
S3를 사용하면서 csv파일이 S3로 업로드 되었을 때 다른 DB로 csv파일을 적재하는 과정을 수동으로 진행하면서 많은 불편함을 가졌습니다. 이를 자동화 하기 위해 S3와 DB를 연결 해주는 API 서버로 Flask를 이용하고 S3 트리거로 lamda를 사용하였습니다. 람다를 실제로 처음 사용해보면서 겪은 점을 기록합니다.
1. overview
가장 처음으로 S3에 오브젝트가 적재되었을 때 이벤트를 발생시키기 위한 방법으로 두가지 방법을 생각했습니다. 첫번 째는 API server에서 주기적인 간격으로 S3의 상태를 검사해(예:전체 오브젝트 개수의 변화) 오브젝트가 추가되었는지 확인하는 것입니다. 두번 째 방법은 AWS에서 제공하는 방법인 S3 trigger로 lamda를 사용하는 것이었습니다. 두가지 다 장단점이 존재하였습니다. 전자의 방법은 실시간으로 처리를 하기 위해서는 짧은 시간을 주기로 S3를 확인 해야하는데 이는 시스템에 부하를 줄 수 있습니다. 후자의 lambda를 사용할 경우 이는 해결되지만 비용 문제가 발생합니다. 두가지 방법을 고려해 lambda를 사용하기로 결정하였습니다.전체적인 flow를 간략하게 도식화 하면 다음과 같습니다. ![]()
2. Flask API 설정
flask 프로젝트를 생성하고 lambda에서 POST 방식으로 request를 요청할 예정이기 때문에 다음과 같은 클래스를 만들었습니다.DB에서 S3에 존재하는 오브젝트에 직접 접근이 불가하기 때문에 S3에서 로컬로 다운을 받은 후 다시 DB로 적재해야합니다. 이를 위해 필요한 정보를 labmda에서 JSON형식으로 전달 받습니다.
@api.route('/obj')
class S3UploadtoDb(Resource):
""" S3UploadtoSqream
S3 object가 upload 되었을 때 Event Handler를 위한 클래스
"""
s3 = boto3.client('s3',
aws_access_key_id=ACCEESS_KEY,
aws_secret_access_key=SECRET_KEY)
s3_resource = boto3.resource('s3')
def post(self):
""" HTTP Request 'POST' 방식에 대한 처리
"""
start_time = time.time()
params = request.get_json()
bucket = params['bucket']
path = params['path']
table_name = params['table_name']
flag = params['flag']
file_name = path.split('/')[-1]
path = path.split('/')[0]
#DB에 오브젝트를 업로드 하는 함수
output =self.upload_to_db(bucket, file_name, path, table_name, output)
measured_time = time.time() - start_time
output['time'] = measured_time
return output3. Lambad 설정
S3 트리거로 lambda를 실행시키기 위해서 함수를 생성합니다. 아래와 같이 '함수 생성'을 클릭 한 후 블루프린트에서 ' s3-get-object-python' 항목을 선택합니다.
