초기 개발 목표 (23.04)
취업 준비를 하는 중에 ChatGPT를 모의면접을 하는 것처럼 사용해봤는데 꽤 괜찮았다.
하지만 ChatGPT로 모의면접을 진행하기 전에 해야하는 사전 프롬프트 설정이 힘들었다.
그리고 힘들게 설정해도 대화를 계속 이어나가면 GPT가 프롬프트 설정을 계속 잊어버렸다.
이 문제를 해결하기 위해 프롬프트 설정 없이 ChatGPT로 모의면접을 볼 수 있는 서비스를 만드려 했지만,
팀프로젝트를 진행하게 돼서 나중에 따로 만들어 보겠다고 생각했다.
개발 시도 (23.12)
진행하던 팀프로젝트가 우여곡절 끝에 끝나게 됐다.
하지만 이 프로젝트로 내가 원하던 경험을 얻지는 못한 것 같고,
취업 준비 기간도 길어져서 조급함을 많이 느꼈다.
집중을 못했다.
그래서 프로젝트에 온전히 집중하지 못하고, 이력서를 다시 작성해보고, 자소서를 쓰고, 지원서를 내는 등의 구직활동을 했다. 물론 결과는 좋지 못했다.
그래도 짬짬이 어떻게 구현할지를 생각해보고, ChatGPT와 연동해보는 등 개발을 완전히 놓지는 않았지만 확실히 진행속도가 굉장히 느렸다.
다양한 분야의 지원
초기 개발 목표는 굉장히 단순해서 기능도 단순해서 다음과 같은 기능을 제공해주면 됐다.
- 사용자 대화 기록에 모의면접을 진행해주는 프롬프트를 얹어주기
- 대화기록을 저장하고 보여주기.
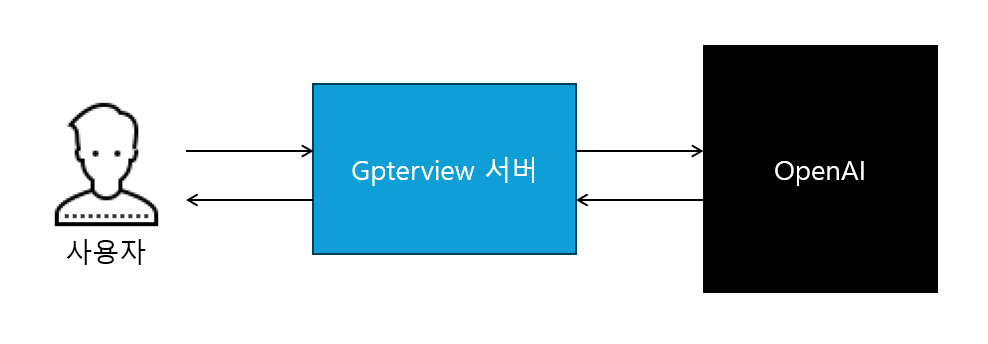
내가 구상한 서비스는 단순한 채팅같은 구조였다.
그래서 DB구조도 대화기록을 하나의 테이블에 전부 저장해놨다.
성급했다.
이 구조에서 IT, 디자인, 영업 등등의 다양한 분야에 적절한 프롬프트를 만들어놓기만 하면,
여러 분야의 지원자들도 문제없이 사용할 수 있다고 생각했다.

여러 분야를 지원하기 위해서 사진과 같이 면접관의 면접전략이라는 것을 인터페이스로 만들었다.
그리고 Spring DI와 다형성을 활용하여 면접 지원자의 분야에 따라, 기존 코드를 재사용하면서 프롬프트를 제공하도록 만들고 싶었다.
이 부분은 기능 자체가 단순한 초기 개발 목표에서는 알맞았다.
이후 개발 목표가 수정되면서 추상화한 부분이 수정 및 리팩토링에 걸림돌이 되었다.
나는 개발초보이기 때문에 시작을 완벽하게 할 수 없다.
모든 걸 완벽하게 생각할 수 없고, 개발을 하면서 옳다고 생각한 부분도 바뀌게 된다.
그렇기 때문에 처음 생성한 코드가 나중에는 무조건 수정된다.
하지만 이렇게 인터페이스를 통해 추상화하고 여러 구현체를 만들어 놓는다면,
나중에 인터페이스를 수정할 때 구현체를 전부 변경해야 돼서 힘들어진다.
만약 다시 돌아간다면 인터페이스보다 한 분야라도 제대로 개발해서 전체적인 개발을 끝내 놓고,
추상화와 다형성을 통한 확장성을 고려해보는 식으로 개발할 것이다.
OpenAI 스토어 등장(24.01)
OpenAI에서 프롬프트 설정없이 사용자들이 미리 설정해놓은 프롬프트를 기반으로 ChatGPT를 사용할 수 있는 OpenAI 스토어가 출시됐다.
이제 사용자들은 프롬프트를 직접 설정할 필요가 없이, 다른 사람이 만들어 놓은 것을 가져다 바로 쓰면 되는 것이다.
그럼 내가 만들던 서비스는?
