
2021/12/30
ostep 문서 내용 정리
Intro
SSD (Solid-State Storage)
- SSD는 하드 드라이브와 같은 기계적 또는 움직이는 부품이 X
- 오히려 단순히 메모리와 트랜지스터로 만들어짐
- 일반 랜덤 엑세스 메모리(DRAM)와 달리 SSD는 전력 손실에도 불구하고 정보를 유지하므로 데이터의 영구저장으로 사용하기 이상적임
(NAND based) Flash
- flash 의 두가지 속성
- write하려면 더 큰 chunk 단위를 erase해야함
- 너무 많이 write하면 닳음(wear out)
CRUX
💡 How can we build a flash-based SSD?How can we handle the expensive nature of erasing?
How can we build a device that lasts a long time, given that repeated overwrite will wear the device out?
Will the march of progress in technology ever cease? Or cease to amaze?
44.1 Storing a Single Bit (단일 비트 저장)
- Flash chip은 single transistor 에 one of more bits 를 저장하도록 설계되어있음
- transistor 내에 trapped된 전하(charge) 레벨은 binary 값에 mapping됨
- SLC(Single Level Cell)에서는 single bit만 트랜지스터에 저장됨
- 0 or 1
- 전반적으로 SLC가 더 higher performance, 더 비쌈
- MLC(Multi Level Cell)에서는 두 bit가 서로 다른 전하레벨로 인코딩 됨
- 00(낮음), 01(다소낮음), 10, 11
- TLC(Triple Level Cell)에서는 셀당 3bit를 인코딩함
44.2 From Bits to Banks/Planes
-
Flash chip은 많은 수의 cell로 구성된
bank또는plane으로 구성 됨 -
Bank는 두가지 다른 사이즈의 unit으로 접근 됨Block(erase block 라고도 함): 일반적으로 크기가 128KB or 256KBPage: 크기가 few KB (예 4KB)
-
각
Bank에는 많은 수의Block이 있고, 각block내에는 많은 수의Page가 있음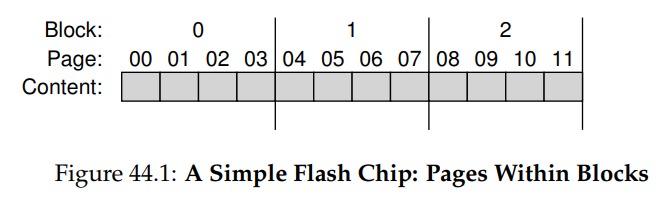
-
Block 내의 Page에 쓰기 위해서는 먼저 전체 block을 지워야 함!!
44.3 Basic Flash Operations
-
Flash Organization에 따라, flash chip이 지원하는 3가지의 low-level 동작이 있음
-
Read (a page)
Flash chip의 client는 장치에 읽기 명령과 적절한 page번호를 지정하기만 하면 어느 페이지(2KB or 4KB)든 읽을 수 있음
이 작업은 수십 마이크로초 단위로 상당히 빠름
이전 요청의 위치를 거의 고려하지 않음 (disk 와 좀 다름)
any location에 균일하게 빠르게 접근할 수 있다는 것은
Random Access Device임을 의미함 -
Erase (a block)
플래시 내의 page에 쓰기 전에 장치의 특성으로 인해 page가 있는 전체 block을 지워야 함
erase는 각 비트값을 1로 설정하여 블록의 내용을 파괴함
So, block에서 신경쓰고있는 data가 erase 하기 전에 다른 곳에 복사되었는지 확인해야함
erase 명령은 상당히 expensive하고, few 밀리초 소요됨
완료되면 전체 블록이 재설정되고, 각 page를 프로그래밍할 준비가 됨
-
Program ( a page)
block이 지워지면, 프로그램 명령어가 page의 일부를 1에서 0으로 변경하고 원하는 page의 내용을 flash에 쓸 수 있음
page를 프로그래밍하는 것은 block을 지우는 것 보다 비용이 적게 들지만, page를 읽는 것 보다는 많이 듦
일반적으로 최신 flash chip에서 약 100s 마이크로초 걸림
-
-
비용:
Erase > Program > Read -
Flash 는 각 page마다 연관 state가 있음
-
