
🐈 서론
3학년 1학기 중간고사가 끝이 났다.
컴퓨터공학과의 3학년은 대학생이 된 이후 가장 재미난 것들을 많이 배우는 학년이면서도, 가장 공부(과제)량이 많아 시간이 부족한 학기인 것 같다.
다시 과제 러쉬가 시작되기 전 잠시 여유가 생긴 지금, 지난 3월 개선했던 웹캣 이야기에 대해 기록한다.
웹캣은 서강대학교의 다양한 공지사항을 등록 1분 안에 알려주는 Slack 봇이다.
개인적으로 필요해 개발했으나 다른 학우들에게도 필요할 것을 느껴 공개했고, 현재는 약 80명의 학우들이 유용하게 사용하고 있다.
관련 포스트
Github 주소
작년(2022) 하반기에 위 포스트에 기록한 대로 개발해 공개했으나, 성능 상 다양한 문제가 있었다.
올해 3월 다양한 리팩토링을 거쳐 현재는 관리 소요 거의 없이 알아서도 잘 동작하는 서비스가 되었다.
본 포스트에서는 이 리팩토링을 통한 성능 개선 과정과 결과를 소개한다.
🐈 문제 상황, 개선 결과
어떤 문제가 있었고, 개선 후 어떻게 변했는가?
🐾1. 70% 정도의 낮은 Availability(가용률) → Uptime 99.99%로 개선
기존 웹캣의 아키텍쳐는 파이썬 스크립트를 스케쥴러(Cron)가 직접 실행하는 형식이었다. 모든 자원을 공유하는 하나의 서버 위에서 각각 다른 페이지를 크롤링하는 스크립트 간 충돌이 잦았고, 오류가 발생하면 서버에 접속해 수동으로 해결해 주어야 했다. 매 순간 서버를 모니터링하기 어려워 가용률이 70% 정도로 비교적 낮았고, 관리 리소스 또한 많이 들었다.
=> 도커 컨테이너 기반으로 리팩토링해, 관리 리소스 없이 Uptime을 99.99%를 보장할 수 있도록 자동화했다.
🐾2-1. 높은 컴퓨팅 리소스 → 사용 CPU resource 45% 개선
매 분 각 스크립트를 실행할 때마다 Chrome Selenium을 새로 실행하고, 비교하고, 저장하고, 종료하는 작업을 반복하는 데에 필요 이상의 리소스가 사용되고 있었다. 기존 AWS의 EC2 내 t2.micro 인스턴스(프리 티어 지원)를 사용했는데, 5개 페이지에 대한 감시만 수행해도 CPU 리소스의 20%를 사용했다.
=> 하나의 스크립트가, loop 내에서 각 페이지에 대한 감지를 하루 종일 수행하도록 변경하여, 기존과 비교해 55%의 리소스만 사용하도록 개선했다.
하루에 1440번 프로그램을 실행시키는 것이 아닌, 하루에 프로그램은 1번만 실행해 무거운 Chrome Selenium도 스크립트 당 1번만 실행시키고, 각 페이지의 데이터는 자료구조 내에서 계속 갖고 있도록(DB 따로 저장 X) 변경해 사용 리소스(컴퓨팅 파워)를 절반 가량 줄였다.
🐾2-2. 낮은 확장성 → 확장성 개선
기존 CSS Selector 기반의 크롤링 시, 감지하려는 공지가 위치한 HTML tree 구조 (예: 'div.list_box > ul > li > div > a.title')가 페이지마다 달랐다. 따라서 새 페이지를 추가하려면 매번 개발자 도구를 열어 해당 구조를 찾아야 했고, 새 detector를 추가하기 위한 리소스가 컸다.
특히 한두 달이 지나고 학교 코드의 구조를 잊어갈 때 쯤 다시 새 페이지를 추가하려고 하면 다시 코드에 적응하는 데 시간이 들었다.
=> 웹 브라우저 내 요소 변경을 XPATH 기반으로 감지하도록 리팩토링해, 확장성과 유지보수성을 크게 개선했다.