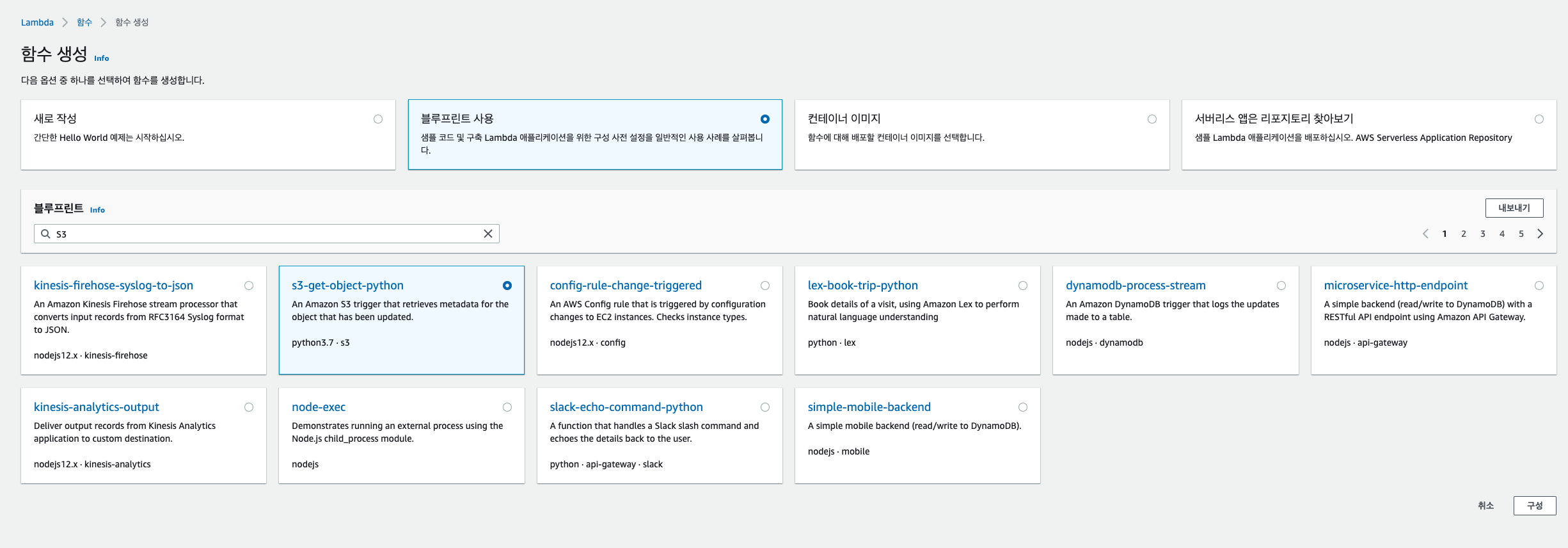
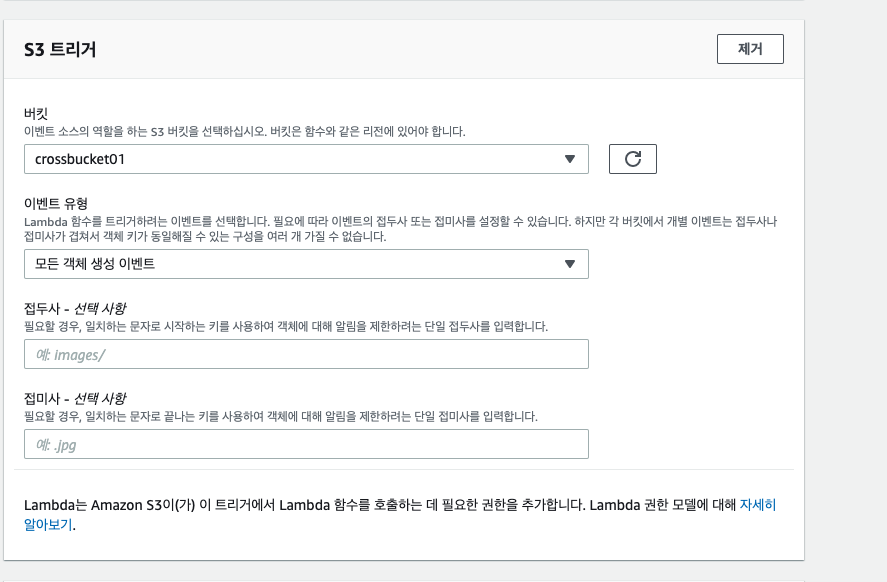
이후 기본적인 내용을 입력하고 S3 트리거를 위한 버킷을 선택합니다. Prefix,Suffix를 사용해 오브젝트에 룰을 설정 할 수 있습니다. 현재는 S3 모든 오브젝트를 대상으로 함수가 실행하도록 합니다.
