스프링 부트로 sns API를 만드는 프로젝트를 진행했는데, 큼직한 기능만 살펴보면, 채팅, 게시글, 검색기능을 가지고 있다. 이러한 기능들을 서버 하나에 구현을 하였는데, 디비 말고는 기능적으로 연결되어 있지 않음에도, 오류가 생기면 각각의 기능들을 사용할 수 없게 되는 문제가 자주 발생했다. (당연한 이야기지만, 서버 하나에 모든 기능을 올려놨으니, 서버가 안돌아가면 말짱 도루묵인 것이다)
하지만 해당 필요성을 느낀건 개발을 끝마쳐갈 때 쯤이었고, 이미 구현이 되어 있는 것을 완성시키지 않은 상태에서 시도하려고 하니, 늦은감이 없지 않아 있었고, 해당 방법이 효율적인가에 대한 확신도 없었다. 단순히 서버만 분리해서 디렉토리 구조만 편하게 보는 정도 아닌가? 하는 의문 수준에 그쳐있던 것이다. 기업에서 서비스하는 대규모 시스템도 아니거니와, 내가 느낀 불편함은 다닥다닥 붙어있는 디렉토리를 보느라 눈이 좀 아픈 수준에 불과했기 때문이다.
그러다가 api를 완성시키고 서버에 대해서 조금 더 공부를 할겸 이론들을 살펴보던 중 MSA 라는 개념을 알게 되었다.
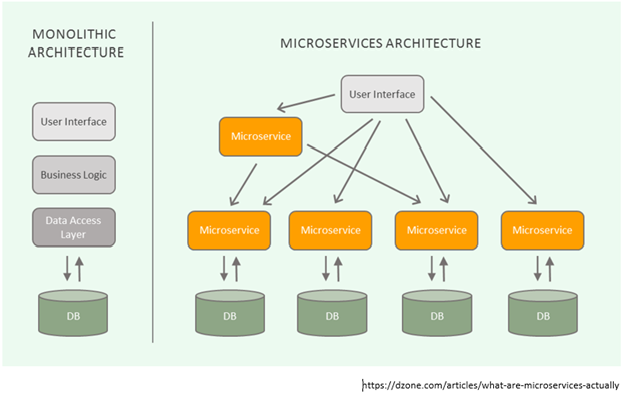
일단, 내가 사용한 아키텍처는 Monolithic Architecture였다.
그렇다면 Monolithic은 사용하면 안됐고, 지금이라도 MSA로 디벨롭을 해야할까? 그럼 현재 디비를 공용으로 두고 여러 서버가 접근하는 식으로 짜야할까, 아니면 각각의 서버마다 독립적인 디비가 있어야할까. 아무튼 이런 고심을 하다가 굳이 MSA로 변경하지는 않기로 결정했다.
소프트웨어의 모든 구성요소가 한 프로젝트에 통합되어있는 형태로,아직까지는 많은 소프트웨어가 Monolithic 형태로 구현되어 있고, 소규모 프로젝트에는 Monolithic Architecture가 훨씬 합리적이다.
위의 글귀가 내게 위안을 줬기 때문이다. 사실 취준생의 입장에서 이것도 해보고 저것도 해보고 싶은 욕망을 느낀 적은 많지만, 이전에 하둡 분산환경 구축을 통해서 진행한 프로젝트에서, 좋은 개발 == 좋은 기술 or 뭔가 있어보이는, 미래를 생각한 성장가능한 구성
이라는 것에 대해서 회의감을 느꼈다.
미래에 서비스가 커질 것을 고려해서 아키텍처를 짜고 데이터 플로우를 짜는 것은 분명 중요한 능력이다. 그런데 그런 모든 기술적 고찰 위에는 현실적 상황이라는 것이 존재했다.
위의 프로젝트 대해서 가볍게 이야기를 해보자면, 다섯 명으로 이루어졌던 우리 팀은 빅데이터 기술 스택과, 분산환경, ec2, docker 등등 에 대한 지식이 전무한 상황에서 해당 프로젝트를 진행하다보니, 프로젝트에 초점이 간 것이 아니라, 프로젝트를 위한 환경구성에 더욱 많은 시간을 소비했다. 심지어 우리가 다루던 데이터량에 비해서 노드 5개로 구성된 Spark 환경은 배보다 배꼽이 더 큰 격이었고, 구축하면서 느꼈던 것은 그냥 pandas 를 사용했다면 더욱 빠르게 만들었을 것 같다는 생각이 매번 들었다.
아무튼 잡소리는 여기 까지 하고 아래에는 MSA의 개념에 대한 정리를 간단하게 해놓으려고 한다.
MSA
MSA는 각각을 마이크로하게 나눈 독립적인 서비스를 연결한 구조를 말하며, 이러한 특성 덕분에 시스템 전체의 중단 없이 필요한 부분만 업데이트·배포가 가능합니다.
MSA의 장점
- 서비스 간 독립성으로 인해 확장성과 유연성이 높아진다.
- 기능 고립성이라는 특징 때문에 일부 서비스가 실패하더라도 전체 시스템에 큰 영향을 미치지 않는다.
MSA의 단점
- 서비스 간 통신이 필요하며, 서로 간 연결 구축 및 관리의 복잡성이 증가한다.
- 초기 개발 및 통신 등에 시간이 소요된다.
