
🤔리눅스를 배우는 이유?
- 회사의 데이터베이스는 리눅스 서버에서 가동중이기 때문! 윈도우에서 오라클을 다루는 곳은 별로 없다..!
- 리눅스 쉘스크립트를 이용해서 DB작업을 자동화 하기 위해
✔️ PL/SQL + 파이썬 + 리눅스 쉘 스크립트
sort 명령어
💡 data
실습1. emp.csv에서 이름, 월급을 출력하는데 월급이 낮은 사원부터 출력하기
[orcl:~]$ sort -t ','
-nk6 emp.csv
✅-nk 에서 n안쓰고 -k만 쓰면 1100 보다 950이 더 뒤에 나온다. , 6은 6번째 컬럼!
파이프 연산자 !
[orcl:~]$ sort -t ',' -nk 6 emp.csv | awk -F ',' '{print $2, $6}'
✅ 파이프 연산자 (|)
: 리눅스 명령어1 | 리눅스 명령어2
파이프 명령어 이전 명령어로 수행한 결과를 파이프 명령어 이후의 명령어의 입력값으로 전달한다.
: 낮은값에서 높은값 순서로 |
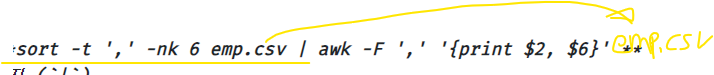
실습2. emp.csv에서 이름, 월급을 출력하는데 월급이 높은 사원부터 출력하기
[orcl:~]$ sort -t ',' -nrk 6 emp.csv | awk -F ',' '{print $2, $6}'
✅r옵션은 reverse의 약자로 값을 descending하게 출력하겠다는 것.
문제 36. 직업이 세일즈맨, 이름 월급 직업을 출력 월급이 노픙ㄴ 사원부터
awk -F ',' '$3=="SALESMAN" {print $2,$3,$6}' emp.csv | sort -nrk 3
위 경우는-t,,를 쓰면 안된다. 이미 콤마로 구분되어있지 않아서
문제 37. 월급이 1200 이상인 사원들의 이름, 월급을 출력하는데 월급이 높은 사원부터 출력
[orcl:~]$ awk -F ',' '$6>=1200 {print $2,$6}' emp.csv | sort -nrk 2
KING 5000
SCOTT 3000
FORD 3000
JONES 2975
BLAKE 2850
CLARK 2450
ALLEN 1600
TURNER 1500
MILLER 1300
WARD 1250
MARTIN 1250
ename sal
uniq 명령어
💡 중복된 라인을 제거하는 명령어
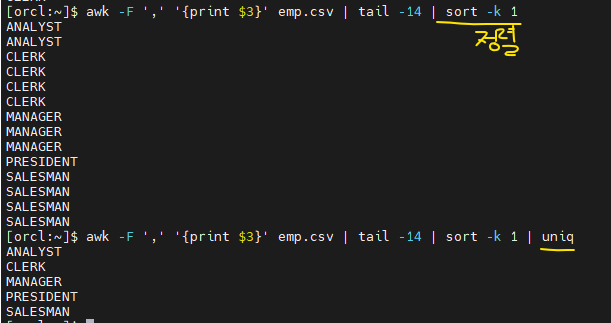
실습1. 직업을 출력하는데, 중복을 제거해서 출력하기
awk -F ',' '{print $3}' emp.csv | tail -14 | sort -k 1 | uniq
⭐ 정렬을 먼저 해서 제거해야 중복이 제대로 제거된다.
✅tail -14는 컬럼명 안보이고 데이터만 보이게 하려고 쓴것
✅ 직업이 문자라서-k라고 쓴 것. 데이터가 하나밖에 없어서 1 쓴것!
문제 38. 부서번호를 출력하는데, 중복을 제거해서 출력하기
[orcl:~] $ awk -F ',' '{print $8}' emp.csv | tail -14 | sort -nk 1 | uniq
10
20
30
문제 39. 관리자 번호를 출력하는데, 중복을 제거해서 출력
[orcl:~]$ awk -F ',' '{print $4}' emp.csv | tail -14 | sort -nrk 1 | uniq
7902
7839
7788
7782
7698
7566
지금까지 배운 것들 복습하기
문제 40. 방금 올린 reviewData2.csv파일의 총 라인수 구하기
[orcl:~]$
wc-l reviewData2.csv
10000 reviewData2.csv
문제 41. head 명령어로 reviewData2.csv에서 10개의 행만 출력
[orcl:~]$ head -10 reviewData2.csv
문제 42. reviewData2에서 '모가디슈' 라는 단어를 포함하는 행들이 몇개가 있는지 출력
[orcl:~]$ grep -i '모가디슈' reviewData2.csv | wc -l
3581
문제 43. 영화이름을 중복제거해서 출력
[orcl:~]$ awk -F ',' '{print $1}' reviewData2.csv | sort -k 1 | uniq
문제 44. 위에서 출력되는 행들의 건수 출력
[orcl:~]$ awk -F ',' '{print $1}' reviewData2.csv | sort -k 1 | uniq | wc -l
1744
diff 명령어
💡 두 파일간의 차이점을 찾아서 알려주는 명령어
실습1. emp.csv를 emp_backup.csv로 복사하기
$ cp emp.csv emp_backup.csv
$ ls -l emp_backup.csv
실습2. emp_backup.csv을 열어서 일부 내용을 수정하고 저장한다. (노트패드)
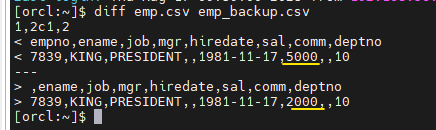
실습3. emp.csv emp_backup.csv 차이 확인하기
diff emp.csv emp_backup.csv
문제 45. reviewData2.csv를 reviewData2_backup.csv로 복사
문제 46. reviewData2_backup.csv을 노트패드로 열어서 일부 데이터 수정
문제 47. reviewData2.csv 와 reviewData2_backup.csv의 차이 확인
[orcl:~]$ diff reviewData2.csv reviewData2_backup.csv
13c13< 모가디슈,10, --- 모가디쓔,10, 27c27 < 모가디슈,10,오랜만에 감동적인 영화였습니다. 연출과 연기가 마음까지 와닿았습니다. 벌써 두번이나 봤지만 한번 더 보러 갈 예정입니다^ --- 모가디슈,10,오랜만에 감동적인 영화. 연출과 연기가 마음까지 와닿았습니다. 벌써 두번이나 봤지만 한번 더 보러 갈 예정입니다^ 35c35 < 모가디슈,10,"믿고보는정만식,조인성배우" --- 모가디슈,10,"믿고보는정만식,윤성해배우"

