복습
파이썬 설치
파이썬의 변수 생성시 주의사항
파이썬의 자료형 5가지
- 문자형
- 숫자형
- 리스트형
- 튜플형
- 사전형파이썬에서의 if 문
파이썬에서의 loop문 : 1. while loop : '조건' 으로 반복시키는 루프문
2. for loop : '범위' 로 반복시키는 루프문
✅ while loop문은 무한루프문을 구현할 때 유용한 loop문
✅ loop문과 짝꿍인 옵션들 2가지 ->1. continue2. break
예제 22. 루프문과 짝꿍인 옵션인 continew와 break
continue 예제
for i in range(1, 10):
if i == 4:
continue # 반복문에서 특정 조건에 해당하는 부분을 실행하지 않겠다.
print(i) 문제 51. 숫자 1 ~ 50까지 출력하는데 홀수는 출력하지 말고 짝수만 출력하기
for i in range(1, 51): if i % 2 != 0: continue print(i)
break 예제 ➡️ loop문 자체를 종료시켜버린다.
for i in range(1, 10):
if i == 8:
break
print(i) 
while loop에서 break문 예제
x = 1
while x < 11 loop:
if x == 8:
break # 7까지만 출력된다.
print(x)
x = x + 1예제. dba 작업을 편하게 수행하기 위한 스크립트를 실행하기 위해 다음과 같이 기본 코드 골격을 작성하시오!
print ( """ ======= dba작업을 편하게 수행하기 위한 스크립트 총 모음 =======
1. 테이블 스페이스 사용량을 확인하려면 1번을 누르세요.
2. 현재 데이터베이스에 락(lock)이 발생했는지 확인하려면 2번을 누르세요. """)
num = int(input('원하는 번호를 입력하세요.')) 예제. 위 스크립트에 while loop문을 넣어서 무한루프 돌게 해보기
while True: # 이거쓰면 무한루프 돈다.
print ( """ ======= dba작업을 편하게 수행하기 위한 스크립트 총 모음 =======
1. 테이블 스페이스 사용량을 확인하려면 1번을 누르세요.
2. 현재 데이터베이스에 락(lock)이 발생했는지 확인하려면 2번을 누르세요. """)
num = int(input('원하는 번호를 입력하세요.')) 문제 52. 위 스크립트에 0 을 넣고 프로그램을 종료하려면 0 번을 누르세요 라고 하고 무한루프 종료되게 하기
while True: # 이거쓰면 무한루프 돈다. if num == 0: break print ( """ ======= dba작업을 편하게 수행하기 위한 스크립트 총 모음 ======= 0. 프로그램 종료는 0번을 누르세요. 1. 테이블 스페이스 사용량을 확인하려면 1번을 누르세요. 2. 현재 데이터베이스에 락(lock)이 발생했는지 확인하려면 2번을 누르세요. """) num = int(input('원하는 번호를 입력하세요.'))
문제 53. 위 스크립트에 오라클과 연동하려면 3번을 누르세요. 라는 번호를 추가하시오!
while True: print( """ === dba 작업을 편하게 수행하기 위한 스크립트 총모음 ==== 0. 프로그램을 종료하려면 0번을 누르세요. 1. 테이블 스페이스 사용량을 확인하려면 1번을 누르세요 2. 현재 데이터베이스 락(lock) 발생했는지 확인하려면 2번을 누르세요 3. 오라클와 연동하게 싶으면 3번을 누르세요 """) num = int( input('원하는 번호를 입력하세요 ~' ) ) if num == 0: break elif num == 1: continue elif num == 2: continue elif num ==3: import cx_Oracle # 오라클과 파이썬을 연동하기 위한 모듈 import pandas as pd dsn = cx_Oracle.makedsn( 'localhost' , 1521, 'xe') db = cx_Oracle.connect('c##scott','tiger', dsn) cursor = db.cursor() cursor.execute(""" select * from emp """) row = cursor.fetchall() colname = cursor.description col=[] for i in colname: col.append( i[0].lower() ) emp = pd.DataFrame (list(row), columns=col) print(' 잘 연동되었습니다') break
예제 23. pandasql 모듈을 사용하여 oracle 테이블의 데이터를 SQL로 조회하기
예제1. 아나콘다 프롬프트를 열고 pip install로 pandasql을 설치합니다.