Page가 있는 Block을 지우면 상태를
ERASE로 설정함- 그러면, Block의 각 Page내용이 재설정되지만 프로그래밍 가능함
-
Page를 프로그래밍 하면 상태가
VALID로 변경되고- 해당 내용이 설정되고 읽을 수 있게 됨
-
Read는 이러한 state에 영향을 미치지 않음
- (단, 프로그래밍 된 페이지에서만 읽어야 함)
-
Page가 프로그래밍 되면 그 내용을 변경할 수 있는 유일한 방법은 전체 Block을 지우는 것임
-
예시
- 4 page의 block내에 8비트 page가 있다고 가정했을 때, Page 0 에 write를 한다고 가정하면

- Page 0 이 속한 블록 전체를 erase해야 함 (모두 1로 set)

- 이제 write 할 수 있음, Page 0의 내용을 원하는대로 바꿈

- 이렇게 하면 Page 1~3의 내용이 지워져버리기 때문에, 덮어쓰기 전에 변경하고자 하는 data를 다른 위치(메모리, 플래시,...) 로 이동해야함
- 4 page의 block내에 8비트 page가 있다고 가정했을 때, Page 0 에 write를 한다고 가정하면
44. 4 Flash Performance And Reliability
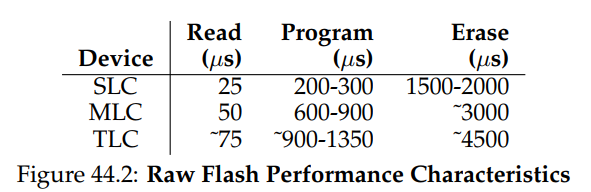
- 표에서 볼 수 있듯, Read latency는 상당히 좋음, 완료하는데 수십 마이크로초밖에 안걸림
- Program latency는 더 높고 가변적이며 SLC의 경우 200마이크로초만큼 낮지만 각 셀에 더 많은 bit를 넣을수록 더 높아짐
- Good Write Performance를 얻으려면 여러 Flash chip을 병렬로 사용해야함
- Erase는 상당히 expensive, 일반적으로 few 미리세크정도 소요 이 cost를 처리하는 것은 최신 flash storage설계의 핵심임
Flash chip의 신뢰성
- 다양한 이유로 고장날 수 있는 기계식 디스크와 달리, Flash chip은 pure silicon 이므로 신뢰성 문제는 별로 없음!
- 주된 문제는
마모(Wear out)임!- flash 블록이 지워지고 프로그래밍되면, extra charge 가 slowly하게 발생함
- 시간 지날수록 extra charge가 누적됨에 따라 0과 1을 구별하는 것이 점점 더 어려워짐
- 불가능하게 된 시점에서 block은 사용할 수 없게 됨
- 블록의 일반적인 수명은 잘 알려져있지 X
-
제조업체는 MLC기반 Block을 10,000번 지워지고 프로그래밍 될 수 있다고 평가함
-
SLC 기반 chip은 transistor당 단일 bit만 저장하기 때문에 일반적으로 100,000 P/E로 더 긴 수명으로 평가됨
(최근에는 예상보다 훨씬 긴 수명을 가진것으로 나타남)
-
- flash 칩의 또다른 신뢰성 문제는
Disturbance(교란)으로 알려져 있음- 플래시 내의 특정 page에 접근할 때 인접 page에서 일부 bit가 뒤집힐(flipped) 수 있음
- 2가지로 구분 됨
- Read Disturbs : 페이지 읽을 때 flipped
- Program Distrubs : 프로그래밍할 때 flipped
44.5 From Raw Flash to Flash-Based SSDs
-
flash 칩의 basic set을 typical storage device로 바꾸는 방법을 생각해 봐야 함
-
standard storage interface는 block address가 주어지면 512byte (또는 그 이상) 크기의 block을 read/write 할 수 있는 simple 블록기반 인터페이스임
-
flash 기반 SSD의 task는 내부의 원시(raw) flash chip위에 해당 표준 블록 인터페이스를 제공하는 것임
-
내부적으로 SSD는 몇 개의 flash chip(영구 저장용)으로 구성 됨
-
일정량의 휘발성 메모리(ex. SRAM)도 포함함
- 테이블 매핑처럼 데이터를 캐싱하고 버퍼링하기에 유용함
-
SSD에는 장치 작동을 조정(orchestrate)하기 위한 control logic을 포함함
- control logic의 필수 기능 중 하나는 read, write를 만족시켜 필요에 따라 내부 플래시 작업으로 전환하는 것 ⇒ Flash Translation Layer(FTL)가 이 기능을 제공함!