참 얄궃게도 내가 만들던 서비스가 딱 이 역할을 하려 했다.
변화가 필요했다.
그래서 이 시기에 나는 OpenAI 스토어와 나의 서비스의 차별점이 무엇인지,
차별점이 없다면 어떤 차별점을 두어야할지에 대해서 고민해봤다.
프로젝트 방향성 틀기(24.01~02)
OpenAI 스토어와 비교해서 내가 만들고자 하는 서비스가 어떤 차별점가질 수 있는지 고민해본 결과는 다음과 같았다.
- 면접 질문과 답변 데이터를 나의 서비스에서 가지고 있다.
- 면접 질문과 답변 데이터를 컨트롤 할 수 있다.
- 요금이 필요하지 않다.
면접 질문과 답변
결국 내 서비스에 저장된 면접 질문과 답변 데이터들을 기반으로 어떻게 서비스할지를 생각해봐야 했다.
GPT 문제 : 같은 질문 패턴이 반복된다.
이때 내 서비스로 모의면접을 몇 번 돌려보며 OpenAI ChatGPT 3.5의 문제를 발견했다.
=== 모의면접 시도 1 ===
ChatGPT : 사과는 어떻게 생겼나요?
지원자 : 동그랗고 빨게요.
ChatGPT : 그러면 바나나는 어떻게 생겼나요?
=====================
=== 모의면접 시도 2 ===
ChatGPT : 사과는 어떻게 생겼나요?
지원자 : 동그랗고 빨간 것 같아요.
ChatGPT : 그러면 바나나는 어떻게 생겼나요?
=====================사용자 정보와 대답이 유사하다면 같은 질문 패턴이 반복됐다.
사용자가 같은 질문이 반복되는 것을 느끼면 지루함을 느낄 수 있을 것이라 생각했고,
이 문제를 해결해봐야 겠다고 생각했다.
저장된 질문 추천(TF-IDF, 문자 토큰화)
인터넷에서 추천에 대해서 알아보면서 협업 필터링 컨텐츠 기반 필터링 등을 활용한 추천 시스템을 볼 수 있었다.
근데 나는 오픈소스가 끼어든 거창한 시스템보다 소규모에서 적절하게 해결할 수 있는 방법을 쓰고 싶었다.
오픈소스가 끼어들면 프로젝트 기간이 더 길어질 것 같았고,
직접 구현하는게 더 재밌고 배울 점이 많을 것 같았다.
결과적으로 나는 다음과 같이 구현했다.
| DB내 질문 목록 |
|---|
| 사과는 어떻게 생겼나요? |
| 바나나는 어떻게 생겼나요? |
| 수박도 안은 빨간데. 수박은 먹어봤어요? |
- 질문을 저장할 때 (질문 내용 + 한글 토큰화 결과) 저장.
- 사용자의 마지막 대답 가져오기 -
빨간 것 같아요.- 사용자의 마지막 대답 토큰화 - ex)
빨,간,것,같아,요- DB에서 질문들을 가져오기
- 한글 토큰화 정보와 TF-IDF를 활용해 사용자의 대답과 DB 질문의 유사도 평가
- 규칙에 따라 가중치 점수를 주어 질문들의 추천 점수 계산
ex) 규칙:TF-IDF 결과,비슷한 주제를 다루고 있는지,앞선 질문의 꼬리질문인지등등...- 상위 점수의 질문 추천 ->
수박도 안은 빨간데. 수박은 먹어봤어요?
질문 토큰화 과정만 형태소 분석기 라이브러리를 사용했다.
기술적인 내부 구현은 따로 글을 작성하도록 하고, 이 글에서는 흐름만 써놓는다.
요금이 필요하지 않다?
이 부분은 서비스 사용자는 요금을 낼 필요가 없다는 것이다.
결국 서버를 운영하는 나는 OpenAI API를 사용하기 위해서는 요금을 지불해야 한다.
그래서 기존 DB에서 질문을 추천하는 기능이 중요했다.
이 기능을 통해 질문 패턴의 반복 문제를 해결하고, OpenAI 요금을 절약해서 두 마리 토끼를 잡으려고 했다.
개발 집중(24.02~)
이제 이 요구사항들을 바탕으로 세부적으로 구현 및 수정에 집중했다.
앞서 성급했다. 부분에서 언급한 부분으로 인해서 코드 수정이 배로 힘들어 졌다.