pip install pandasql예제2. 주피터 노트북에서 emp 데이터 프레임이 잘 보이는지 확인
예제3. 아래 스크립트 수행
from pandasql import sqldf # 파이썬에서 sql을 사용할 수 있게 해주는 모듈
pysqldf = lambda q : sqldf( q, globals() )
q = """ select job, count(*) as 건수
from emp
group by job
order by 2 desc; """
pysqldf(q)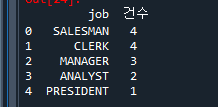
✅ lambda 는 한줄짜리 함수 생성. q는 입력 매개변수. sqldf 함수안에 들어가서 q안에 있는 sql들을 실행시킨다. globals()는 포스트 화면에 출력할 수 있게 해주는 애.
✅ sqldf 함수에 SQL을 입력하면 해당 SQL을 실행해서 EMP판다스 데이터 프레임에서 SQL에 해당하는 데이터를 조회할 수 있게 해준다. SQL로 오라클과 연동해서 구성한 판다스 데이터 프레임의 데이터를 조회해줄 수 있게 하는 함수가 sqldf 함수입니다.
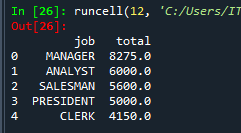
문제 54. 파이썬에서 직업, 직업별 토탈 월급을 출력하는데 토탈월급이 높은 것 부터 출력
from pandasql import sqldf pysqldf = lambda q : sqldf( q, globals() ) q = """ select job, sum(sal) as total from emp group by job order by 2 desc; """ pysqldf(q)
문제 55. sqldeveloper에서 테이블 스페이스 사용량을 조회하는 쿼리를 수행
select t.tablespace_name,
round(((t.total_size - f.free_size) / t.total_size),2) * 100 usedspace
from (select tablespace_name, sum(bytes)/1024/1024 total_size
from dba_data_files
group by tablespace_name) t,
(select tablespace_name, sum(bytes)/1024/1024 free_size
from dba_free_space
group by tablespace_name) f
where t.tablespace_name = f.tablespace_name(+);
select * from table(dbms_xplan.display); 문제 56. 파이썬에서 테이블 스페이스 사용량을 조회하는 쿼리의 결과를 출력
import cx_Oracle
import pandas as pd
dsn = cx_Oracle.makedsn( 'localhost' , 1521, 'xe')
db = cx_Oracle.connect('c##scott','tiger', dsn)
cursor = db.cursor()
cursor.execute(""" select t.tablespace_name,
round(((t.total_size - f.free_size) / t.total_size),2) * 100 usedspace
from (select tablespace_name, sum(bytes)/1024/1024 total_size
from dba_data_files
group by tablespace_name) t,
(select tablespace_name, sum(bytes)/1024/1024 free_size
from dba_free_space
group by tablespace_name) f
where t.tablespace_name = f.tablespace_name(+) """)
colname = cursor.description
col=[]
for i in colname:
col.append( i[0].lower() )
df = pd.DataFrame (list(row), columns=col)
df
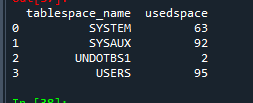
✅ pandasql모듈이 from절의 서브쿼리를 지원하지 않기때문에 바로 오라클 db에서 연동해서 결과를 가져옴
문제 57. 위 코드를 dba자동화 코드 1번에 추가하기
while True:
print( """ === dba 작업을 편하게 수행하기 위한 스크립트 총모음 ====
0. 프로그램을 종료하려면 0번을 누르세요.