- control logic의 필수 기능 중 하나는 read, write를 만족시켜 필요에 따라 내부 플래시 작업으로 전환하는 것 ⇒ Flash Translation Layer(FTL)가 이 기능을 제공함!
-
FTL은 (장치를 구성하는)
logical block에 대한 Read/Write 요청을 받아 기본 물리적 블록과 물리적 페이지에서 low-level의 read, erase, program 명령으로 변환함 -
flash chip을
parallel하게 사용하는 것이 핵심!! -
또다른 performance goal은
write amplification(부가적인 쓰기)을 줄이는 것임!!FTL에 의해 Flash chip에 발행된 total write traffic/Client에서 SSD로 발행된 total write traffic
-
High Reliability 를 얻을 수 있는 방법
Wear out (마모)- Single Block을 너무 자주 지우고 프로그래밍 하면 사용할 수 없게 됨
- 결과적으로 FTL은 flash block 전체에 write를 가능한 균등하게 분산하여 장치의 모든 블록이 거의 동시에 마모되도록 해야함 ⇒ 이렇게 하는 것을
Wear leveling이라 함
Disturbance (교란)- 이러한 disturbance 를 최소화 하기 위해 FTL은 일반적으로 낮은 페이지에서 높은 페이지로 지워진 블록 내의 page를 프로그래밍 함 ⇒ 이
sequential-programming방식은 disturbance를 최소화 하고 널리 사용됨
- 이러한 disturbance 를 최소화 하기 위해 FTL은 일반적으로 낮은 페이지에서 높은 페이지로 지워진 블록 내의 page를 프로그래밍 함 ⇒ 이
44.6 FTL Organization: A Bad Approach
direct mapped라고 불리는 것이 가장 간단한 FTL- 이 접근 방식에서 logical page N의 read는 physical page N의 read에 mapping 됨
- logical page의 write에서는,
- FTL이 먼저 page N이 포함 된 전체 block을 읽고,
- 그 block을 erase해야 함.
- 마지막으로 FTL은 Old page와 New page를 모두 프로그래밍함
- direct-mapped FTL은 성능과 안정성 측면에서 많은 문제가 있음
- 성능 문제는 기록할 때마다 발생함 전체 블록을 읽고, 지우고, 프로그래밍 하는 데 costly함
- 최종 결과는 심각한
Write Amplication임 (block page수에 비례함) HDD보다 write 느림
- data가 급속도로 overwritten 되면, 동일한 block이 계속 지워지고 프로그래밍 되어 빠르게 마모되고 데이터가 손실 될 수 있음 direct mapped 는 클라이언트 workload에 대한 마모에 대해 너무 많은 제어를 제공 ⇒ workload가 write load 를 logical block에 고르게 분산시키지 않으면, 자주 쓰여진 데이터를 포함하는 기본 물리적 블록이 빠르게 마모됨
- 성능 문제는 기록할 때마다 발생함 전체 블록을 읽고, 지우고, 프로그래밍 하는 데 costly함
- 안정성과 성능면에서 direct-mapped는 별로 좋지 않음☹
44.7 A Log-Structured FTL
-
이러한 이유로 요즘 대부분의 FTL은 Log구조로 되어있음
-
이 idea는 storage device와 그 위의 file system 모두에서 유용함
-
logical block N을 write할 때 장치는 현재 write중인 block의 next free spot에 write를 append함
⇒ 이 것을
logging이라 함
-
block의 subsequence read를 allow하기 위해, 장치는 mapping table을 유지
