
복습
학습 --------------------------> 결과 1장. 파이썬 설치
2장. 변수 사용법
3장. if 문과 loop문 ---------> dba 작업 자동화 스크립트 기본골격
4장. 문자열 함수들 ----------> alert log file 분석
5장. 리스트 함수들 ----------> 테이블정의서 엑셀 파일 자동생성
6장. 딕셔너리 함수들
📖 6장 딕셔너리 함수들
딕셔너리(dictionary) ?
키(key)와값(value)형태로 데이터를 저장하는 파이썬 저장 구조
문법:
a = {'마이클 잭슨' : '하루 6시간씩 꾸준히 춤 연습을 했어요',
'김연아' : '공중 세바퀴 회전 1번 실패하면 65번씩 연습했어요',
'박태환' : '하루에 15,000km 이상 수영해야 세계적인 선수들과 겨룰 수 있어요'}
print (type(a) ) # <class 'dict'>딕셔너리 데이터 검색
a['김연아'] # '공중 세바퀴 회전 1번 실패하면 65번씩 연습했어요'
💡 딕셔너리에서 데이터 검색하는 3가지 함수
- 딕셔너리.keys() : key값들을 가져오는 함수
- 딕셔너리.values() : value들을 가져오는 함수
- 딕셔너리.items() : 키, 값을 동시에 가져오는 함수
리스트와 딕셔너리 차이점
➡️ 리스트는 리스트내의 요소에 접근하려면 자리번호를 이용해서 검색해야 합니다. 반면 딕셔너리는 key값을 이용해서 검색합니다. 자리번호 보다는 명확한 키값으로 접근하는게 바람직한 데이터면 처음부터 딕셔너리로 데이터를 구성해야합니다.
ex) emp데이터 프레임에 empno, ename같은 컬럼들은 데이터 저장구조가 딕셔너리로 되어있다.
여기서 empno는 key, 7788, 7902는 값이 된다.
번호가 아닌 컬럼명(key)으로 확실하게 데이터를 검색할 수 있게 해준다.emp_test = { 'empno' : [7788,7902,7369],
'ename' : ['scott', 'allen', 'smith'],
'sal' : [3000,2800,4500] }
emp_test 예제1. emp_test 딕셔너리에서 key empno의 값들을 출력
emp_test['empno']
예제2. empno 에서 7902만 출력하기
emp_test['empno'][1] # 7902예제3. emp_test 딕셔너리에서 key값들만 출력하시오!
1. emp_test.keys() # dict_keys(['empno', 'ename', 'sal'])
2. list(emp_test.keys()) # ['empno', 'ename', 'sal']예제4. emp_test 딕셔너리에서 value들만 출력하시오!
1. emp_test.values()
# dict_values([[7788, 7902, 7369], ['scott', 'allen', 'smith'], [3000, 2800, 4500]])
2. list(emp_test.values())
# [[7788, 7902, 7369], ['scott', 'allen', 'smith'], [3000, 2800, 4500]]
예제5. emp_test 딕셔너리에서 key, values들을 둘다 가져오시오
1. emp_test.items()
# dict_items([('empno', [7788, 7902, 7369]), ('ename', ['scott', 'allen', 'smith']), ('sal', [3000, 2800, 4500])])
2. list(emp_test.items())
# [('empno', [7788, 7902, 7369]),
# ('ename', ['scott', 'allen', 'smith']),
# ('sal', [3000, 2800, 4500])]문제 83. 아래의 딕셔너리를 생성하고, key값들만 가져오기
salary = {'초급' : ['500만원~600만원', '0~3년'], '중급' : ['600만원~700만원','3~6년'], '고급' : ['700~900만원','6~9년'], '특급' : ['900만원~1000만원','9~12년']} list(salary.keys()) #loop문으로 출력하기 for i in salary.keys(): # 루프문으로 가져올 수 있다. print(i, end=',') # 가로로 출력하면 end써주고 세로면 i만 쓰기

문제 84. salary 딕셔너리에서 단가만 가져오기
salary = {'초급' : ['500만원~600만원', '0~3년'], '중급' : ['600만원~700만원','3~6년'], '고급' : ['700~900만원','6~9년'], '특급' : ['900만원~1000만원','9~12년']} for i in salary.values(): print(i[0])