🐾3. 매 달 9만원의 클라우드 서버 이용료 → 자체 서버 구축, 운영 비용 무료화
1년간 무료인 NCP의 Micro-g1 서버와 AWS t2.micro 서버로 부족해, 90일간 30만 원의 무료 크레딧을 지급하는 GCP의 e2-standard-2 Compute Engine으로 이주해 서비스를 운영했으나, 얼마 전 무료 제공 크레딧을 거의 다 사용했다.
해당 Compute Engine을 계속 사용하려면 1달에 9만원 정도의 비용이 발생했다.
=> 지속 가능한 무료 서비스 제공을 위해 현재는 사무실에 교내 인터넷 망을 사용하는 자체 linux 서버를 구축했고, 클라우드 서비스 사용비 없이 서비스를 제공할 수 있게 되었다.
🐈 개선 과정
위 문제들을 어떻게 개선했는가?
🐾1. Docker 컨테이너 기반의 리팩토링
=> 도커 컨테이너 기반으로 리팩토링해, 관리 리소스 없이 Uptime을 99.99%를 보장할 수 있도록 자동화했다.
가장 큰 문제는 충돌이 발생할 때마다 매번 다른 에러가 원인이었기 때문에, 에러 발생 시 해결 자동화가 어려웠다.
매번 브라우저를 열어 네트워크로부터 데이터를 읽어 오고, 또 사이트마다 구조가 달랐기에 잘 수행되다가도 예상치 않은 오류가 빈번하게 발생하곤 했다.
가상화폐 트레이딩 봇을 개발하는 회사에 다니는 친구에게 조언을 구했고, 친구네 회사에서는 도커를 사용해 24시간 봇을 쉬지 않고 작동시킨다는 사실을 알아냈다.
웹캣에서도 도커를 활용하면, 각 스크립트가 서로 서버 리소스를 공유하지 않는 독립된 공간에서 실행되게 할 수 있고, 충돌 발생 시 컨테이너를 재시작하기도 용이했다.
Selenium으로 인해 스크립트 간 충돌이 자주 발생하는 내 상황 속 완벽한 해결책이었다.