- 이 table은 system에 있는 각 논리 블록의 물리적 주소를 저장함
-
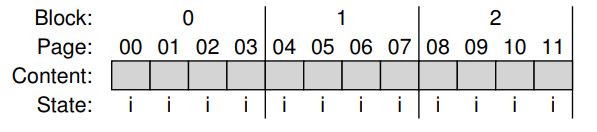
로그기반 작동방식 예제
-
클라이언트에게 이 디바이스는 512Byte sector를 읽고 쓸 수 있는 일반적인 disk처럼 보임
-
클라이언트가 4kB 사이즈의 chunks 를 읽거나 쓴다고 하고,
SSD에 4KB page로 분할된 16KB 크기의 Block이 많이 포함되어있다고 가정하면,
-
모든 page가 INVALID로 mark된 SSD 초기 상태
-
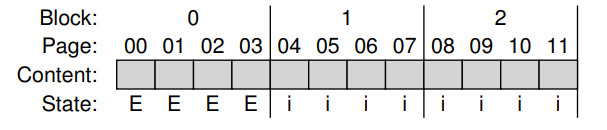
첫 write가 SSD에 의해 수신되면 FTL은 0123 페이지를 포함하는 0번 블록에 쓰리고 결정 후 , 0 번 블록을 erase함 ( 이제 프로그래밍 할 수 있는 상태)
-
대부분의 SSD는 page를 순서대로 기록하므로, program disturbance 와 관련된 안정성 문제가 감소됨
SSD는 logical block 100의 write를 physical page 0에 지시함
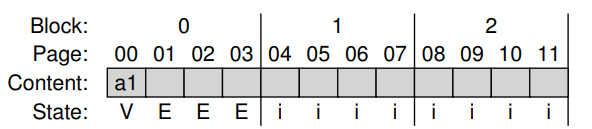
-
Client가 logical block 100을 찾을 수 있도록 물리적 page 0의 read로 변환해야함
이러한 기능을 수용하기 위해 FTL은 논리 블록 100을 물리적 페이지 0 에 쓸 때 이 사실을
메모리 내 mapping table에 기록함
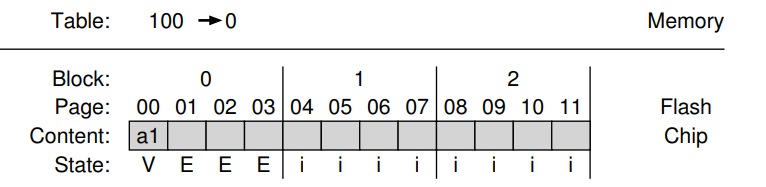
-
- write 완료 이후 상태
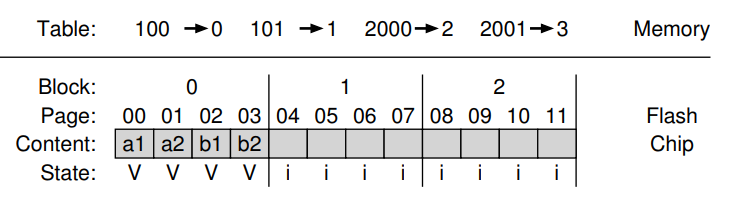
-
-
SSD는 write를 위한 location을 찾고, 일반적으로 블록의 내용이 있는 next free page를 선택하고
logical-to-physical mapping을 mapping table에 record함. -
Log 기반 접근은 본질적으로 성능을 개선하고(간헐적으로만 삭제가 필요하고 직접 매핑 방식의 값비싼 읽기-수정-쓰기 가 방지됨) 안정성이 크게 향상됨
-
FTL은 모든 페이지에 write를 분산하여 wear leveling 작업을 수행하고, 장치의 수명을 늘릴 수 있음
-
Log 구조의 단점
-
논리적 블록을 덮어쓰면 Garbage에 이르게 됨
즉, 드라이브 주변의 오래된 데이터 버전과 공간을 차지하게 됨
- 디바이스는 주기적으로
Grabage Collection(GC)를 수행하여 해당 블록과 향후 write를 위한 여유 공간을 찾아야 함 - 과도한 GC는 Write Amplification을 증가시키고 performance를 저하시킴
- 디바이스는 주기적으로
-
메모리 내 mapping table의 cost가 높음
장치가 클 수록 이러한 table에는 더 많은 memory가 필요함
-
44.8 Garbage Collection
- 이와 같은 로그 구조 접근방식의 첫번째 비용은
Garbage가 생성되고Garbage collection이 수행되어야 함 - 장치의 log 구조적 특성으로 overwritten 은 Garbage Block을 생성하며, 새로운 write를 수행할 수 있는 여유공간을 제공하기 위해 장치가 이를 회수(reclaim)해야 함
- Garbage collection: 향후 사용을 위해 프로세스가 Garbage Block(dead block)을 찾아 회수하는 프로세스
- 동작 과정
- Garbage page를 포함하는 Block을 찾음
- 해당 Block에서 live(non-garbage) page를 READ
- 해당 live page를 log에 Write
- 다음에 사용하기 위해 전체 Block을 회수(reclaim)
- Garbage Collection이 작동하려면