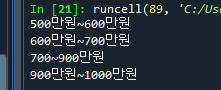
문제 85. salary 딕셔너리에서 아래와 같이 데이터를 검색하시오
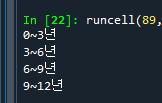
salary = {'초급' : ['500만원~600만원', '0~3년'], '중급' : ['600만원~700만원','3~6년'], '고급' : ['700~900만원','6~9년'], '특급' : ['900만원~1000만원','9~12년']} for i in salary.values(): print(i[1])
딕셔너리에 값 추가하기
⭐ <문법>
- 값들이 리스트인 딕셔너리를 생성
artist = {'아이유' : ['너랑나', '마시멜로우'], '마이클잭슨' : ['beat it','smoth criminal']} artist
- 아이유에 곡 추가하기
artist['아이유'].append('가을아침')
문제 86. 아래의 아이유 노래들을 전부 아이유 키의 값으로 추가하기 (extend사용)
music1 = ['에잇','celebrity','라일락'] artist['아이유'].extend(music1)
⭐ <문법> 값이 하난인 딕셔너리에 값 추가하기
1. 값이 하나인 딕셔너리 생성
artist2 = {'아이유':'너랑나', '마이클 잭슨': 'beat it'}2. 비틀즈를 artist2에 추가하기
artist2['비틀즈'] = 'yesterday' artist2 # {'아이유': '너랑나', '마이클 잭슨': 'beat it', '비틀즈': 'yesterday'}3. 아래의 2개의 리스트를 가지고 artist3이라는 딕셔너리를 생성하기 (zip사용)
a = ['아이유','마이클잭슨','비틀즈'] b = ['너랑나','beat it', 'yesterday'] artist3 = {} # 빈 딕셔너리 만들어주기 -> key값이 하나밖에 없을 때 만드는 방법 for i , k in zip (a,b): artist3[i] = k artist3 # {'아이유': '너랑나', '마이클잭슨': 'beat it', '비틀즈': 'yesterday'}

문제 87. 아래의 두개의 리스트를 이용해서 emp_test2 라는 딕셔너리를 생성하시오
a = ['empno', 'empno','empno','ename','ename','ename']
b = [7788,7902,7369,'scott','allen','smith']
결과
print (emp_test2)
{'empno' : [7788,7902,7369], 'ename':['scott','allen','smith'] }
a = ['empno', 'empno','empno','ename','ename','ename'] b = [7788,7902,7369,'scott','allen','smith'] emp_test2 = {'empno': [], 'ename':[]} for i,k in zip(a,b): emp_test2[i].append(k) emp_test2

딕셔너리의 값 삭제하기
⭐ <문법>
emp_test2 = {'empno': [7788, 7902, 7369], 'ename': ['scott', 'allen', 'smith']} emp_test21. emp_test2의 7902 지우기
del emp_test2['empno'] [1] emp_test2
2. 모든 요소 지우기
emp_test2.clear() emp_test2 # 모두 잘 지워짐!

✍🏻 정리해보기
💡 딕셔너리에서 값 검색하는 함수 3가지
딕셔너리.keys() : key값들을 가져오는 함수
딕셔너리.values() : value들을 가져오는 함수
딕셔너리.items() : 키, 값을 동시에 가져오는 함수
💡 딕셔너리에 값 추가하기
- 딕셔너리['키'].append('값')
# 값이 하나가 아닐때- 딕셔너리['키'] = '값'
# 값이 하나일때
💡 딕셔너리 값 지우기
- del 딕셔너리 ['키'][인덱스]
- 딕셔너리.clear()
딕셔너리로 dba 작업을 편하게 하는 스크립트 작성
1. emp_test 딕셔너리를 가지고 emp_df라는 데이터 프레임을 생성합니다.
emp_test2 = {'empno': [7788, 7902, 7369], 'ename': ['scott', 'allen', 'smith']}
import pandas as pd
emp_df = pd.DataFrame(emp_test2)
emp_df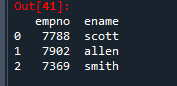
✅ 오라클의 테이블을 파이썬에서 만들어주겠다.