각 페이지에 대한 Detector를 하나의 컨테이너에서 관리할 수 있도록 구조를 수정했고, Cron 스케쥴러에서는 도커 컨테이너 실행 스크립트, 도커 컨테이너 종료 스크립트를 하루에 한 번만 실행하도록 수정했다.
도커 컨테이너 실행 스크립트는 아래와 같이 --restart always 옵션을 적용해 오류가 발생해 종료되는 경우 자동으로 재시작하도록,
도커 컨테이너 종료 스크립트는 정해진 시간에 모든 컨테이너를 종료하고 삭제하도록 구성했다.
# 도커 컨테이너 실행 스크립트
docker run -d --restart always seewon/webcat-a-academic &
# 도커 컨테이너 종료 스크립트
docker stop $(docker ps -a -q) && docker rm $(docker ps -a -q)
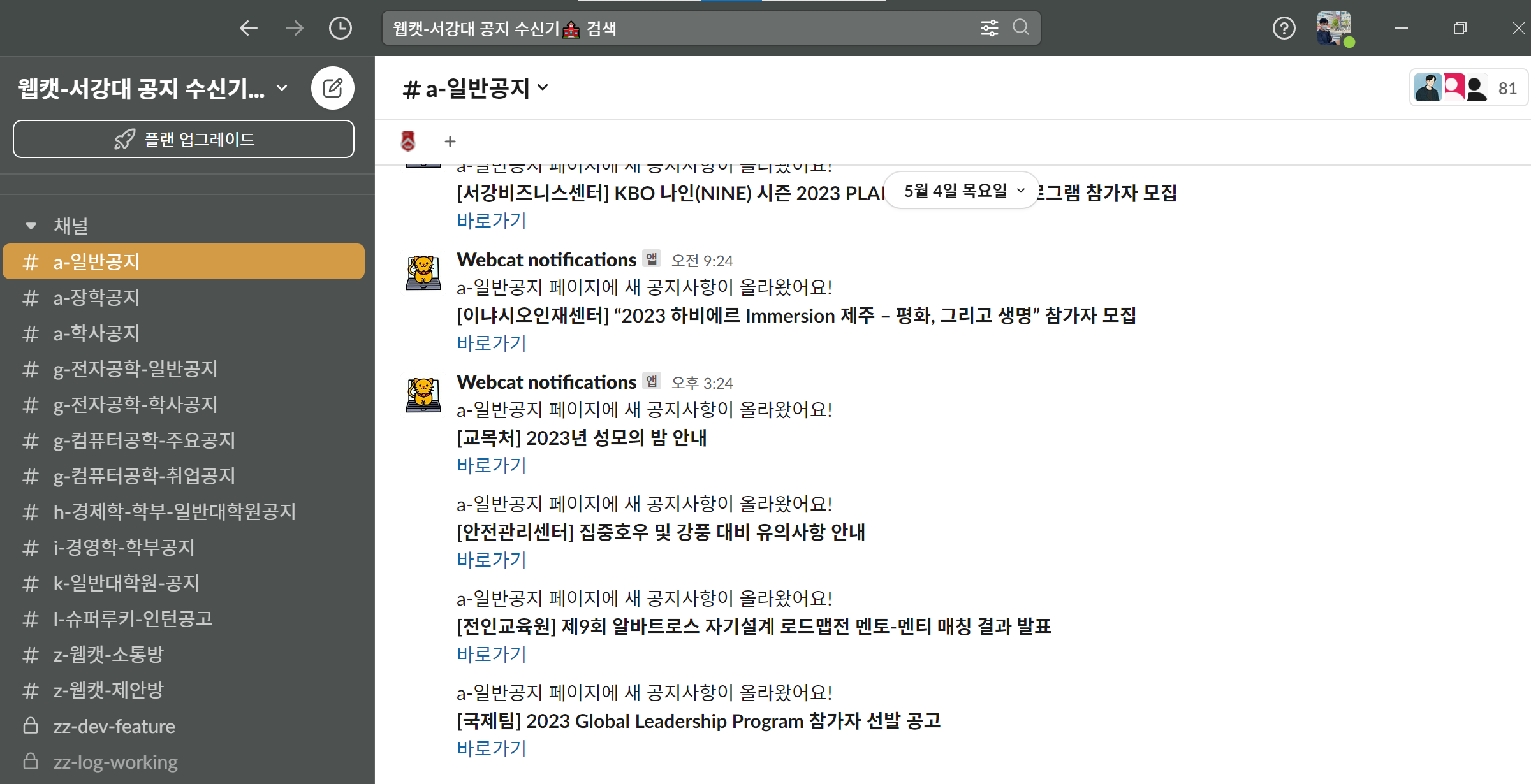
아래 캡쳐처럼 실행 중인 Detector의 개수만큼 컨테이너가 실행되도록 구현했고, 도커 기반 리팩토링 덕에 배포 환경 관련 설정 또한 아주 편해졌다.
실제로 최근 서버를 GCP에서 자체 서버로 마이그레이션했는데, 옮기는 데 10분 정도밖에 걸리지 않았다😁
🐾2. 전반적인 수행 로직 리팩토링
🧶loop 기반의 리팩토링
=> 하나의 스크립트가, loop 내에서 각 페이지에 대한 감지를 하루 종일 수행하도록 변경하여, 기존과 비교해 55%의 리소스만 사용하도록 개선했다.
학교 컴퓨터 아키텍쳐, 멀티코어 프로그래밍 같은 시스템 수업에서, 디스크에 read, write하는 연산은 expensive하다는 것을 배웠다. 웹캣 또한 어차피 데이터를 갖고 있다가 1분 뒤에 다시 사용하는데, 매 번 데이터를 저장하고 읽어들이는 과정은 불필요하다는 것을 깨달았다.