find 명령어
💡 검색하고자 하는 파일을 찾을 때 사용하는 명령어
실습1. /home/oracle밑에 있는 emp.csv를 찾으세요
$ find /home/oracle -name emp.csv -print
✅ 문법:find검색할 디렉토리-name검색할파일명

문제 48. /home/oracle/labs/labs 밑에 setup_workload.sql 파일이 있는지 확인해보기
[orcl:~]$ find /home/oracle/labs/labs -name setup_workload.sql -print
/home/oracle/labs/labs/setup_workload.sql
문제 49. /home/oracle/labs/labs 밑에 job이라는 단어를 포함하는 확장자.sql파일 있는지 확인 -> * 사용하기 !
[orcl:~]$ find /home/oracle/labs/labs -name *job*.sql -print /home/oracle/labs/labs/my_lwy_job.sql /home/oracle/labs/labs/my_lwt_job.sql
sed 명령어
💡 grep 명령어는 파일의 특정 내용을 검색하는 명령어라면 sed 명령어는 검색 뿐만 아니라 내용을 변경해서 보여주는 명령어입니다.
실습1. emp.csv에서 KING의 이름을 yyy로 변경해서 보여달라
$ sed 's/KING/yyy/g' emp.csv
✅ s, g는 꼭 써야하는 문법. g를 써야 모든 KING 이 yyy로 변경된다.
sed s / 변경전데이터 / 변경후데이터 / g 파일명
실제로 변경되는것은 아니다!
문제 50. 데이터 게시판 412번 글의 데이터를 리눅스에 올리기
문제 51. movies.dat 파일의 위 3줄만 출력

문제 52. movies.dat 파일의 전체 행수가 몇건인지 확인
[orcl:~]$ wc -l movies.dat
3883 movies.dat
문제 53. movies.dat 데이터를 출력하는데, sed 명령어를 이용해서 ::를 콤마(,)로 변경해서 출력하기
[orcl:~]$ sed 's/::/,/g' movies.dat