1. 테이블 스페이스 사용량을 확인하려면 1번을 누르세요
2. 현재 데이터베이스 락(lock) 발생했는지 확인하려면 2번을 누르세요
3. 오라클와 연동하게 싶으면 3번을 누르세요
""")
num = int( input('원하는 번호를 입력하세요 ~' ) )
if num == 0:
break
elif num == 1:
import cx_Oracle
import pandas as pd
dsn = cx_Oracle.makedsn( 'localhost' , 1521, 'xe')
db = cx_Oracle.connect('c##scott','tiger', dsn)
cursor = db.cursor()
cursor.execute(""" select t.tablespace_name,
round(((t.total_size - f.free_size) / t.total_size),2) * 100 usedspace
from (select tablespace_name, sum(bytes)/1024/1024 total_size
from dba_data_files
group by tablespace_name) t,
(select tablespace_name, sum(bytes)/1024/1024 free_size
from dba_free_space
group by tablespace_name) f
where t.tablespace_name = f.tablespace_name(+) """)
row = cursor.fetchall()
df =pd.DataFrame(row)
print(df)
break
elif num == 2:
continue
elif num ==3:
import cx_Oracle # 오라클과 파이썬을 연동하기 위한 모듈
import pandas as pd
dsn = cx_Oracle.makedsn( 'localhost' , 1521, 'xe')
db = cx_Oracle.connect('c##scott','tiger', dsn)
cursor = db.cursor()
cursor.execute(""" select * from emp """)
row = cursor.fetchall()
colname = cursor.description
col=[]
for i in colname:
col.append( i[0].lower() )
emp = pd.DataFrame (list(row), columns=col)
print(' 잘 연동되었습니다')
break 예제 24. 문자열 슬라이싱 하기
문자열을 잘라내는 기법을 문자열 슬라이싱이라고 합니다.
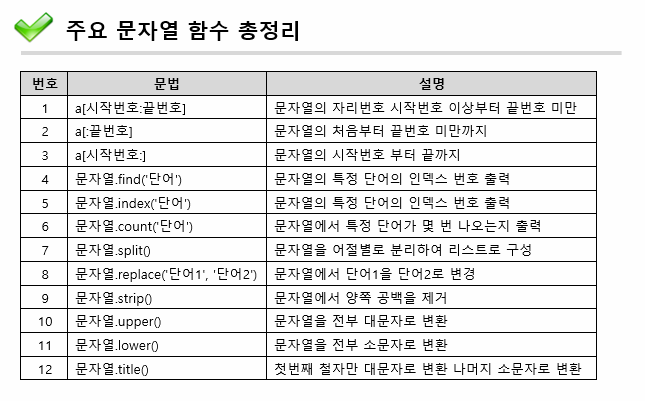
주요문자열 함수 표: https://cafe.daum.net/oracleoracle/Sn5A/91
예제1. 아래의 smith 라는 문자열에서 s만 가져오세요
str = 'smith'
str[0]예제2. 아래의 smith 라는 문자열에서 끝철자만 가져오세요
str = 'smith'
str[-1]예제3. 아래의 smith 라는 문자열에서 smi만 출력
str = 'smith'
str[0:3] # 자리번호 0번부터 3번 미만까지 출력예제 4. emp 데이터 프레임에서 ename을 출력하세요
emp [컬럼리스트] [검색 조건]
emp ['ename']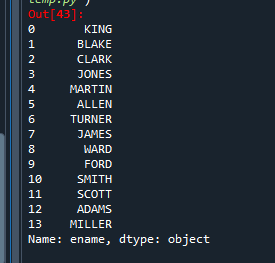
예제 5. emp 데이터 프레임에서 ename, sal 조회
emp [컬럼리스트] [검색 조건]
emp [['ename', 'sal']]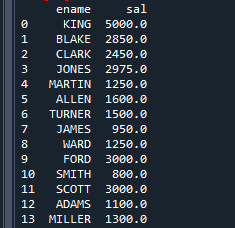
예제 6. emp 데이터 프레임에서 월급이 3000이상인 사원들의 ename, sal을 출력하세요
emp [컬럼리스트] [검색 조건]
emp [['ename', 'sal']] [emp['sal'] >= 3000]예제 7. emp데이터 프레임에서 직업이 SALESMAN인 사원들의 ename, sal, job을 출력하시오
emp [['ename', 'sal', 'job']] [emp['job'] == 'SALESMAN']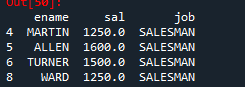
💡 3가지 용어 이해하기
1. 판다스 데이터 프레임 :오라클 테이블emp / type(emp) pandas.core.frame.DataFrame