2. emp_test3딕셔너리를 가지고 emp_df3라는 데이터 프레임을 생성합니다.
emp_test3 = {'empno': [7788, 7902, 7369], 'ename': ['scott', 'allen', 'smith'],
'sal' : [3000,4500,2400] }
import pandas as pd
emp_df3 = pd.DataFrame(emp_test3)
emp_df3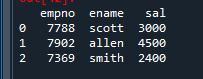
문제 88. emp_df3 데이터 프레임에서 ename이 scott인 사원의 이름과 sal을 출력
문법
emp_df3[컬럼리스트][검색조건]
emp_df3[['ename','sal']][emp_df['ename']=='scott']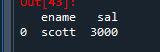
3. 리스트를 가지고 데이터 프레임 생성 vs 딕셔너리로 데이터 프레임 생성
✔️ 3-1. 리스트를 가지고 판다스 데이터 프레임 만들었을 때
row1 = [(7788,'smith',3000),(7566,'scott',4500),(7839,'allen', 1800)]
emp_list = pd.DataFrame(row1)
emp_list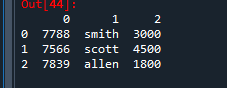
✅ 결과가 리스트의 자리명으로 컬럼명이 구성된다.
✔️ 3-2. 딕셔너리를 가지고 판다스 데이터 프레임을 만들었을 때
emp_test3 = {'empno': [7788, 7902, 7369], 'ename': ['scott', 'allen', 'smith'],
'sal' : [ 3000, 4500, 2400 ] }
import pandas as pd
emp_dict = pd.DataFrame( emp_test3 )
emp_dict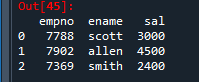
✅ 딕셔너리의 key값이 컬럼명이 된다.
4. 리스트로 데이터 프레임을 구성했을 때 컬럼명 달아주는 작업
-> 리스트로 만들어야 한다면 자리번호로 컬럼명이 나오지 않도록 아래처럼 코딩해주기
row1 = [(7788,'smith',3000),(7566,'scott',4500),(7839,'allen', 1800)]
col = ['empno','ename','sal'] # col리스트 생성
emp_list = pd.DataFrame(row1, columns=col)
emp_list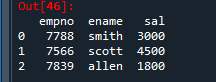
💡리스트 자리번호 대신에 컬럼명을 부여하기 위해 columns라는 옵션을 사용 !
- 오라클, 파이썬을 연동해서 오라클의 emp 테이블의 데이터를 출력
import cx_Oracle
import pandas as pd
from openpyxl import load_workbook, Workbook
from openpyxl.styles import PatternFill
dsn = cx_Oracle.makedsn('localhost', 1521, 'xe')
db = cx_Oracle.connect('c##scott', 'tiger', dsn)
cursor = db.cursor() # 오라클, 파이썬을 연동해서 cursor라는 메모리를 생성
cursor.execute(""" select * from emp """) # cursor메모리에 select 문장의 결과를 올림
row = cursor.fetchall() # cursor메모리에 올린 데이터를 전부 fetch해서 row변수에 담고
row # 출력!
