
Bit 란?
컴퓨터가 이해할 수 있는 최소의 정보단위는 0과 1이다.
즉, 컴퓨터는 0과 1로 이루어진 정보들을 처리할 수 있다.
컴퓨터가 처리할 수 있는 가장 작은 단위의 정보를 나타내는 것이 바로 Bit이다.
Bit 는 0과 1만 담을 수 있다.
사람은 10손가락을 이용해서 숫자 1부터 10까지 열 가지 숫자를 다룰 수 있지만 (10진수)
컴퓨터는 0과 1, 즉 신호가 있고 없고 두 가지만 다룰 수 있다. (2진수)
이런 2진수들이 모여서 좀 더 큰 범위의 데이터를 담을 수 있는데
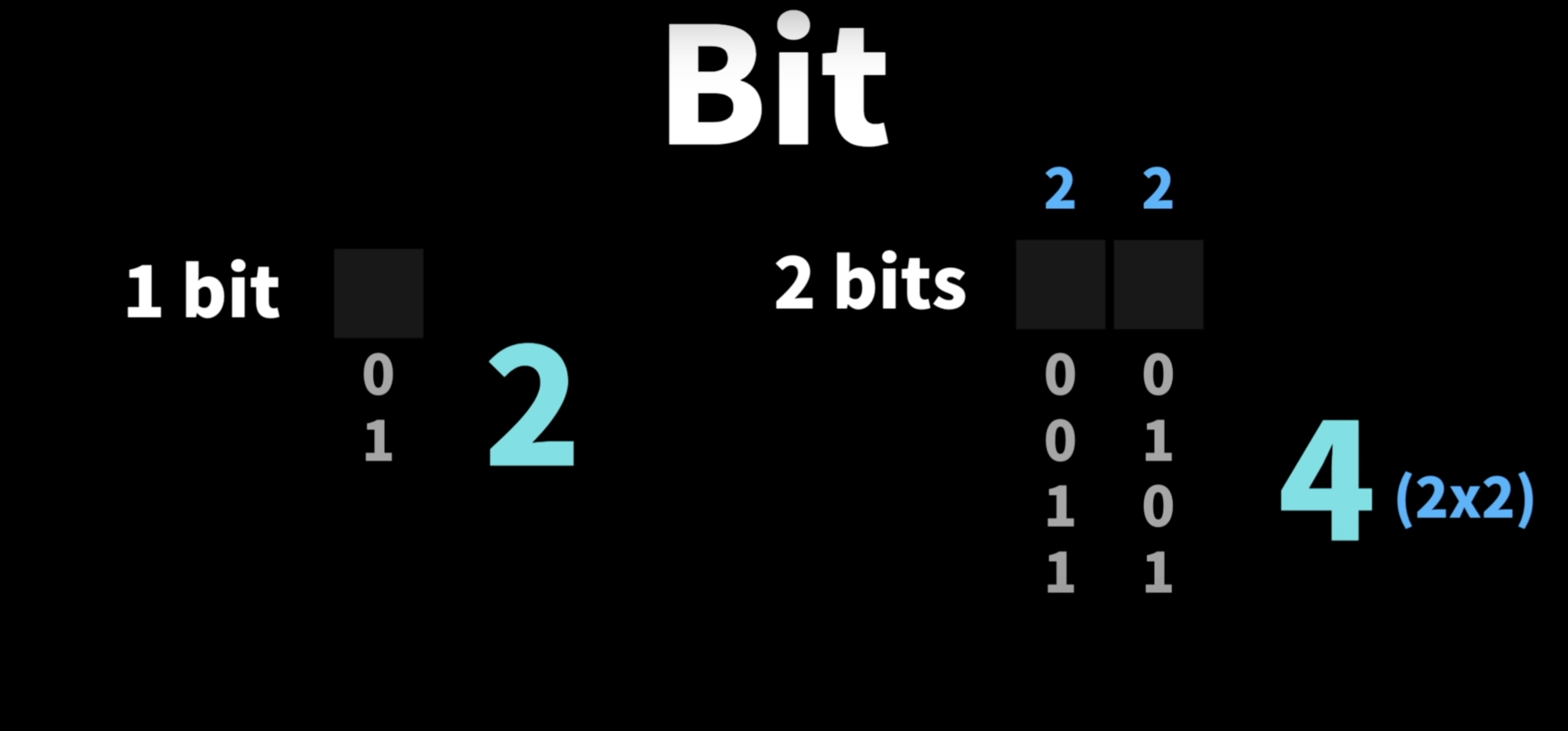
1 bit는 0과 1 두가지만 담을 수 있고
2 bits는 00, 01, 10, 11 총 4가지를 담을 수 있다.