문제 54. 위 결과를 movies.csv파일로 저장
[orcl:~]$ sed 's/::/,/g' movies.dat >> movies.csv
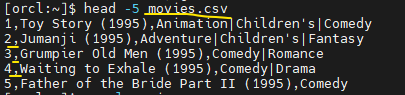
문제 55. ratings.dat파일의 라인수 확인
[orcl:~]$ wc -l ratings.dat
1000209 ratings.dat
문제 56. ratings.dat파일의 :: 를 ,로 변경하고, ratings.csv로 저장
[orcl:~]$ sed 's/::/,/g' ratings.dat >> ratings.csv
[orcl:~]$ head -5 ratings.csv
1,1193,5,978300760
1,661,3,978302109
1,914,3,978301968
1,3408,4,978300275
1,2355,5,978824291
문제 57. dept.csv를 dept7.csv로 복사하기
$ cp dept.csv dept7.csv
문제 58. emp.csv를 emp1.csv ~ emp10.csv로 생성하기
➡️ 지금 이거는 10번 다 수행해야한다. 그래서 파이썬으로 해보기
- $ touch p.py
그리고 모바텀 이용하여 노트패드로 연다.- 노트패드에
import os for i in range(1, 11): os.system('cp /home/oracle/emp.csv /home/oracle/emp'+str(i)+'.csv')
- python p.py를 리눅스에서 수행! 그리고 잘 되었는지 확인해본다.

문제 59. dept.csv를 복사하는데 , dept1.csv ~ dept100.csv까지 복사
import os for i in range(1, 101): os.system('cp /home/oracle/dept.csv /home/oracle/dept'+str(i)+'.csv')$ python p.py
$ ls -l dept*.csv
문제 60. rm 명령어로 dept1.csv ~ dept100.csv를 지우시오
$ rm -rf dept*.csv
✅ -rf 옵션을 쓰지 않으면 지울때 마다 물어본다.
문제 61. /home/oracle 밑에 있는 emp.csv를 /home/oracle/labs/labs밑에 emp2.csv라는 이름으로 복사하기
[orcl:~]$ cp /home/oracle/emp.csv /home/oracle/labs/labs/emp2.csv
$ ls -l /home/oracle/labs/labs/emp2.csv
mv 명령어
파일을 다른 디렉토리로 이동하거나 또는 파일의 이름을 변경할 때 사용하는 명령어
실습1. emp.csv 파일의 이름을 employee.csv 로 변경하시오
$ mv emp.csv employee.csv
$ cat employee.csv
- /home/oracle/ 밑에있는 emp.csv 파일을 /home/oracle/labs 밑으로 이동시키시오
$ mv /home/oracle/emp.csv /home/oracle/labs/emp.csv
chown 명령어
💡 chown 은 change owner의 약자
실습1. emp.csv의 소유자가 누구인지 확인한다.
[orcl:~]$ ls -l emp.csv
-rw-r--r-- 1 oracle oinstall 679 Aug 16 14:16 emp.csv
-rw-r--r--: 권한정보,
oracle: 소유자,
oinstall: 그룹이름
실습2. root 유저로 접속합니다.
$ su - -> password 물어본다.
: 암호 치면 root 유저로 변경된다.
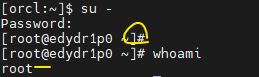
실습3. root유저에서 /home/oracle 밑에 있는 emp.csv의 소유자를 root로 변경해보세요
[root@edydr1p0 ~]# chown -R root:root /home/oracle/emp.csv
[root@edydr1p0 ~]# ls -l /home/oracle/emp.csv
-rw-r--r-- 1rootroot 679 Aug 16 14:16 /home/oracle/emp.csv
✅ root가 소유자가 되었다.
실습4. /home/oracle 밑에 emp.csv의 소유자를 oracle로 변경하고 그룹명도 원래대로 oinstall로 변경하기
[root@edydr1p0 ~] # chown -R oracle:oinstall /home/oracle/emp.csv
[root@edydr1p0 ~] # ls -l /home/oracle/emp.csv
-rw-r--r-- 1 oracle oinstall 679 Aug 16 14:16 /home/oracle/emp.csv