- 오라클 데이터베이스에서 emp 테이블의 컬럼명들을 가져오시오
colname = cursor.description
colnames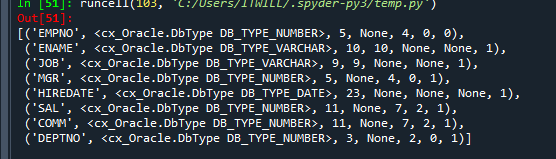
- 위 결과에서 컬럼명들만
for i in colnames: print(i[0])
- 위 결과를 소문자로
for i in colnames: print(i[0].lower())
- 위에서 출력되는 결과를 col이라는 리스트에 append시키기
col = [] for i in colnames: col.append(i[0].lower()) col # ['empno', 'ename', 'job', 'mgr', 'hiredate', 'sal', 'comm', 'deptno'] - emp 데이터 프레임의 컬럼명으로 위의 col리스트의 컬럼명 붙이기
import cx_Oracle
import pandas as pd
dsn = cx_Oracle.makedsn('localhost', 1521, 'xe')
db = cx_Oracle.connect('c##scott', 'tiger', dsn)
cursor = db.cursor() # 오라클과 파이썬을 연동하여 cursor 라는 메모리를 생성
cursor.execute(""" select * from emp """) # cursor 메모리에 select 문의 결과를 올림
row = cursor.fetchall() # cursor 메모리에 올린 데이터를 전부 fetch 해서 row
colnames = cursor.description
col = [ ]
for i in colnames:
col.append( i[0].lower() )
emp = pd.DataFrame(row , columns = col )
emp 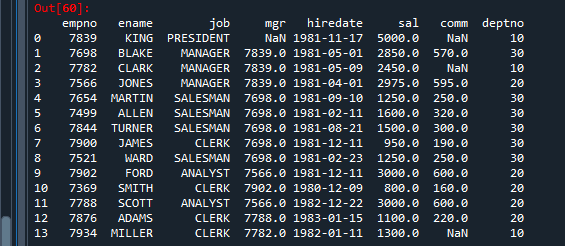
문제 89. 위 스크립트를 수정해서 오라클 데이터베이스의 dept테이블을 dept데이터 프레임으로 생성하시오
import cx_Oracle import pandas as pd dsn = cx_Oracle.makedsn('localhost', 1521, 'xe') db = cx_Oracle.connect('c##scott', 'tiger', dsn) cursor = db.cursor() cursor.execute(""" select * from dept """) row = cursor.fetchall() colnames = cursor.description col = [ ] for i in colnames: col.append( i[0].lower() ) dept = pd.DataFrame(row , columns = col ) dept
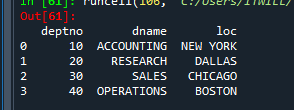
✅ 위 스크립트를 함수로 생성해서 오라클 db에 있는 어느 테이블이든 편하게 불러올 수 있도록 7장에서 나오는 함수를 배워보겠습니다.
salgrade = oracle_table('salgrade')
salgrade📖 7장 함수
함수가 왜 필요할까?
어떤 기능을 수행하기 위한 긴 코드를 사용하기 편하도록 함수로 생성을 합니다.
data ---------------> 함수 --------------> 결과
함수를 사용하지 않는 코드 vs 함수를 사용하는 코드
200줄 코드 1줄짜리 함수호출 코드
다른코드 다른코드
200줄 코드 1줄짜리 함수호출 코드
다른코드 다른코드
200줄 코드 1줄짜리 함수호출 코드<문법>
1. 구구단 2단을 while loop문으로 구현
a = 1
shile a < 10:
print ('2x',a,'=',2*a)
a = a + 1- 구구단 3단을 while loop 문으로 구현합니다.
a = 1
shile a < 10:
print (3x',a,'=',3*a)
a = a + 1- 단을 입력하면 해당 단의 구구단이 출력되는 함수를 생성하시오
def gugu(dan):
a = 1
while a < 10:
print (dan,'x',a,'=',dan*a)
a = a + 1
gugu(5) 문제 90. 위에서 만든 gugu함수를 이용해서 구구단 2단부터 9단까지 출력
def gugu(dan): a = 1 while a < 10: print (dan,'x',a,'=',dan*a) a = a + 1 for i in range(2, 10): gugu(i)✅ 함수로 만들어놓게 되면 코드가 심플해지면서 코드 작성하는것이 쉬워진다.
