멀티 프로그래밍

메모리 할당을 다루기 전 멀티 프로그래밍에서의 메모리를 생각해보자.
여러 프로세스가 메모리에 올라가서 실행중이다.
여기서 악의적인 프로세스가 다른 프로세스의 메모리 공간에 침입해 공격을 할 수 있다.
그래서 운영체제는 한 프로세스가 다른 프로세스의 메모리 공간에 침입하지 못하도록 막아야 한다.
즉 각각의 프로세스가 독립적으로 메모리를 관리할 수 있어야 한다.
메모리 보호(침입을 막기 위한 방법)
각각의 프로세스가 독립적으로 메모리를 관리할 수 있는 방법을 알아보고 이를 적용해보자.
1. 운영체제의 개입
프로세스에서 특정 메모리에 접근하려 할 때마다 운영체제가 개입해서 적절한 주소에 접근하는 것인지 확인하는 방식이다.
가장 쉽게 생각할 수 있는 방법이다.
이 방식은 메모리에 접근할 때마다 운영체제가 개입하기 때문에 굉장히 느려진다는 단점이 있기 때문에 하드웨어의 지원이 필요하다.
2. Base, Limit 레지스터(하드웨어) 지원
빠르게 접근할 수 있는 레지스터를 기반으로 적절한 주소를 판단하는 방식이다.
여기서 Base 레지스터와 Limit 레지스터가 등장한다.
다음 그림과 같이 Base, Limit 레지스터를 두고 판단하는 방식이다.
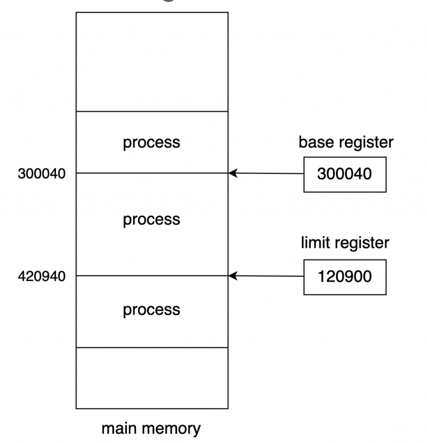
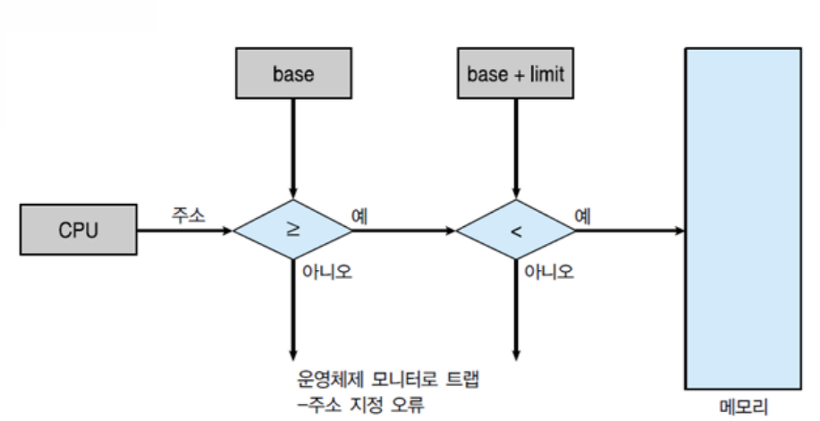
그림과 같이 레지스터가 가리키고 있는 범위를 넘어가면 트랩을 걸어서 해당 동작을 막는다.
해당 레지스터는 특권 명령을 사용하는 운영체제에 의해서만 세팅되기 때문에 악의적인 수정을 막을 수 있다.
적용 전 이해
Base, Limit 레지스터를 통해 메모리를 보호하는 방식을 바로 적용하면 좋겠지만,
CPU와 메모리에서 취급하는 주소는 서로 다르기 때문에 바로 적용할 수 없다.
이 방식을 적용하기 전에 CPU와 메모리가 취급하는 주소의 차이를 이해하자.
CPU와 메모리의 차이
CPU가 생성하는 주소를 일반적으로 논리(가상) 주소라 하며,
메모리가 취급하는 주소는 물리 주소라 한다.
이 둘의 차이를 이해하기 위해서 프로그램이 메모리에 올라가는 과정을 살펴보자.
프로그램이 메모리에 올라가는 과정
프로그램 a.c와 b.c가 있을 때 프로그램이 메모리의 올라가는 과정이다.
a.c에서는 b.c를 가져다 쓰고 있다.