문제 63. p.py파일의 소유자가 누구인지 확인하기
$ ls -l /home/oracle/p.py
or
$ ls -l p.py
문제 64. p.py의 소유자를 root 로 변경하기
1. su - cd /home/oracle
2. chown -R root:root p.py3. chown -R oracle:oinstall p.pychmod 명령어
💡 파일이나 디렉토리의 권한을 변경하는 명령어
- 권한의 종류 3가지
번호 권한 대표문자
4 읽기 r
2 쓰기 w
1 실행 x실습1. emp.csv의 권한을 확인하세요
[orcl:~]$ ls -l emp.csv
-rw-r--r-- 1 oracle oinstall 679 Aug 16 14:16 emp.csv
-rw-r--r--을 해석해보면,
✅ 첫-가 d 면, 디렉토리이고 그냥-면 파일이다.
✅rw-emp.csv의 소유자 권한정보! r: 읽기가능, w: 쓰기가능
✅r--그룹의 권한정보. 이 그룹에 속한 유저들은 이 파일을 읽을 수 있다.(읽기만)
✅ 마지막r--은 기타 유저들의 권한정보. 기타 유저들은 이 파일을 읽을 수 있다.(읽기만)
실습2. emp.csv의 권한을 다음과같이 변경하세요.
-> 소유자(u): 읽고, 쓰고, 실행 가능
-> 그룹(g): 유저들은 읽고, 쓰는 권한만. (실행x)
-> 기타(o): 유저들은 읽기만 가능(쓰기x, 실행x)
[orcl:~]$ chmod u+rwx,g+rw,o+r emp.csv
[orcl:~]$ ls -l emp.csv
-rwxrw-r-- 1 oracle oinstall 679 Aug 16 14:16 emp.csv
-rwxrw-r--
실습3. 이번에는 emp.csv 에 대해 유저,그룹, 기타유저 모두 읽고 쓰고 실행할 수 있는 권한을 제거하세요
[orcl:~]$ chmod u-rwx,g-rwx,o-rwx emp.csv
권한 없다고 나온다.


실습4. 다시 모든 권한을 넣자.
$ chmod u+rwx,g+rwx,o+rwx emp.csv
$ ls -l emp.csv
$ cat emp.csv
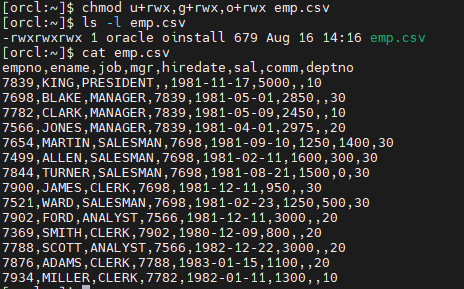
숫자로 권한주기
실습5. 이번에는 다시 emp.csv에 대해 유저, 그룹, 기타 유저들이 모두 읽고 쓰고 실행할 수 없도록 하기. (숫자로!)
$ chmod 000 emp.csv

실습6. 이번에는 다시 emp.csv에 대해 유저, 그룹, 기타 유저들이 모두 읽고 쓰고 실행할 수 있도록 하기. (숫자로!)
$ chmod 777 emp.csv
✅ 읽기 :4, 쓰기 :2, 실행 :1 라서 모두 더한값이 7이다.

실습7. 이번에는 아래와 같이 emp,csv의 권한을 조정하세요
유저: 읽기(4), 쓰기(2) = 6
그룹: 읽기(4) = 4
기타: 읽기(4) = 4
[orcl:~]$ chmod 644 emp.csv

문제 66. emp.csv에 대해 아래와 같이 권한을 조정하세요
소유자: 읽기, 쓰기, 실행
그룹: 읽기, 쓰기
기타: 읽기
[orcl:~]$ chmod 764 emp.csv
[orcl:~]$ ls -l emp.csv
-rwxrw-r-- 1 oracle oinstall 679 Aug 16 14:16 emp.csv
echo? 변수안에 내용을 보여달라!
문제 67. (dba작업) 오라클의 홈 디렉토리가 어딘지 확인하기
$ echo $ORACLE_HOME
✅ echo: $ORACLE_HOME 이라는 변수안에 내용을 보여달라 라는 뜻
이 디렉토리에 오라클 관리에 필요한 데이터와 실행파일들이 저장되어 있습니다.