경우의 수 공식을 이용해 보면 한 비트당 2가지 경우를 담을 수 있기 때문에
2*2 = 4 가되어서 총4가지 경우를 나타낼 수 있다.
Byte 란?
1 Byte = 8 Bits
1byte는 8bits로 구성 되어있기 때문에 2의 8승 = 256가지의 다른 정보를 담을 수 있다.
컴퓨터 프로그래밍에서는 1바이트를 가장 최소의 단위로 잡고 본다.
2진수와 10진수 변환
10진수를 2진수로 변환하는 방법
숫자 29를 2진수로 나타내는 방법은?
2로 나눠질 때까지 계속해서 2로 나눠주면 된다!
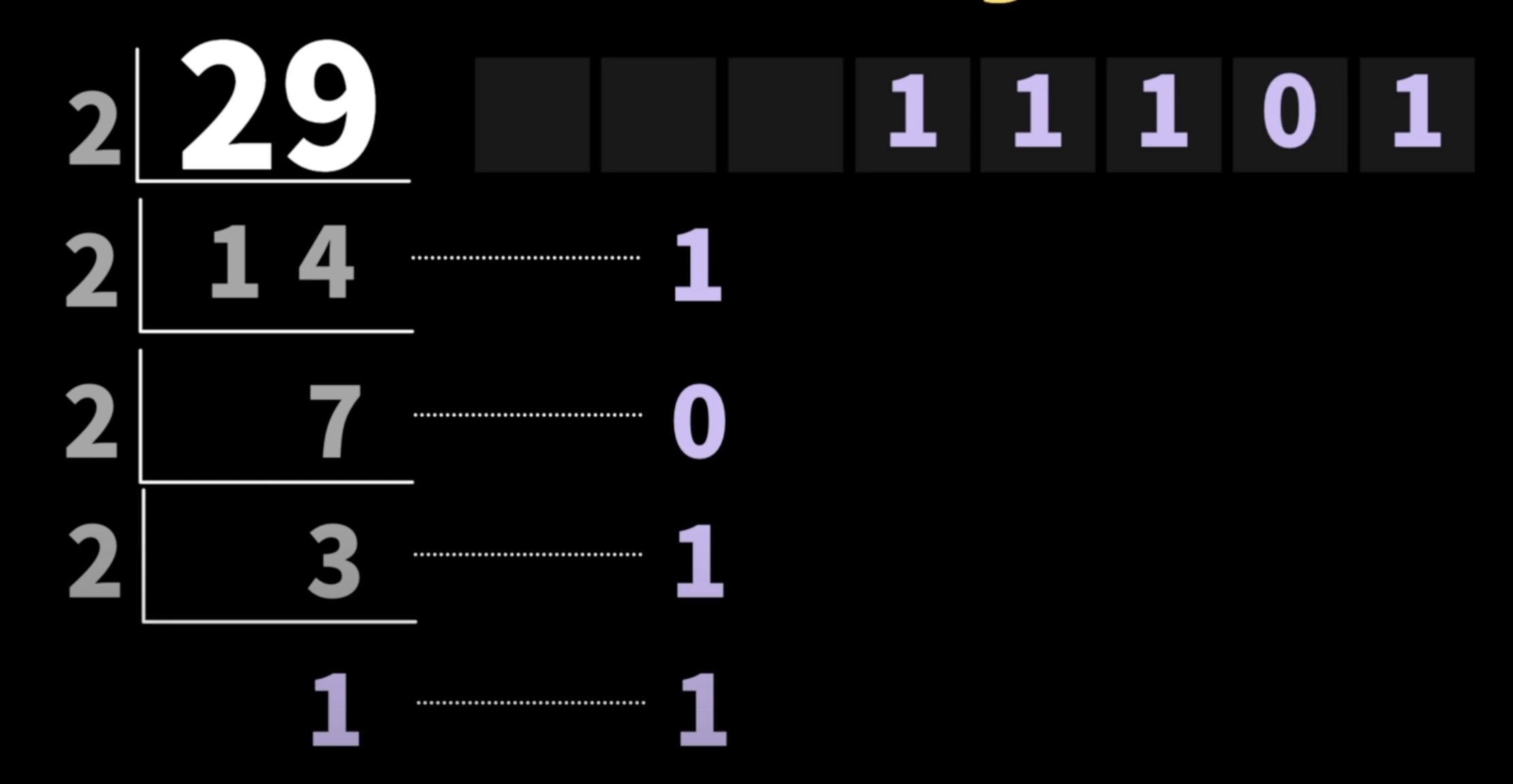
계속해서 2로 나누었을 때 나온 나머지들을 모두 연결하면 2진수로 변환이 가능하다.
2진수를 10진수로 변환하는 방법
각각의 비트의 위치를 2의0승 2의1승 .... 이런식으로 곱한 다음에
곱한 값들을 모두 더하면 2진수로 변환할 수 있다.