문제 91. 양수값을 넣어서 실행하던 음수값을 넣어서 실행하던 무조건 양수값이 나오는 my_abss함수를 생성하기
def my_abs(num): if num < 0: print(num * -1) else: print(num) my_abs(-4)
문제 92. 숫자 1을 넣으면 앞면이 출력되고, 숫자 0을 넣으면 뒷면이 출력되는 함수를 생성하기
def coin(x): if x == 1 : print('앞면') elif x == 0 : print('뒷면') coin(1)
f 스트링 사용법
문자열 안에 변수를 사용할 수 있게 해주는 파이썬의 강력한 기능 !
f"문자열{변수}"
name = "Alice"
age = 30
greeting = f"안녕하세요, 제 이름은 {name}이고, 나이는 {age}살입니다."
print(greeting)문제 93. 아래와 같이 테이블명을 넣고 실행하면 오라클 데이터베이스에서 해당 테이블의 결과를 가져올 수 있게 하는 oracle_table함수를 생성하시오
def oracle_table(table_name):
import cx_Oracle
import pandas as pd
dsn = cx_Oracle.makedsn('localhost', 1521, 'xe')
db = cx_Oracle.connect('c##scott', 'tiger', dsn)
cursor = db.cursor() # 오라클과 파이썬을 연동하여 cursor 라는 메모리를 생성
query = f"SELECT * FROM {table_name}"
cursor.execute(query ) # cursor 메모리에 select 문의 결과를 올림
row = cursor.fetchall() # cursor 메모리에 올린 데이터를 전부 fetch 해서 row
colnames = cursor.description
col = [ ]
for i in colnames:
col.append( i[0].lower() )
df = pd.DataFrame(row , columns = col )
print(df)
-------------------------------------------------------------------
oracle_table('salgrade') 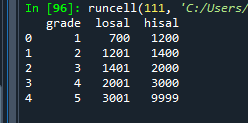
✅ 지금은 dept테이블만 나오는데, 우리는 괄호안 테이블 명을 넣으면 그 테이블이 출력되게 하고싶다.
print 말고 return으로 한 스크립트
def oracle_table(table_name):
import cx_Oracle
import pandas as pd
dsn = cx_Oracle.makedsn('localhost', 1521, 'xe')
db = cx_Oracle.connect('c##scott', 'tiger', dsn)
cursor = db.cursor() # 오라클과 파이썬을 연동하여 cursor 라는 메모리를 생성
query = f"SELECT * FROM {table_name}"
cursor.execute(query ) # cursor 메모리에 select 문의 결과를 올림
row = cursor.fetchall() # cursor 메모리에 올린 데이터를 전부 fetch 해서 row
colnames = cursor.description
col = [ ]
for i in colnames:
col.append( i[0].lower() )
df = pd.DataFrame(row , columns = col )
return df
#%%
emp = oracle_table('emp')
#%%
emp함수 생성시 언제 return을 쓰고 언제 print를 사용하는가? (p.183)
-
함수를 실행할 때 그냥 데이터를 출력하기만 원한다면 함수 생성시
print를 사용하면 된다. 그런데 함수의 실행 결과를 별도의 변수에 담아내고 싶다면, 함수 생성시return절을 사용하면 된다. -
함수 생성시 반복문의 결과를 화면에 출력할 때는
print를 사용해야합니다. return 을 사용하게 되면 1번만 수행되고 맙니다.
예제1. 아래의 gugu 함수를 실행하시오
def gugu(dan):
a = 1
while a < 10:
print (dan,'x',a,'=',dan*a)
a = a + 1
gugu(5) 예제2. return절로 만든 아래의 gugu 함수를 실행하시오
def gugu(dan):
a = 1
while a < 10:
return (dan,'x',a,'=',dan*a)
a = a + 1
gugu(5) 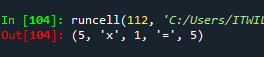
✅ return절이 한번 수행돠면 바로 종료가된다.
내가 자주 사용하는 스크립트 모듈화 하기
- 나의 워킹 디렉토리가 어딘지 확인합니다.