기존 방식에서는 사실 스크립트를 매 분 새로 실행하는 방식이었기 때문에, 데이터를 따로 저장해 두는 것이 불가피했다.
이번에 도커 기반 리팩토링을 수행하면서, loop 안에서 반복하며 데이터를 비교하는 식으로 로직 또한 수정했다.
데이터를 파이썬 dictionary 자료구조에 저장해 비교했고, 전체 로직은 아래 20줄 가량의 코드로 모두 설명할 수 있을 정도로 간단하게 수정되었다.

웹캣에서는 현재 C/C++와 같은 코딩 스타일로 파이썬 dictionary 자료구조를 전역 변수로 관리하는데,
수강 중인 수업 프로그래밍 언어 의 관점에서, 좀 더 Pythonic한 스타일로 개선할 여지가 있을 것 같다.
데이터를 외부에 저장하지 않아, 형식에 맞춰 포맷팅해 저장하거나 읽어와 파싱하는 과정 또한 필요 없어졌다.
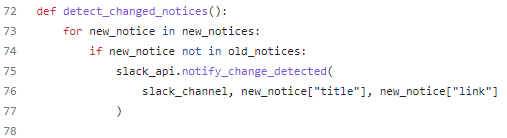
이에 따라 데이터 변화 감지 로직 또한 간단해졌는데, set 기반의 in, not in을 통한 연산으로 쉽게 새로 등록된 공지를 감별해낼 수 있었다.
🧶XPath 기반 리팩토링
=> 웹 브라우저 내 요소 변경을 XPATH 기반으로 감지하도록 리팩토링해, 확장성과 유지보수성을 크게 개선했다.
CSS 선택자 대신 XPath 기반으로 데이터를 스크래핑할 수 있도록 수정했다.
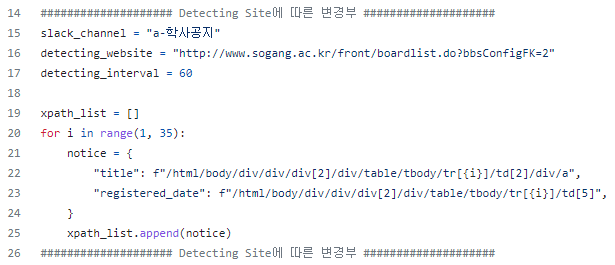
공지사항은 모두 페이지 내부 규칙적인 위치에 저장되므로, 아래와 같이 XPath 상 해당 공지 몇 건의 위치만 확인하면 쉽게 모든 공지의 경로를 파악해 읽어올 수 있게 되었다.
스크립트 파일의 가장 위에 감지하는 사이트마다 달라져야 하는 데이터를 입력할 수 있게 했더니, 코드를 잊어버린 몇 달 후에도 새로운 페이지를 추가하기 용이했다.
여담으로, 학교 사이트들은 사실 대부분 템플릿이 동일해 공지사항들의 XPath 상 경로도 거의 동일했다.
현재는 새로운 감시 채널을 위한 스크립트 생성부터 배포까지 10분 내외의 시간이 소요되는 것 같다.
🧶Dependency 최적화
구글에 Python save dependencies를 검색하면, 대부분 pip freeze를 활용해 패키지 의존성을 저장한다. 나도 그렇게 해보았으나, requirements.txt에 100개에 육박하는 의존성 라이브러리가 포함된 것을 확인하게 되었다.
분명 웹캣을 개발하며 사용한 라이브러리는 5개 내외였던 것 같은데, 컨테이너 별로 이렇게 많은 의존성 라이브러리를 설치해 운영하자니 부담되어 최적화 방안을 찾았다.
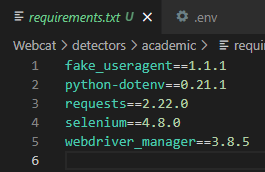
스크립트 내에서 import한 라이브러리만 dependency로 추가해 주는 pipreqs 라이브러리를 발견했고, Dockerfile에서 개발에 사용한 5개의 라이브러리만을 내려받아 웹캣을 사용할 수 있도록 했다.