문제 68. 위의 오라클 홈 디렉토리로 이동
$ cd /u01/app/oracle/product/11.2.0/dbhome_1

문제 69. 이동한 후에 보이는 디렉토리와 파일들의 권한, 소유자를 확인하기
$ ls -l *
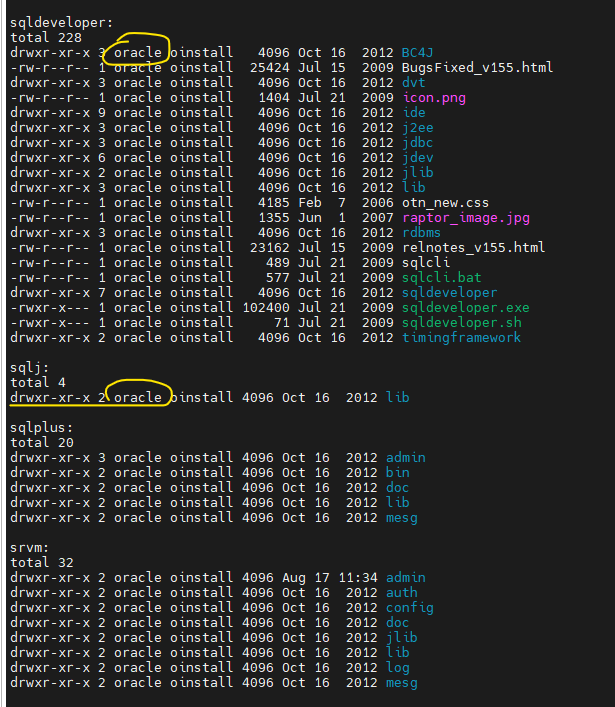
문제 70. 위에서 출력되고 있는 결과를 dba.txt로 저장하기
[orcl:dbhome_1]$ ls -l * >> dba.txt
✅ dba는 오라클에 관련한 디렉토리와 파일들에 대해 권한정보를 잘 알고 있어야 합니다. 나중에 db에 문제가 생겼을 때 os에서 생기는 많은 문제들이 권한관리에 대한 문제가 대부분이기 때문.
top 명령어
💡 현재 리눅스 서버에서 수행되고 있는 모든 프로그램에 대한 cpu와 메모리 사용율을 확인하는 명령어
$ top
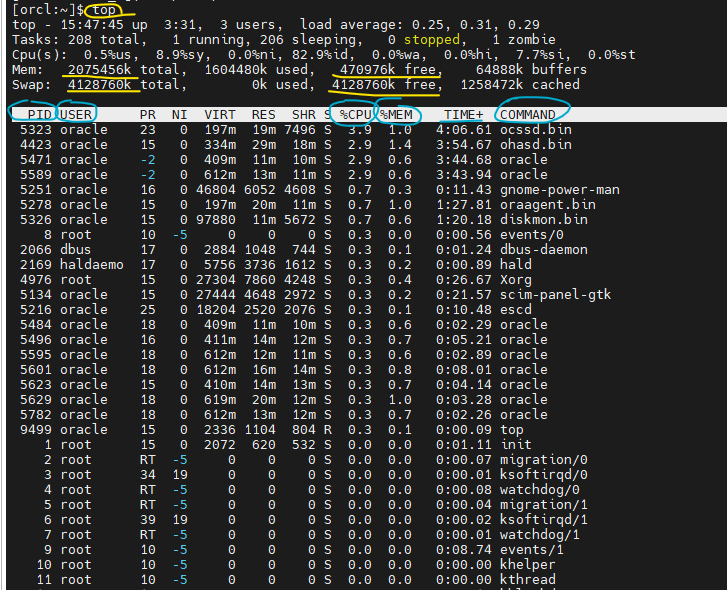
실습1. 하나의 터미널창은 top으로 열어놓는다.
실습2. 다른창은 ( 푸티로 하나 열던지, 모바텀에서 다른창을 열던지 ) oracle scott유저로 접속하기.
$ sqlplus scott/tiger
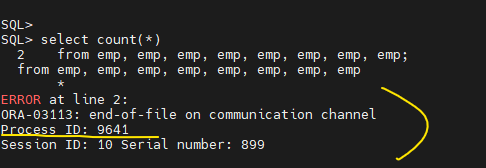
실습3. scott계정에서 악성sql 실행해보고 top 명령어에서 맨 위에 나오는 cpu를 100% 가까이 사용하고있는 그 프로세서가 바로 리눅스 서버에 부하를 가장 많이 주고 있는 세션이다.
해당 PID: 9641