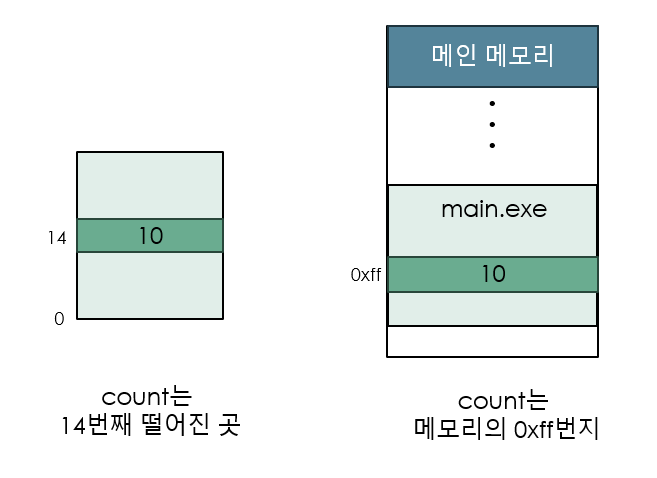
메모리에서 a.c에 있는 변수 count를 취급하는 방식을 유심히 살펴보자.
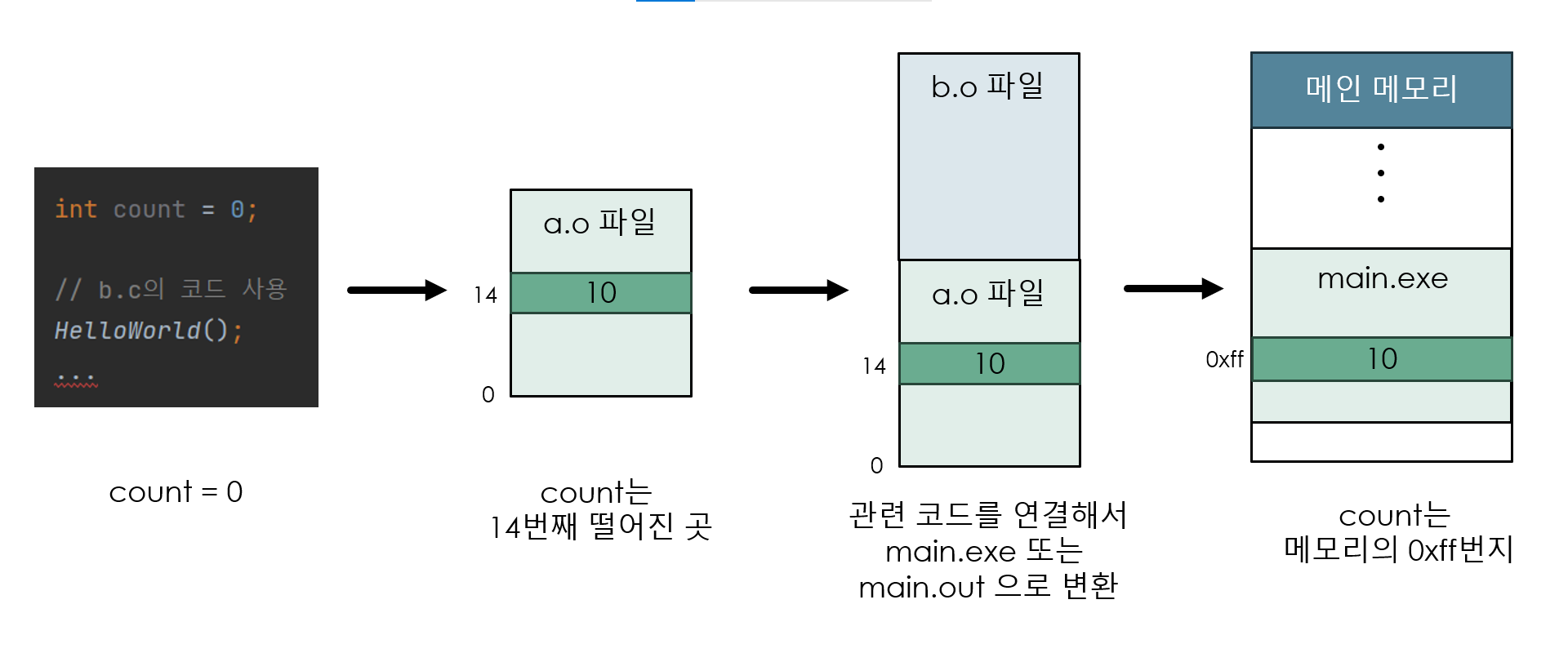
초기의 소스코드에서는 count를 심볼 형태로 표현한다.
myNum = 0, count = 100과 같은 방식이다.