Block내에 각 page가 활성인지 비활성인지 확인할 수 있는 충분한 정보가 있어야 함 ⇒ 각 Block 내 특정 위치에 각 page 내에 어떤 논리 블록이 저장되는 지에 대한 정보를 저장! 디바이스는 매핑 테이블을 사용하여 Block 내의 각 page에 live data가 있는 지 여부를 결정할 수 있음
- Garbage Collection은 실제 data를 읽고 다시 써야 하는 비용이 많이 들 수 있음 ☹️
- 가장 이상적인 reclamation 후보는 dead pages로 구성된 Block : 이 경우는 Block을 즉시 지우고 data migration 없이 새로운 data를 사용할 수 있음
- 가장 이상적인 reclamation 후보는 dead pages로 구성된 Block : 이 경우는 Block을 즉시 지우고 data migration 없이 새로운 data를 사용할 수 있음
- GC cost를 줄이기 위해 일부 SSD는 아래 디바이스를 추가 제공함.
- extra flash 용량을 추가하면 cleaning을 미루고, Background로 push 할 수 있음 device가 less busy한 시간에 완료될 수 있음
- 용량을 추가하면 내부 대역폭(Bandwidth)도 증가하여 cleaning에 사용할 수 있으므로, client에 perceive된 bandwidth이 손상되지 않음
- 많은 장치들이 이러한 방식으로 overprovision을 구현함
- extra flash 용량을 추가하면 cleaning을 미루고, Background로 push 할 수 있음 device가 less busy한 시간에 완료될 수 있음
44.9 Mapping Table Size
- Log 구조의 두번째 cost는 각 4KB page마다 하나의 항목이 있는 매우 큰 mapping table의 잠재적 비용임 ( 1-TB SSD의 경우 4KB당 sigle 4Byte항목으로 매핑에만 1GB 메모리가 필요함 😟) ⇒
page level FTL scheme는 실용적이지 X
Block- Based Mapping
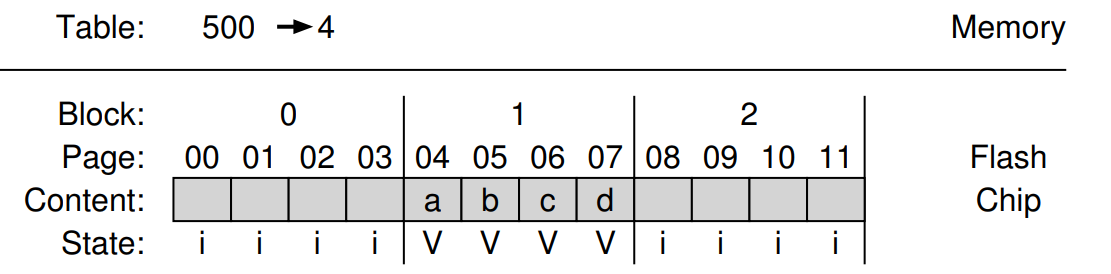

- mapping 비용을 줄이는 방법은 page가 아닌 Block당 포인터만 유지하여 매핑 정보의 양을
블록사이즈 / 페이지 사이즈로 줄임 Block-level FTL은 가상 메모리 시스템 에서 bigger page size를 갖는 것과 유사 : VPN에서 더 fewer bit를 사용하고, 각 virtual address에서 larger offset을 사용
- Log based-FTL 내에서 Block based mapping은 성능 상의 이유로 잘 작동하지 X
- 가장 큰 문제는
Small writing(physical block보다 작을 때) 발생에서 나타남- 이 경우, FTL은 이전 block에서 많은 양의 live data를 읽고 (small write의 data와 함께) 이를 새 block으로 복사해야 함
- 이 데이터 복사는
write amplification을 크게 증가시켜 성능을 저하시킴
- block-level mapping을 사용하는 경우, FTL은 이 모든 data에 대해 single address translation만 기록하면 됨
- 특히 장치의 logical address space가 flash내의 physical block의 chunk로 잘림 ⇒ physical block address 는
chunk number와offset두 부분으로 구성 됨 (4개의 logical block이라 하면, offset은 2bit필요, 나머지 bit는 chunk number)
- 동작 과정
- FTL은 주소에서 client가 제시한 logical block의 최상위 bit를 가져와 chunk number을 추출