- oracle_table 함수 코드를 auto.py라는 이름으로 저장하기(내 워킹디렉토리에)
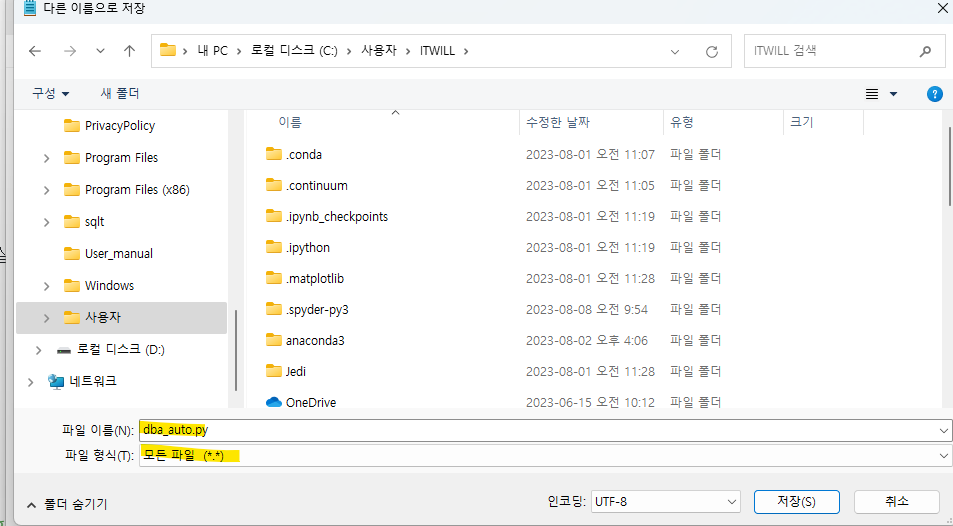
- 함수 호출 방법
import dba_auto as a # dba_auto.py의 스크립트를 그대로 불러오겠다. 이 모듈이름의 별칭은 a이다.
emp = a.oracle_table(emp) # a모듈의 oracle_table함수를 실행해라!
---------------------------------------------------------------------
emp문제 94. dba 자동화 스크립트를 함수로 생성 easy_dba
# dba자동화 스크립트
def easy_dba():
while True:
print( """ === dba 작업을 편하게 수행하기 위한 스크립트 총모음 ====
0. 프로그램을 종료하려면 0번을 누르세요.
1. 테이블 스페이스 사용량을 확인하려면 1번을 누르세요
2. 현재 데이터베이스 락(lock) 발생했는지 확인하려면 2번을 누르세요
3. 오라클와 연동하게 싶으면 3번을 누르세요
4. alert log file 을 분석하고 싶다면 4번을 누르세요
""")
num = int( input('원하는 번호를 입력하세요 ~' ) )
if num == 0:
break
elif num == 1:
import cx_Oracle
import pandas as pd
dsn = cx_Oracle.makedsn( 'localhost' , 1521, 'xe')
db = cx_Oracle.connect('c##scott','tiger', dsn)
cursor = db.cursor()
cursor.execute(""" select t.tablespace_name,
round(((t.total_size - f.free_size) / t.total_size),2) * 100 usedspace
from (select tablespace_name, sum(bytes)/1024/1024 total_size
from dba_data_files
group by tablespace_name) t,
(select tablespace_name, sum(bytes)/1024/1024 free_size
from dba_free_space
group by tablespace_name) f
where t.tablespace_name = f.tablespace_name(+) """)
row = cursor.fetchall()
col=[]
for i in colname:
col.append( i[0].lower() )
df = pd.DataFrame (list(row), columns=col)
print(df)
break
elif num == 2:
continue
elif num ==3:
import cx_Oracle # 오라클과 파이썬을 연동하기 위한 모듈
import pandas as pd
dsn = cx_Oracle.makedsn( 'localhost' , 1521, 'xe')
db = cx_Oracle.connect('c##scott','tiger', dsn)
cursor = db.cursor()
cursor.execute(""" select * from emp """)
row = cursor.fetchall()
colname = cursor.description
col=[]
for i in colname:
col.append( i[0].lower() )
emp = pd.DataFrame (list(row), columns=col)
print(' 잘 연동되었습니다')
break
elif num==4:
jobs = open("C:\\app\\YYS\\product\\18.0.0\\diag\\rdbms\\xe\\xe\\trace\\alert_xe.log", encoding='cp949', errors='ignore')
data = jobs.read()
data2= data.split()
k = [ ]
for i in data2:
if 'ora-' in i.lower():
k.append(i)
import pandas as pd
df = pd.DataFrame( k, columns=['col1'] )
from pandasql import sqldf
pysqldf = lambda q : sqldf( q, globals() )
q = """ select col1, count(*)
from df
group by col1
order by 2 desc; """
print(pysqldf(q) )
break- 호출하기!