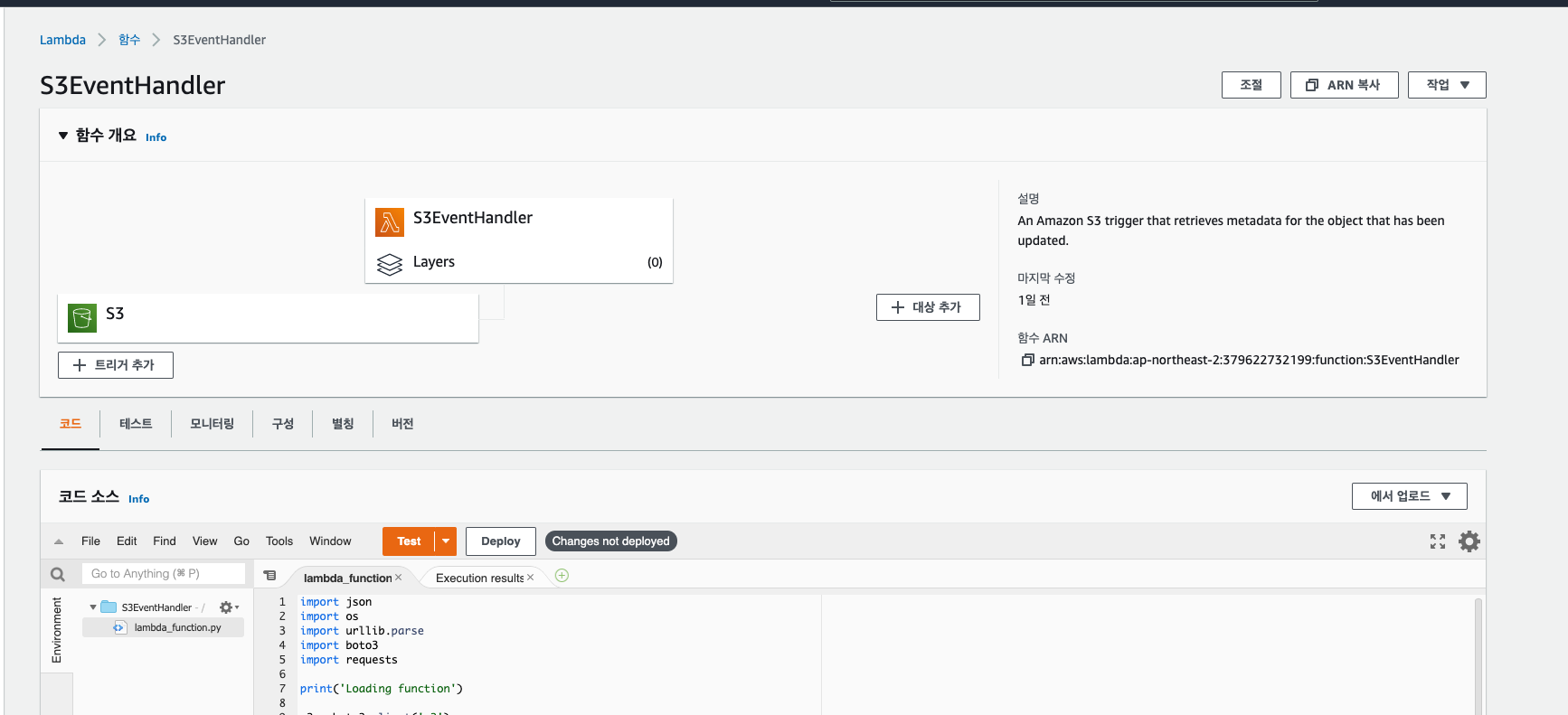
정상적으로 생성이 되었다면 다음과 같은 화면을 확인 할 수 있습니다.트리거로 S3가 적용 되고 샘플로 코드가 생성됩니다.
아래의 코드부분을 수정해 API 서버로 request를 요청합니다. 간단하게 upload 된 오브젝트의 key(경로가 포함된 파일명) 와 bucket 명을 파라미터로 위에서 작성한 API server로 request를 요청합니다. 아래 코드에서 보이는 event는 json 형식으로 함수에 대한 정보를 저장하고 있습니다. event 에서 적절한 정보를 파싱해서 변수로 저장합니다. 이후 Deploy를 클릭해 Lambda를 실행시킵니다.