- FTL은 table에서 chunk num과 physical-page의 mapping을 찾음
- FTL은 block의 물리적 주소에 논리 주소의 offset을 추가하여 원하는 flash page의 주소를 계산
- Block level mapping은 변환에 필요한 memory양을 크게 줄여주지만, device의 physical block 크기보다 작을 경우 write 할 때 성능 문제 발생
- 장점: page-level mapping에 비해 매핑 size가 작고, sequential write 성능이 좋음 단점: Random Write 접근 패턴에서 잦은 Block copy가 발생해 성능 저하
Hybrid Mapping
-
flexible writing을 가능하게 하면서도 mapping cost를 줄이기 위해 최신 FTL은 Hybrid mapping 사용
-
이러한 접근 방식을 통해 FTL은 몇 개의 block을 지우고, write 를 해당 블록으로 보냄(direct) ⇒
Log blocks∵ FTL은 pure block based mapping 에 필요한 copy없이 log block 내의 모든 위치 page에 쓸 수 있길 원함!!
-
FTL은 논리적으로 2 종류의 mapping table을 가짐
- small set of per-page mapping →
log table - larger set of per-block mapping in
data table
- small set of per-page mapping →
-
특정 logical block을 찾을 때, FTL은 먼저 log table을 참조함
논리 블록의 위치를 찾을 수 없으면 FTL은 data table을 참조하여 위치를 찾고 요청된 데이터에 접근
-
Hybrid mapping 전략의 핵심은
log block의 수를 작게유지하는 것! -
log block의 수를 작게 유지하기 위해 FTL은 log block(페이지 당 포인터 있음)을 주기적으로 검사하고 단일 블록 포인터만 가리킬 수 있는 블록으로 신속하게 switch해야 함
-
FTL은
partial merge(부분 병합)을 수행함

- logical block의 다른 page를 재결합(reunite)하고 single block pointer로만 재결합할 수 있도록 부분병합을 수행
- SSD의 resulting state는 switch merge와 동일하지만, 이 경우 FTL은 목표를 달성하기 위해 extra I/O를 수행하야 하므로
write amplication을 증가시킴
-
full merge(완전 병합)는 더 많은 작업이 필요함
- FTL은 cleaning하기 위해 다른 많은 blocks를 함께 pull 해야 함
- 완전 병합을 자주하면 성능에 손상을 줄 수 있음
Page Mapping + Caching
- 하이브리드 접근 방식의 복잡성을 고려하여, page-mapped FTL의 메모리를 줄이는 더 간단한 방법을 제안함 ⇒ FTL의 활성 부분만 메모리에 cache하여 필요한 메모리 양을 줄임
- 만약 주어진 workload가 페이지의 small set 에만 access하는 경우 해당 페이지의 translation은 메모리 내 FTL에 저장되고 높은 메모리 비용 없이 성능이 우수함!😁
- 만약 메모리가 translation에 필요한 working set을 포함할 수 없는 경우, 각 access는 데이터 자체에 접근할 수 있기 전에 missing된 mapping 을 먼저 가져오기 위해 extra flash read가 minimally하게 요구 됨!☹
- new mapping을 위한 공간을 만들기 위해 FTL은 old-mapping을 제거해야할 수도 있고
- 해당 mapping이 dirty(아직 flash에 지속적으로 기록되지 않은 경우)하면 extra write가 발생하기도 함.