🐾3. 자체 서버 구축
=> 지속 가능한 무료 서비스 제공을 위해 현재는 사무실에 교내 인터넷 망을 사용하는 자체 linux 서버를 구축했고, 클라우드 서비스 사용비 없이 서비스를 제공할 수 있게 되었다.
웹캣은 수익이 아닌 학우들의 편의를 목표로 하는 프로젝트이기 때문에, 클라우드 서버로는 비용 상 운영에 한계가 있었다.
그리고 마침 좋은 기회로 학교에서 지원을 받아 사용 중인 사무실이 있었기에, 사무실에 서버를 구축하기로 마음먹었다.
다양한 공부를 해보면서 꼭 서버를 직접 구축해 보고 싶은 욕심도 있었다.
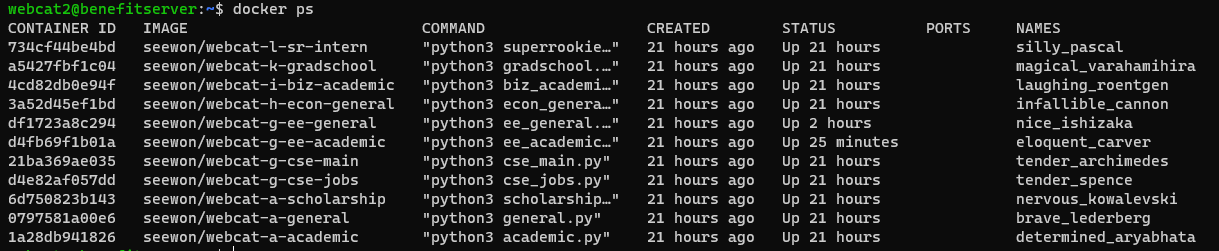
하드웨어 스펙(코어/메모리 등) 결정부터 조립, OS 설치, 네트워크 설정, 방화벽 구축 등의 과정을 전부 직접 해보며 리눅스 시스템에 대한 이해도를 크게 올릴 수 있는 좋은 경험이었다 :D
서버 구축-셋팅에 대한 내용은 풀자면 내용이 길어질 것 같아, 기회가 될 때 글로 옮겨 보려고 한다.
웹캣은 내가 졸업하기 전 2년 정도 동안은 개인 서버에서 운영하고, 그 후에도 오랫동안 학우들이 이용할 수 있도록 몸담고 있는 학회의 서버로 이관할 예정이다.
🐈 앞으로는 어떻게?
이제 서비스를 안정적으로 운영할 수 있는 시점이 되었다.
지금은 추가적인 성능 개선보다, 사용자를 늘릴 시기라는 생각이 든다.
분명 필요한 서비스를 만들었고, 홍보 글 한 번으로 80명의 유저(재학생의 1%)를 획득했다.
지난 몇 달 간 지속적으로 서비스를 이용하는 유저가 많은 것도 확인했다.
이제는 마케팅에 리소스를 투입해 적극적으로 서비스를 알리면 좋을 것 같다😁
재학생의 약 15%에 해당하는, 유저 1,000명 확보를 목표로 운영해 봐야겠다!
개발 이야기가 아닐 수도 있지만, 앞으로의 과정도 천천히 기록해 봐야겠다 :D

9개의 댓글


재밌게 잘 읽었습니다!!👍
포스팅 내용 중 한 가지 질문 드리고 싶은 내용이 있어요!
각 페이지의 데이터는 자료구조 내에서 계속 갖고 있도록(DB 따로 저장 X) 변경해 사용
- DB에 저장하지 않으면 서버가 재시작 되는 사이 변경되거나 새로운 공지는 어떻게 체크 하게끔 구현 하셨는 지 궁금합니다..!

고민을 하고, 기술을 사용하는 것이 정말 중요하다고 생각하는데, 그러한 점들이 보여서 좋았습니다! 시원님 응원할게용ㅎㅎ 근데 깃헙 링크도 같이 올려주시면 더 좋을 것 같아요😀