import json
import os
import urllib.parse
import boto3
import requests
print('Loading function')
s3 = boto3.client('s3')
api_server = 'http://[API-server]:3333/obj'
def lambda_handler(event, context):
bucket = event['Records'][0]['s3']['bucket']['name']
key = urllib.parse.unquote_plus(event['Records'][0]['s3']['object']['key'], encoding='utf-8')
try:
response = s3.get_object(Bucket=bucket, Key=key)
print(f'bucket:{bucket}')
print(f'key:{key}')
resp = requests.post(api_server, json={'path': key, 'bucket': bucket})
print(resp)
print("CONTENT TYPE: " + response['ContentType'])
return response['ContentType']
except Exception as e:
print(e)
print(
'Error getting object {} from bucket {}. Make sure they exist and your bucket is in the same region as this function.'.format(
key, bucket))
raise e
정상적으로 적용했다면 S3에 오브젝트에 업로드 될 때마다 함수가 수행됩니다. 다음과 같이 CloudWatch에서 로그를 확인 할 수 있습니다.아래와 같이 key,bucket 값이 들어왔습니다.
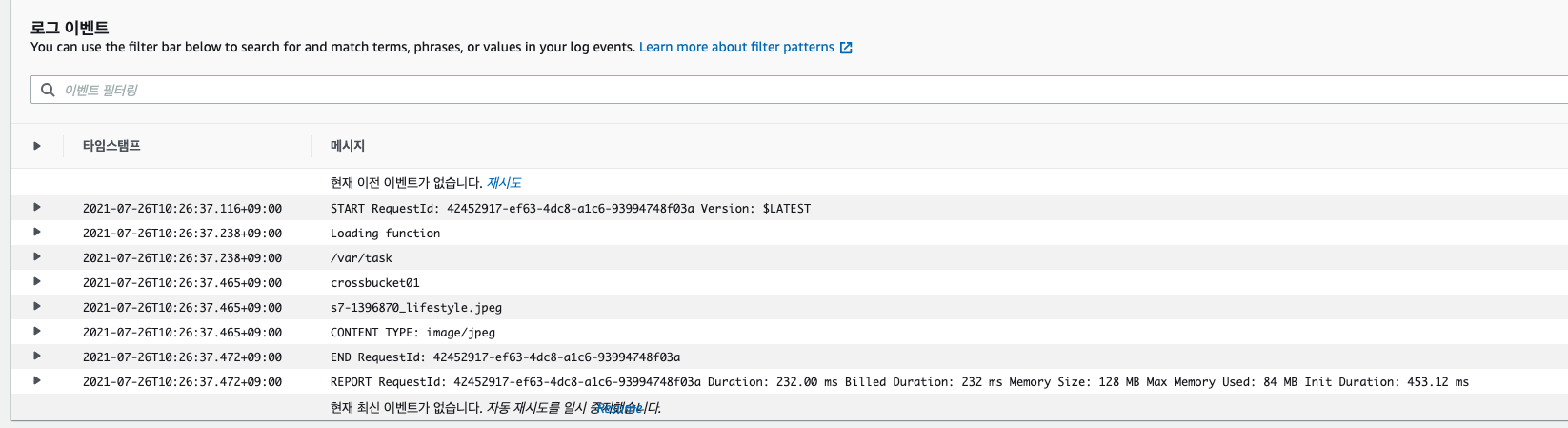
이후 Flask API 서버에서 로그 상에 Request가 들어오고 DB에 정상적으로 csv파일이 dump되는 것을 확인했습니다. 위와 같은 자동화 작업을 진행하면서 lambda의 편리성을 확실하게 느끼긴 했습니다. 서버나 프로젝트 환경에 대한 고민 없이 코드만 작성할 수 있다는 것이 큰 장점입니다. 또한 코드를 작성하고 테스트를 쉽게 할 수 있도록 환경을 구축한 것도 좋았습니다. 하지만 실제 프로젝트 환경을 람다로만 진행 할 경우 한 두개의 함수로 끝나지 않습니다. 천개 단위로 넘어가게 되고 결국 비용 문제가 발생하게 됩니다. 또한 개발을 진행하며 추가 기능이 필요해 구현을 위해 람다뿐 아니라 AWS의 다른 서비스를 사용하게 될 가능성이 높기 때문에(현재도 S3 Trigger를 위해 람다를 사용한 것 처럼) AWS에 지배(?) 될 수 있습니다.