- 판다스 시리즈 :
오라클의 컬럼type(emp['ename']) pandas.core.series.Series
- 문자열 :
오라클의 문자값예) scotttype(emp['ename'].str) pandas.core.strings.accessor.StringMethods
예제 8. 이름의 첫글자가 S로 시작하는 사원들의 이름, 월급 출력
emp [['ename', 'sal']] [emp['ename'].str[0] == 'S']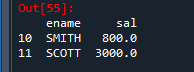
문제 58. 이름의 끝 글자가 T로 끝나는 사원들의 이름, 월급을 출력
emp [['ename', 'sal']] [emp['ename'].str[-1] == 'T']예제 25. 문자열에서 특정 단어를 검색하는 3가지 방법
💡 DBA 작업에서는 DBA 가 항상 눈여겨 봐야할 오라클 alert 로그파일에서 주요 이슈를 빠르게 검색할 때 활용할 내용입니다.
1. 문자열.find('단어') : 문자열의 특정 단어의 자리번호를 출력
2. 문자열.index('단어') : 문자열의 특정 단어의 자리번호를 출력
3. 문자열.count('단어') : 문자열에서 특정 단어가 몇번 나오는지 출력
예제1. 스티브 잡스 연설문에서 아래의 명령어를 이용해 data라는 변수에 담으시오
다운받은 jobs_korea.txt를 c드라이브 밑에 oracledata라는 폴더에 저장하기.
jobs = open("c:\\oracledata\\jobs_korea.txt", encoding="utf8")
data = jobs.read()
print(data)예제2. 스티브 잡스 연설문에 '용기' 라는 단어가 있다면 몇번째 있는지 확인
data.find('용기')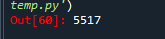
✅ 문법 : 문자열변수.find('찾는 단어')
문제 59. 스티브 잡스연설문에 '직관'이라는 단어가 몇번째 자리에 있는지 출력하기
data.find('직관')
예제3. 스티브잡스 연설문에서 '직관' 이라는 단어 몇번 나오는지
data.count('직관')✅ 2번 쓰였는데, 위의 5509 는 두개의 직관중 첫번째
두번째 직관의 자리번호를 알아내려면?
data.index('직관', 5511)
설명: 스티브 잡스 연설문에서 5511번 뒤로 나오는 직관 이라는 단어의 자리번호를 찾아라
문제 60. 스티브 잡스 연설문에서 어머니 라는 단어가 몇번 나오는지
data.count('어머니')
예제 26. 문자열 다루는 주요 함수 3가지
- 문자열.split() : 문자열을 어절별로 분리하여 리스틀 구성하는 함수
- 문자열.replace ('단어1'. '단어2')ㅣ 뮨저욜애서 단어1 -> 단어2로 변경
- 문자열.sprip : 문자열 양쪽에 공백을 제거하는 함수
예제1. split 함수의 예제
a = '아무것도 하지 않으면, 아무 일도 일어나지 않는다'
a.split()
➡️ 어절별로 담는다!!
예제2. 위 리스트를 b라는 변수에 할당하기
a = '아무것도 하지 않으면, 아무 일도 일어나지 않는다'
b = a.split()
b예제3. b리스트를 판다스 데이터 프레임으로 구성
import pandas as pd # 엑셀 -> 데이터 프레임(테이블)
a = '아무것도 하지 않으면, 아무 일도 일어나지 않는다'
b = a.split()
b
df = pd.DataFrame(b, columns= ['col1'])
df
예제4. pandasqld 모듈을 이용해서 df 데이터 프레임에서 아무 라는 단어가 포함된 행 출력
from pandasql import sqldf # 파이썬에서 sql을 사용할 수 있게 해주는 모듈
pysqldf = lambda q : sqldf( q, globals() )
q = """ select *
from df
where col1 like '%아무%';"""
pysqldf(q)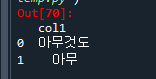
예제5. 문자열 replace함수를 이용해서 아래 문자열에서 '아무'라는 단어를 '어떤'으로 변경하세요
a ='아무것도 하지 않으면, 아무 일도 일어나지 않는다.'
a.replace('아무', '어떤',1) # 1쓰면 하나만 바뀐다.