import dba_auto as a
a.easy_dba()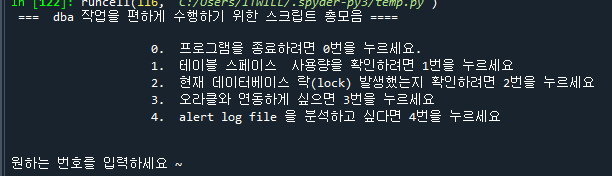
✅ 함수 만들 때 값을 입력받아야 한다면 입력 매개변수를 함수 안에 넣고, 그게 아니라면 그냥 () 이렇게 비워놓는다.

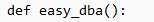
7장에서 배운 함수 문법을 이용해서 dba작업 편하게 하는 스크립트 생성하기
- 오라클 db의 emp 테이블의 테이블 정의서를 쿼리문으로 출력하기
SELECT A.COLUMN_ID AS NO
, B.COMMENTS AS "논리명"
, A.COLUMN_NAME AS "물리명"
, A.DATA_TYPE AS "자료 형태"
, A.DATA_LENGTH AS "길이"
, DECODE(A.NULLABLE, 'N', 'No', 'Y', 'Yes') AS "Null 허용"
, A.DATA_DEFAULT AS "기본값"
, B.COMMENTS AS "코멘트"
FROM ALL_TAB_COLUMNS A
LEFT JOIN ALL_COL_COMMENTS B
ON A.OWNER = B.OWNER
AND A.TABLE_NAME = B.TABLE_NAME
AND A.COLUMN_NAME = B.COLUMN_NAME
WHERE A.TABLE_NAME = 'EMP' AND A.OWNER='C##SCOTT'
ORDER BY A.COLUMN_ID;- oracle_table함수의 코드를 가져다가 테이블명을 넣고 실행하면 테이블 정의서 결과가 출력되게 하는 함수 table_def('emp')를 생성하시오
def table_def(table_name):
import cx_Oracle
import pandas as pd
dsn = cx_Oracle.makedsn('localhost', 1521, 'xe')
db = cx_Oracle.connect('c##scott', 'tiger', dsn)
cursor = db.cursor()
query = f"""SELECT A.COLUMN_ID AS NO
, B.COMMENTS AS "논리명"
, A.COLUMN_NAME AS "물리명"
, A.DATA_TYPE AS "자료 형태"
, A.DATA_LENGTH AS "길이"
, DECODE(A.NULLABLE, 'N', 'No', 'Y', 'Yes') AS "Null 허용"
, A.DATA_DEFAULT AS "기본값"
, B.COMMENTS AS "코멘트"
FROM ALL_TAB_COLUMNS A
LEFT JOIN ALL_COL_COMMENTS B
ON A.OWNER = B.OWNER
AND A.TABLE_NAME = B.TABLE_NAME
AND A.COLUMN_NAME = B.COLUMN_NAME
WHERE A.TABLE_NAME = '{table_name}' AND A.OWNER='C##SCOTT'
ORDER BY A.COLUMN_ID"""
cursor.execute(query)
row = cursor.fetchall()
colnames = cursor.description
col = []
for i in colnames:
col.append(i[0].lower())
df = pd.DataFrame(row, columns=col)
return df
def table_def(table_name):
import cx_Oracle
import pandas as pd
dsn = cx_Oracle.makedsn('localhost', 1521, 'xe')
db = cx_Oracle.connect('c##scott', 'tiger', dsn)
cursor = db.cursor()
query = f"""SELECT A.COLUMN_ID AS NO
, B.COMMENTS AS "논리명"
, A.COLUMN_NAME AS "물리명"
, A.DATA_TYPE AS "자료 형태"
, A.DATA_LENGTH AS "길이"
, DECODE(A.NULLABLE, 'N', 'No', 'Y', 'Yes') AS "Null 허용"
, A.DATA_DEFAULT AS "기본값"
, B.COMMENTS AS "코멘트"
FROM ALL_TAB_COLUMNS A
LEFT JOIN ALL_COL_COMMENTS B
ON A.OWNER = B.OWNER