실습4. 해당 서버를 느리게 하는 그 프로세서를 kill시킵니다.
$ kill -9 9641
위 명령어 실행하니까, 악성sql이 있는 쪽에서 에러가 나고 꺼지고, top쪽에서도 꺼졌다.
✅ 이 프로세서가 어떤 프로세서인지 확인하는 쿼리문을 실행하고서
✅ dba가 우선순위를 잘 파악해서 서버의 부하를 주고있는 세션을 kill시킬지 말지를 결정한다.
어떤 작업을 하고있는 세션인지는 알고 kill해야한다. -> db 관리수업때 진행!
리눅스 서버의 오라클에 접속하기
윈도우 환경 --------------------------> 리눅스 서버
PUTTY
모바텀 오라클
sqldevelopersqldeveloper로 오라클에 접속할 것이다.
1. 포트 포워딩을 한다.
- 리눅스 서버에서 root 유저로 접속해서 서버의 아이피주소를 확인합니다.
$ ifconfig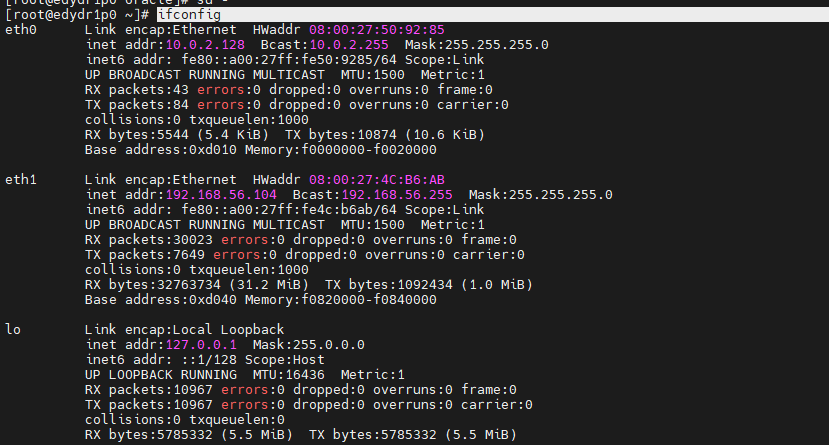
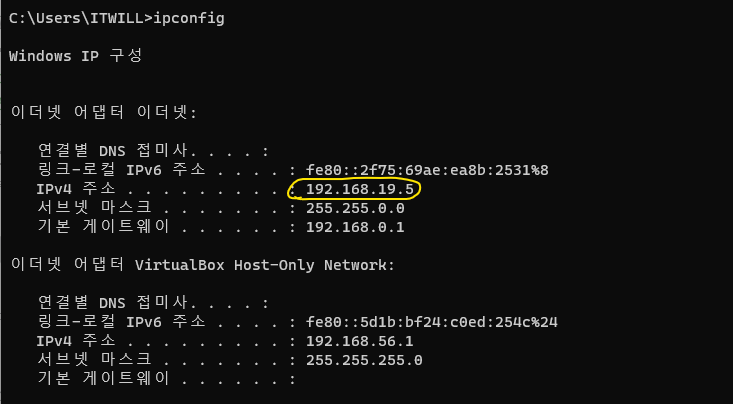
- 윈도우에서
ipconfig로 윈도우의 아이피 주소를 확인한다.
이제 아래 화면을 리눅스에서 찾아야한다.
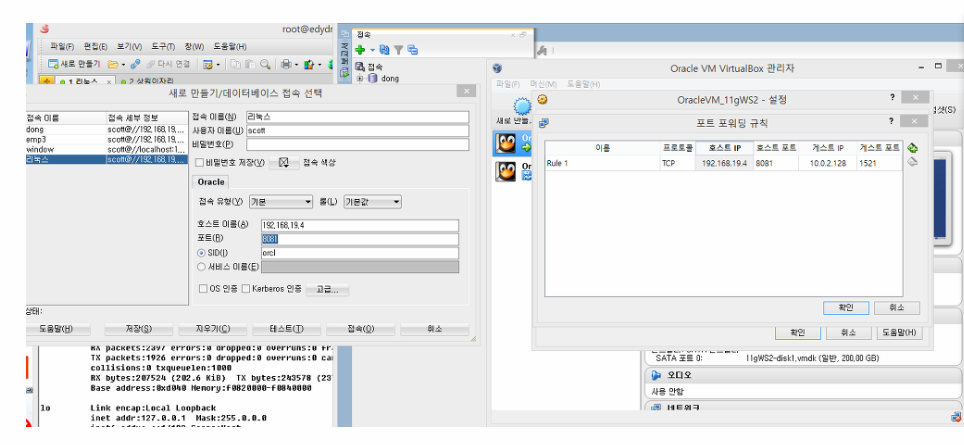
설정 > 네트워크 > 고급 > 포트포워딩 > 우측 상단 녹색 플러스버튼
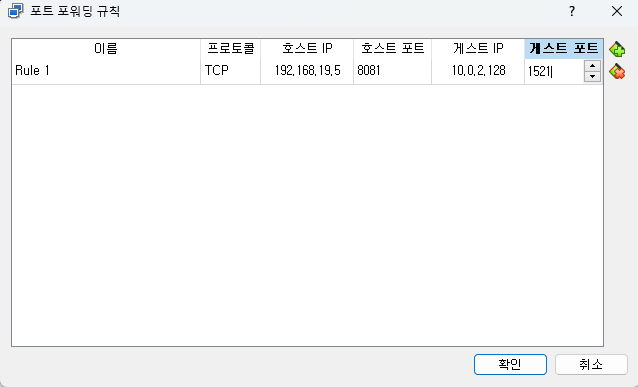
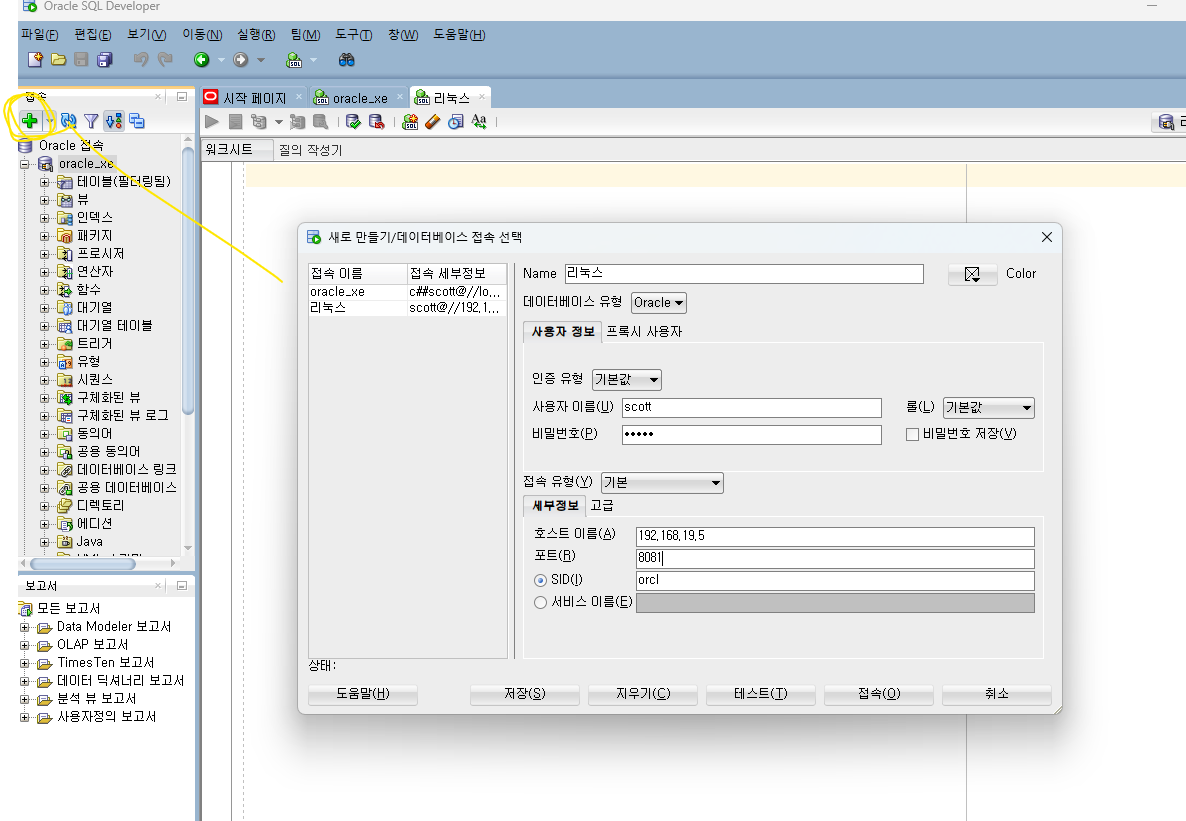
테스트 -> 성공하면 접속 !
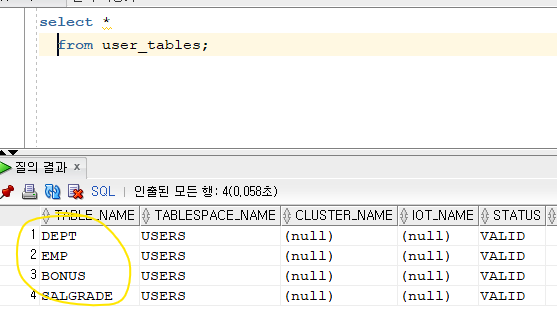
리눅스 오라클에는 테이블이 4개밖에 없다 !
리눅스 서버에서 scott 유저에게 권한을 줘야한다 . 리눅스 서버에서 오라클에 sys 유저로 접속하기!!