문제 61. 아래의 b문자열을 다음과 같이 수정해서 출력
# b = '핑계를 찾을지... 핑계를 찾을지...'
# 결과 핑계를 찾을지... 방법을 찾을지...
b = '핑계를 찾을지... 핑계를 찾을지...'
b.replace('핑계', '방법',1) ✅ 위 문제는 문자열 replace함수로는 안되고 리스트를 이용해야합니다.
답!
b = '핑계를 찾을지... 핑계를 찾을지...'
c = b.split()
c # ['핑계를', '찾을지...', '핑계를', '찾을지...']
c[2] = '방법을'
c
d = ' '.join(c) # c리스트에 요소들을 공백으로 구분해서문자열로 출력하는 것 .
d✅

slpit() 함수 : 문자열 -> 리스트
join() 함수 : 리스트 -> 문자열
예제6. strip() 함수의 종류 3가지로 다음의 예제를 연습합니다.
1. strip() ----> 양쪽 공백 제거
2. rstrip() ----> 오른쪽 공백 제거
3. lstrip() ----> 왼쪽 공백 제거
a = ['1.끝내주게 숨쉬기.', '2.간지나게 자기!', '3.작살나게 밥먹기?']
for i in a:
print (i)위 결과를 다시 출력하는데 양쪽 한글 외에 불필요하게 붙어있 것들을 잘라내서 출력
a = [ '1.끝내주게 숨쉬기.' , '2.간지나게 자기!', '3.작살나게 밥먹기?' ]
for i in a :
print( i.strip('123.!?') ) # strip( 잘라내고 싶은 문자들을 나열 ) 문제 62. 다음 문자열에서 보험 상담사가 잘못 사용한 '한달'이 몇건인지 카운트 하기
a = '보험, 실효 개시일은 , 보험 계약 이후 한달, 이후 입니다.'
a.count('한달')★
문제 63. 이번에는 리스트로 만들어서 다음과 같이 코딩하는데, 아래의 코드는 아래의 코드는 한달이 출력되지 않습니다 . 이렇게 코딩해보기
a = '보험, 실효 개시일은, 보험 계약 이후 한달, 이후 입니다.'
a2 = a.split()
for i in a2:
if i == '한달':
print(i)✅ 이거 왜 안되는거냐면 한달, 이라서. comma를 잘라주어야한다.
예제 27. 문자열의 대소문자를 변환하는 3가지 함수
- 문자열.uppder(): 전부 대문자로 전환
- 문자열.lower() : 전부 소문자로 변환
- 문자열title() : 문자열의 첫번째철자는 대문자, 나머지는 소문자
예제 1. 아래의 a리스트의 요소들 중 future가 몇번 나오는지 출력
a = ['Future', 'FUture', 'today', 'fuTure', 'past', 'futuRe', 'today']
cnt = 0
for i in a:
if i.lower() == 'future': # 대소문자 섞여있어서 결과는 0이 나온다.
cnt += 1
print(cnt) 문제 64. 스티브잡스 영문 연설문 jobs.txt에는 today라는 단어가 몇번 출현?
jobs = open("c:\\oracledata\\jobs.txt", encoding="utf8") data = jobs.read() data2 = data.split() data2 cnt = 0 for i in data2: if i.lower() == 'today': cnt += 1 print(cnt)
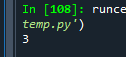
예제 28. 파이썬 문자열 함수들을 이용해서 dba작업을 자동화할 수 있는 예제
➡️ 오라클에 문제가 생겼을 때 진단을 위해 항상 봐야하는 텍스트파일?