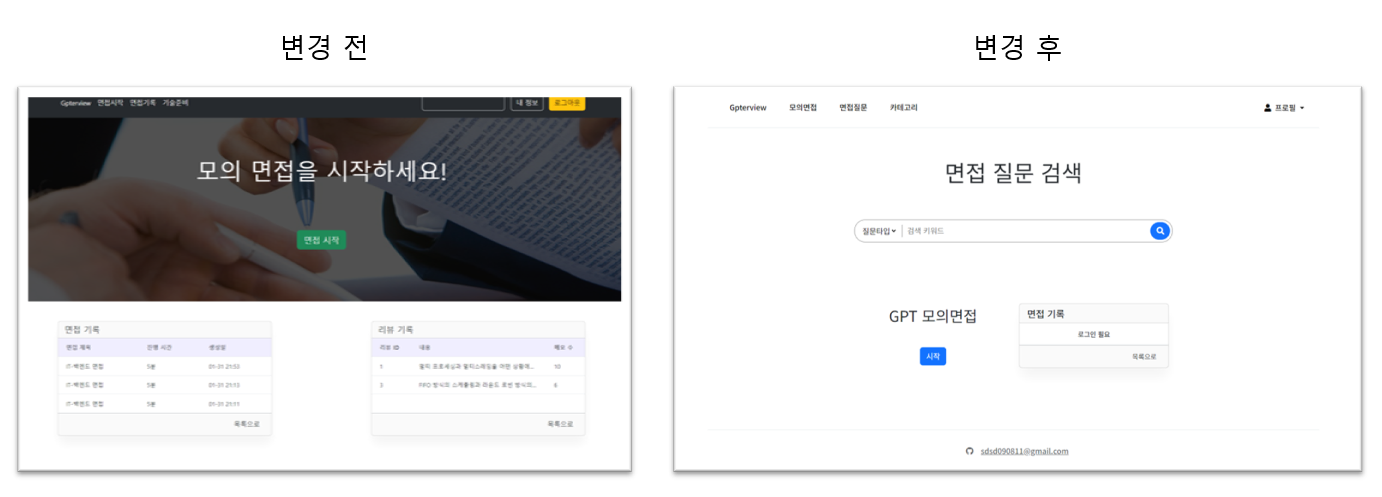
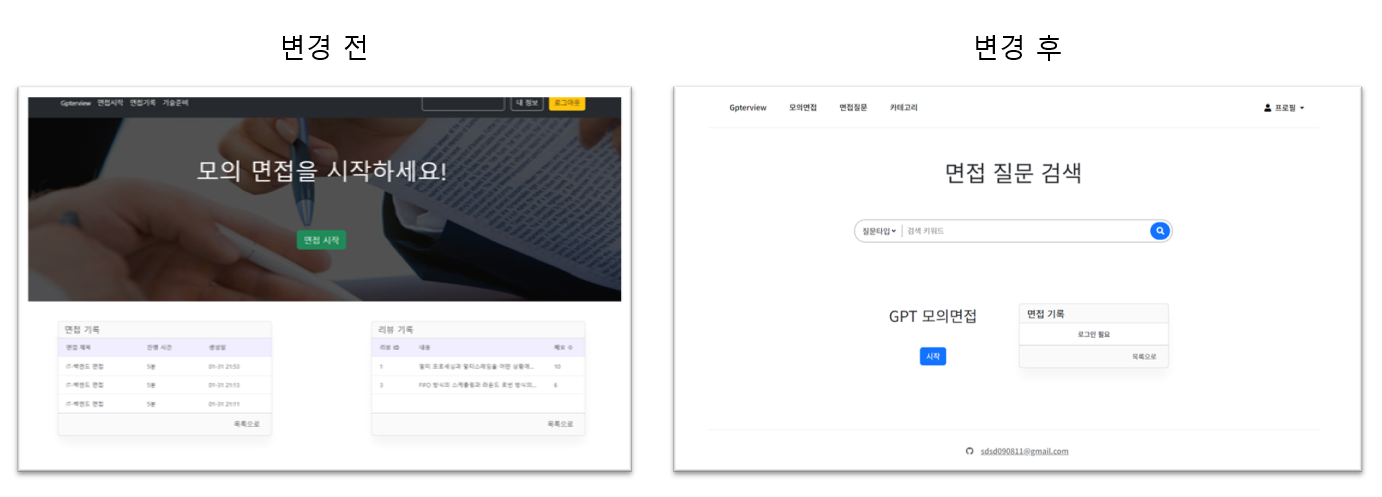
화면 구성 변경
아무리 기능이 좋아도 사람들은 예쁘지 않으면 쓰지 않는다.
화면 구성을 변경했다. 아직도 별로긴 하지만 전보다는 좋아졌다.
DB 구조 변경하기
기존 질문을 추천하기 위해서는 채팅처럼 하나의 테이블을 사용하는 DB구조는 적절하지 않았다.
이 내용은 이전에 쓴 내용이 있어서 넘어가도록 하겠다.
가지고 있는 정보를 더 활용하자.
초기 개발 목표는 OpenAI 서비스에 부가기능 서버였던 것 같다.
하지만 지금 이렇게 개발 방향을 좀 틀어서 개발하다보니,
질문 검색 기능 등등 추가할 사항들이 더 보이기 시작했다.
배포하기(24.05)
https://gpterview.site/
처음으로 도메인을 연결하고 HTTPS를 직접 적용해봤다.
그리고 github-action과 codedeploy를 통해서 배포 자동화를 구현했다.
아직 진행중
혼자 프론트엔드와 백엔드를 모두 작업하다보니 부족한 부분이 많이 보이고,
아직 validation과 오류 처리등의 작업이 안되어 있다.
그래서 계속 수정과 기능 추가를 반복하고 있다.