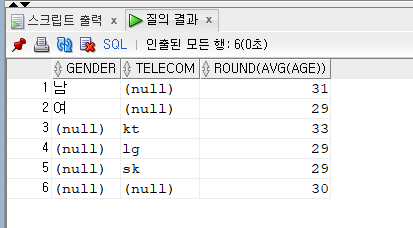
궁금한 것
- 부서번호별 토탈월급을 모두 더한 총합계, 직업별 토탈월급을 모두 더한 총 합계를 뽑고싶음
select deptno, to_char(null) as job, sum(sal) from emp group by deptno union select null, null, sum(sal) from emp union select to_number(null) as deptno, job, sum(sal) from emp group by rollup(job);select deptno, to_char(null) as job, sum(sal) from emp group by rollup(deptno) union select to_number(null) as deptno, job, sum(sal) from emp group by rollup(job);select deptno, to_char(null) as job, sum(sal) from emp group by deptno union select null, null, sum(sal) from emp union select to_number(null) as deptno, job, sum(sal) from emp group by job union select null, null, sum(sal) from emp;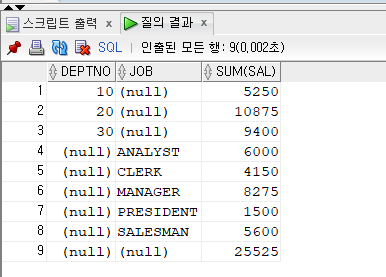
- non pairwise 에서 왜 and연산자 ? mysql, oracle처럼 pairwise 를 못쓴다면, pairwise로 출력하는 데이터값과 동일하게 나오게 하려면 어떻게 ?
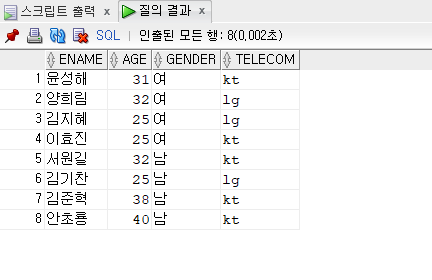
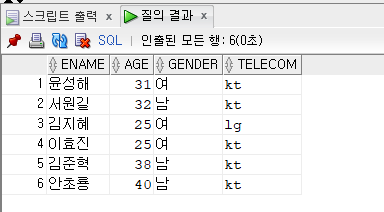
논페어와이즈를 사용해 아래처럼 출력
해결
select deptno, to_char(null) as job, sum(sal) from emp group by rollup(deptno) union all select to_number(null) as deptno, job, sum(sal) from emp group by rollup(job);
- union은 중복되는 데이터를 제거하니까 union all 사용
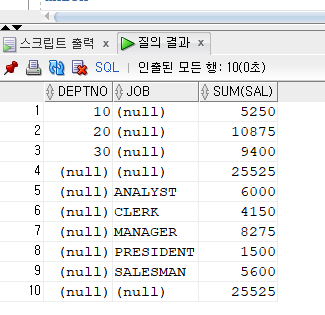
- 그냥 non pairwise 는 저런 앤가봐...