답: alret log file -> dba가 항상 실시간 모니터링을 합니다.
현재 우리회사 db에 발생하고 있는 이슈들이 오라클 에러번호와 함께 적혀있다.

C:\app\ITWILL\product\18.0.0\diag\rdbms\xe\xe\trace
alert_xe.log <- 파일 확인
db엔지니어 ---> dba
유지보수 점검 한달 1번씩 특정 회사에 가서 오라클 점검 스크립트를 돌리고 문제가 있는지 없는지 확인하는 레포팅 보고를 해줍니다.
이 회사에 alert log파일을 분석해보니 이번달 ORA-01545에러가 47번 발생했고
ORA-29911 에러는 32번 발생했습니다.
예제1. alert log file을 파이썬으로 로드해서 data라는 변수에 담기
jobs = open("C:\\app\\ITWILL\\product\\18.0.0\\diag\\rdbms\\xe\\xe\\trace\\alert_xe.log", encoding='cp949', errors='ignore')
data = jobs.read()
data예제2. 문자열 변수 data 를 split() 함수를 이용해서 리스트로 구성하시오 !
jobs = open("C:\\app\\ITWILL\\product\\18.0.0\\diag\\rdbms\\xe\\xe\\trace\\alert_xe.log", encoding='cp949', errors='ignore')
data = jobs.read()
data2 = data.split()
data2
- split() : 문자열 ---> 리스트
- join() : 리스트 ---> 문자열
예제3. for loop문을 이용해서 data2리스트에서 요소들을 하나씩 불러오는데
ORA- 를 포함하는 요소들만 출력
jobs = open("C:\\app\\ITWILL\\product\\18.0.0\\diag\\rdbms\\xe\\xe\\trace\\alert_xe.log", encoding='cp949', errors='ignore')
data = jobs.read() #텍스트 -> 문자열 변수
data2 = data.split() # 문자열 -> 리스트
for i in data2 : # 리스트 요소를 하나씩 불러오는데
if 'ora-' in i.lower():
print(i)예제4. 위 ora-가 포함된 건수는 몇건?
jobs = open("C:\\app\\ITWILL\\product\\18.0.0\\diag\\rdbms\\xe\\xe\\trace\\alert_xe.log", encoding='cp949', errors='ignore')
data = jobs.read()
data2 = data.split()
cnt = 0
for i in data2:
if 'ora-' in i.lower():
cnt += 1
print(cnt)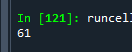
[오늘의 마지막 문제]
예제5. 위의 오라클 에러번호들을 전부 k 라는 리스트에 append 시키시오
jobs = open("C:\\app\\ITWILL\\product\\18.0.0\\diag\\rdbms\\xe\\xe\\trace\\alert_xe.log", encoding='cp949', errors='ignore')
data = jobs.read()
data2= data.split()
k = [] # k라는 비어있는 리스트 만든다
for i in data2: # data2리스트에서 요소들을 하나씩 불러오는데
if 'ora-' in i.lower(): #요소들에 ora-가 포함되어있다면
k.append(i) #k리스트에 추가하시오
k # 출력예제6. k 리스트를 df 라는 데이터 프레임으로 만드시오
import pandas as pd # 판다스 모듈을 임포트하고 별칭을 pd라고 합니다.
df = pd.DataFrame( k, columns=['col1'] ) # k리스트를 가지고 df라는 판다스 데이터프레임 생성
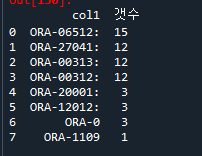
df # 출력예제7. pandasql을 이용해서 오라클 에러가 몇건 발생했는지 출력하는데 다음과 같이 높은것 부터 출력하시오 !
from pandasql import sqldf
pysqldf = lambda q : sqldf( q, globals() )
q = """
select col1, count(*) as 갯수
from df
group by 1 desc;
"""
pysqldf(q)