AND A.TABLE_NAME = B.TABLE_NAME
AND A.COLUMN_NAME = B.COLUMN_NAME
WHERE A.TABLE_NAME = '{table_name}' AND A.OWNER='C##SCOTT'
ORDER BY A.COLUMN_ID"""
cursor.execute(query)
row = cursor.fetchall()
colnames = cursor.description
col = []
for i in colnames:
col.append(i[0].lower())
df = pd.DataFrame(row, columns=col)
return df
#%%
emp = table_def('EMP')
emp- 위의 판다스 데이터 프레임의 결과를 excel파일로 생성(aaa2는 c드라이브 밑에있음)
emp = table_def('EMP')
emp.to_excel("C:\\aaa2\\emp_df.xlsx")- 어제 마지막 문제 코드
import cx_Oracle
import pandas as pd
dsn = cx_Oracle.makedsn( 'localhost' , 1521, 'xe')
db = cx_Oracle.connect('c##scott','tiger', dsn)
cursor = db.cursor()
#나의 오라클 디비에 있는 테이블명 리스트를 CURSOR라는 메모리에 올린것이다!
cursor.execute(""" select table_name
from dba_tables
where owner in ('C##SCOTT', 'HR', 'SH', 'OE')
and table_name not like 'DR%'
""")
#커서에 있는 데이터를 불러와서 row변수에 담아냄.
row = cursor.fetchall()
len(row)
table_list = []
for i in row:
table_list.append(i[0])
table_list.sort()
print(table_list)- 어제 마지막 문제로 만든 table_list에서 테이블명을 하나씩 for loop문으로 출력
for i in table_list:
print(i)- 아래의 3개의 테이블만 엑셀파일로 생성
table_list = ['EMP', 'DEPT', 'SALGRADE'] # 예시: 처리하고자 하는 테이블 이름 리스트
for table_name in table_list:
df = table_def(table_name)
output_path = f"c:\\aaa2\\{table_name}_df.xlsx" # 예시: 테이블 이름에 따라 파일 경로 설정
df.to_excel(output_path)
print("Excel 파일 생성이 완료되었습니다.")- [마지막 문제] 어제 마지막 문제로 출력한 테이블 리스트로 전부 테이블 정의서를 엑셀 파일로 생성하시오
import cx_Oracle
import pandas as pd
dsn = cx_Oracle.makedsn( 'localhost' , 1521, 'xe')
db = cx_Oracle.connect('c##scott','tiger', dsn)
cursor = db.cursor()
#나의 오라클 디비에 있는 테이블명 리스트를 CURSOR라는 메모리에 올린것이다!
cursor.execute(""" select table_name
from dba_tables
where owner in ('C##SCOTT', 'HR', 'SH', 'OE')
and table_name not like 'DR%'
""")
#커서에 있는 데이터를 불러와서 row변수에 담아냄.
row = cursor.fetchall()
table_list = []
for i in row:
table_list.append(i[0])
table_list.sort()
for table_name in table_list:
df = table_def(table_name)
# output_path = f"c:\\aaa2\\{table_name}_df.xlsx"
# df.to_excel(output_path)
df.to_excel(f"C:\\aaa2\\{table_name}.xlsx")
print("Excel 파일 생성이 완료되었습니다.") 
큰 도움이 되었습니다, 감사합니다.