문자 코드
문자의 경우 일정한 규칙이 있는게 아니라 사람들이 따로 약속을해 문자 코드를 만들었다.
ASCII 코드
ASCII라는 문자 코드 표를 보면 1000001 = a, 1000010 = b,
이런식으로 정리되어 있는 것을 확인할 수 있다.
이처럼 ASCII 코드는 1바이트로 모든 알파벳을 표현할 수 있다.
ASCII 코드의 한계
하지만 세상에는 굉장히 많은 언어가 있는데 ASCII 코드는 알파벳만 표현할 수 있다는 한계가 있다.
Unicode
ASCII코드와 달리 지구상의 다양한 문자는 물론 심볼과 이모지도 포함한 코드이다.
다만 1바이트에 다 담을 수 없기 때문에 2바이트 또는 그 이상의 바이트로 문자열들을 나타낸다.
이런 비트와 바이트에 대해서 이해하는 것이 왜 중요할까?
프로그래밍에서 변수를 선언할 때 어떤 데이터 타입이냐에 따라서
얼마나 크게 메모리 공간을 확보하는지가 정해진다.
embeded나 메모리가 넉넉하게 확보되지 못한 환경(ex.스마트워치)에서 동작하는 프로그램인 경우
이런 데이터 타입을 알맞게 선택해서 효율적으로 작성하는 것이 중요하다!
1과 같은 한자리 숫자를 담을건데 2바이트나 4바이트인 변수 타입을 사용하면
소중한 메모리가 낭비될 것이다.
메가와 메비의 차이
2진수 단위로 곱해진 사이즈
kilobyte KB = 1024Byte
megabyte MB = 1024KByte
gigabyte GB = 1024MByte
terabyte TB = 1024GByte
주로 운영체제에서 사이즈를 확인할 때 사용됨
10진수 단위로 곱해진 사이즈
kilobyte KB = 1000Byte
megabyte MB = 1000KByte
gigabyte GB = 1000MByte
terabyte TB = 1000GByte
주로 외장디스크나 usb에서 사이즈를 표현할 때 사용됨
2진수와 10진수 차이가 가져오는 문제
사이즈가 작을때는 크게 문제가 되지 않았지만
사이즈가 커질 수록 차이가 커져서 문제가 생기는 경우가 많음
예를 들어 100mb 짜리 usb를 컴퓨터에 꽂아서 보면 95.37mb만 사용할 수 있다고 떠서
사람들이 고소하고 난리남
사실 똑같은 용량인데 2진수 계산법이냐 10진수 계산법이냐에 따라 다르게 표시되는 것인데...
키비? 메비?
이런 혼돈을 잠재우고자 1998년 IEC라는 단체에서 다른 표기법을 제안함
KB와 MB는 기존에 사람들이 쓰던 10진수로 남겨두고
binary 형태로 얘기할 때는 binary의 bi를 따서
kibibyte, mebibyte, gibibyte, tebibyte
로 부르자고 약속을하게 된다.
문자인코딩
문자인코딩 text Encoding이란?
문자를 binary형태로 나타내기 위한 규격
예전에는 나라별로 각각 다른 text Encoding이 존재했는데
서로 다른 인코딩 규격 때문에 웹사이트가 깨지거나 문서가 읽어지지 않는 등의 문제가 많이 발생했다.
UTF-8
위의 문제를 해결하기 위해 나온 것이 바로 UTF-8 인코딩이다.
UTF는 unicode Transformation For mat(8 bit)의 약자이다.
UTF-8은 가변길이 유니코드 인코딩이다.
길이가 정해져있지 않고 필요에 의해 길어질 수 있다는 것을 의미한다.
ASCII 코드는 1바이트로 모든 알파벳을 표현하는 반면
Unicode는 2바이트 ~ 4바이트로 문자열을 표현하기 때문에
UTF-8에서는 1바이트로 데이터를 표현할 수 있다면 그대로 표현하고
만약 2바이트 이상이 필요하다면 첫번 째 덩어리에서 1,0을 앞에다 붙여주고
두번 째 덩어리에서 1,1,0을 붙여주면서 문자를 나타내는데 몇 바이트가 필요한지 힌트를 줄 수 있다.
이처럼 가변길이이기 때문에 바이트가 더 필요하다면
데이터의 범위를 더 늘려서 문자열을 나타낼 수 있다.
UTF-16
이것도 가변길이이지만 기본적으로 2바이트를 사용하고 있기 때문에
1바이트로 충분히 표현할 수 있는 데이터임에도 불구하고 2바이트를 소모하게 된다.
그래서 UTF-16 보다는 UTF-8이 통상적으로 더 많이 사용되고 있다.
