pandas란?
관계형 또는 레이블이 된 데이터로 쉽고 직관적으로 작업할 수 있도록 설계되었고 빠르고 유연한 데이터 구조를 제공하는 Python 패키지
pandas의 주요 기능
-
Python 자료구조와 호환
-
큰 데이터 빠른 indexing, slicing, sorting
-
두 데이터 간의 join
-
데이터의 pivoting, grouping
-
데이터의 통계 및 시각화
-
외부 데이터를 pandas 자료구조로 저장 및 출력
pandas 자료구조
pandas의 자료구조를 사용하기 전, Pandas 라이브러리를 import 합니다.
import pandas as pd
from pandas import Series, DataFrameSeries란
- 1차원 데이터
- (index - value) 로 구성
파이썬 자료구조로 Series 생성
Pandas 라이브러리 Series는 파이썬의 다양한 자료구조와 호환이 됩니다.
list
data = pd.Series([1,2,3,4])tuple
data = pd.Series((1,2,3,4))numpy.array
import numpy as np
data = pd.Series(np.array([1,2,3,4]))Series함수로 생성
data = Series({1: 1, 2: 2, 3: 3, 4: 4})Series 조회
data = Series([100, 200, 300], index=["사과", "배", "수박"])위와 같이 과일의 가격이 나와있다고 할 때, 과일의 가격을 조회해보자.
index로 조회
data.at["사과"]
data["사과"]위 두 표현은 같은 결과를 출력한다.
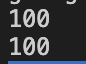
data[["사과", "배"]]위의 표현은 한번에 여러 index를 조회할 수 있다.
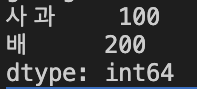
그 이외에도
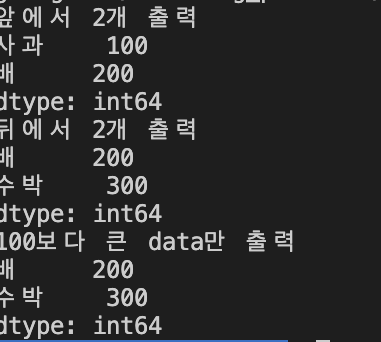
print("앞에서 2개 출력")
print(data[0:2]) # 앞에서 2개
print("뒤에서 2개 출력")
print(data[-2:]) # 뒤에서 2개
print("100보다 큰 data만 출력")
print(data[data > 100]) # 100보다 큰 data만 출력등과 같은 표현도 가능하다!
1개의 Series에서의 연산
과일의 물가가 일괄적으로 올라 한번에 200씩 추가하려 한다!
data += 200
data = data.add(200) # data.add()는 data값 변경 X위 두 표현은 같은 연산을 실행한다.
2개의 Series간 연산
data = Series([100, 200, 300], index=["사과", "배", "수박"])
newdata = Series([200, 500], index=["사과", "귤"])
adddata = data+newdata
print(adddata)위 코드의 결과를 확인해보자.
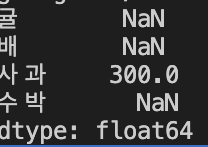
두 Series간 중복되는 index만 연산이 진행되고 나머지 index는 NaN으로 저장된다
NaN 데이터 처리
fill_value 옵션을 사용하면 NaN이 발생했을때 특정 값으로 대입할 수 있습니다.
adddata = data.add(newdata, fill_value = 0)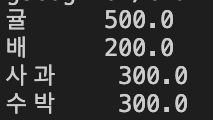
NaN을 0으로 대체
adddata = data + newdata
adddata = adddata.fillna(0)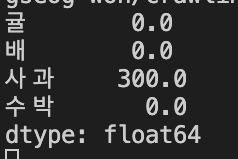
NaN이 나온 행을 삭제
adddata = data + newdata
adddata = adddata.dropna()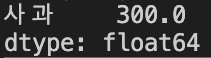
통계
describe 함수
데이터 통계 정보를 확인할 수 있습니다!
print(data.describe())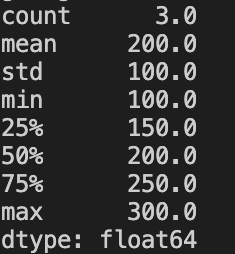
print(data.describe()["count"])위와 같이 index로 접근할 수 있습니다.