다시 sqldeveloper껐다가 다시 scott으로 접속 후에 도구 > 세션 모니터 접속하기 여기서 PID 정보가 나오면 악성 sql이 무엇인지 볼 수 있는데 세션모니터에서 없다. 그냥 sql로 알아보기로!
top 명령어에서 확인된 cpu 과다사용 오라클 유저의 악성 sql 알아내기
문제 71. (마지막 문제) dba가 가지고 있어야 할 필수 스크립트를 이용해서 top에서 잡힌 PID로 해당 프로세서의 slow SQL이 어떤것인지 알아내시오 !
1. scott 계정에서 악성 sql작성
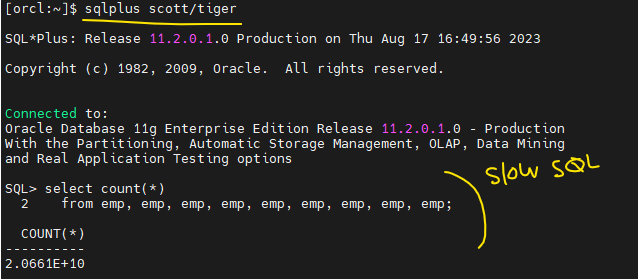
2. 다른 창에서 top 명령어 실행했을 때 CPU가 99 ~~~ 이런애 확인