- 하지만 많은 경우에서 workload는 locality를 display하며, 이 캐싱 접근 방식은 memory overhead를 줄이고 performance를 높게 유지함
44.10 Wear Leveling
💡 multiple erase/program cycle은 flash block을 wear out(마모)시키기 때문에 FTL은 해당 작업을 모든 디바이스 블록에 **고르게 분산**시켜야 함!
(몇몇 개만 빨리 unusable 되지 않고, 모든 블록이 거의 동시에 wear out되도록 함)
- Log structuring approach는 write load를 분산시키는 좋은 초기작업을 수행하며, garbage collection에 도움됨
- sometimes, block이 over-written 되지 않고 long-lived data로 채워지기도 하는데, 이 경우 garbage collection은 block을 회수하지 않으므로 write load의 공정한 share를 받지 못함☹ ⇒ 이 문제를 해결하기 위해 FTL은 주기적으로 이러한 block에서 모든 live data를 읽고, 다른 곳에 re-write하여 block을 다시 사용할 수 있도록 해야함
- sometimes, block이 over-written 되지 않고 long-lived data로 채워지기도 하는데, 이 경우 garbage collection은 block을 회수하지 않으므로 write load의 공정한 share를 받지 못함☹ ⇒ 이 문제를 해결하기 위해 FTL은 주기적으로 이러한 block에서 모든 live data를 읽고, 다른 곳에 re-write하여 block을 다시 사용할 수 있도록 해야함
- wear leveling process는 SSD의 write amplication을 증가시키므로 모든 block이 거의 동일한 속도로 마모되도록 하기 위해 extra I/O가 필요하므로 성능이 저하됨
44.11 SSD Performance And Cost
Performance
- HDD와 달리, flash-based SSD는 기계적 구성요소가 없으며, 실제로 Random Access라는 점에서 DRAM과 유사함
- disk drive와 비교할 때, 가장 큰 성능 차이는 random read/write할 때 드러남
- 일반적인 Disk Drive는 초당 수백개의 random I/O를 수행하지만, SSD는 much better👍
-
SSD와 lone HDD의 Random I/O 성능차이

- SSD는 랜덤 I/O에서 수십~수백 MB/s를 얻지만, 고성능 HDD에선 최대 몇 MB/s에 불과함
-
sequential performance 측면에서는 차이가 적음
- SSD가 성능은 더 뛰어나지만 순차적 성능만 봤을 땐 HDD가 더 좋을 수 있음
-
SSD의 random read 성능이 SSD의 write 만큼 좋진 않음
- 예기치 않은 random write performance는 SSD의 log구조 설계로 인해 발생하고, 이는 random write에서
sequential로 변환하여 성능을 향상시킴
- 예기치 않은 random write performance는 SSD의 log구조 설계로 인해 발생하고, 이는 random write에서
-
SSD는 sequential I/O와 random I/O 간의 약간의 성능 차이
Cost
- SSD의 성능은 sequential I/O를 수행할 때도 최신 하드 드라이브를 크게 앞지름 근데 SSD가 10배 더 비쌈......
- 특히 랜덤 읽기 성능이 중요한 경우는 SSD 선택 large data center을 assembling 하고 막대한 양의 정보를 저장하고자 한다면 HDD 유리