3. sqldeveloper 에서 아래 sql문 실행 (악성 sql 잡아내는 sql임.)
set heading off
set verify off
set pagesize 60
accept ospid prompt 'Enter OS PID : '
col txt format a60 wrap
col ex format 99,999,990
col ov format 99,999,990
col ld format 99,999,990
col lv format 99,999,990
col sm format 99,999,990
col pm format 99,999,990
col rm format 99,999,990
col uo format 99,999,990
col pc format 99,999,990
col dr format 99,999,990
col bg format 99,999,990
col hdg format a30 newline
set heading off
Select '[SQL]' hdg, a.sql_text txt,
' ' hdg,
'Execution Count' hdg, a.executions ex,
'User Opening' hdg, a.users_opening uo,
'Parse Calls' hdg, a.parse_calls pc,
'Disk Reads' hdg, a.disk_reads dr,
'Buffer Gets' hdg, a.buffer_gets bg,
'Open Versions' hdg, a.open_versions ov,
'Loads' hdg, a.loads ld,
'Loaded Versions' hdg, a.loaded_versions lv,
'Sharable Memory' hdg, a.sharable_mem/1024 sm,
'Persistent Memeory' hdg, a.persistent_mem/1024 pm,
'Runtime Memory' hdg, a.runtime_mem/1024 rm
from v$sqlarea a, v$session b, v$process c
where c.spid = '&ospid'
and c.addr = b.paddr
and b.sql_address = a.address
and b.sql_hash_value = a.hash_value
/4. 아까 확인한 PID 넣기

5. 확인