그리고 컴파일러를 거치면서 이 코드는 재배치 가능 주소로 표현된다.
"메모리의 시작부터 14번째 떨어진 곳"과 같은 방식으로 표현한다.
링커와 로더를 거치면서 메모리에 올라가면서 절대 주소로 표현된다.
"메모리의 0xff번지"와 같은 방식이다.
사진의 왼쪽과 같은 방식이 CPU에서 취급하는 논리 주소이고
사진의 오른쪽과 같은 방식이 실제 메모리에서 취급하는 물리 주소이다.
MMU(Memory Management Unit)
CPU에서 생성된 논리주소를 실제 메모리의 물리 주소로 바꿔주기 위해서 MMU가 등장한다.
이러한 이해를 가지고 Base, Limit 레지스터의 개념을 적용해보자.
적용
이제 본격적으로 Base, Limit 레지스터의 개념을 적용해보자.
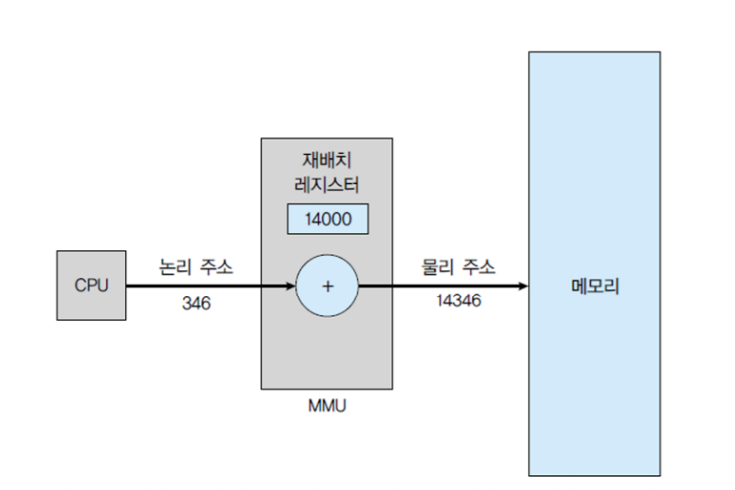
그림에서 MMU가 재배치 레지스터를 가지고 실제 물리주소로 바꿔주고 있다.
CPU의 논리주소에 재배치 레지스터의 값을 더해주는 식이다.
재배치 레지스터는 앞에서 살펴본 Base 레지스터와 유사하다.
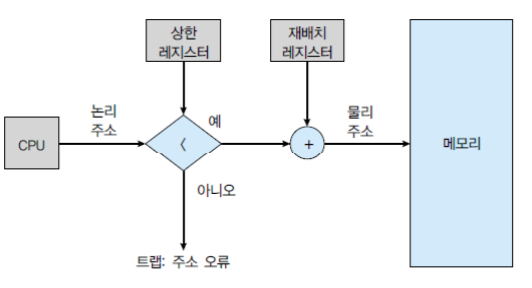
이로써 논리 주소를 물리 주소로 변환할 수 있지만 메모리를 보호할 수 없다. limit 레지스터가 있어야 한다.
limit 레지스터로 논리 주소를 검사하여 논리 주소가 limit 레지스터의 값보다 크다면 트랩을 발생시켜 다른 프로세스의 메모리 영역을 침범하는 것을 막을 수 있다.
이 두 레지스터는 운영체제의 디스패처에서 컨텍스트 스위치를 하면서 값을 바꿔준다.
가변 파티션
우리가 그림으로 본main.exe가 메모리에 올라간 방식은 가변 파티션 방식이다.
가변 파티션은 하나의 프로세스를 메모리에 연속적으로 할당하는 방식이다.
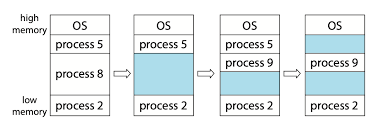
메모리에 올라갈 때 이렇게 연속적으로 할당되는 방식이 당연하고, 상식적이라고 생각할 수 있다.
하지만 비연속적으로 할당하는 페이징이라는 방식이 있고,
이 방식을 대부분의 운영체제에서 사용한다.
다음 글에서 연속적으로 할당하는 가변 파티션과 비연속적으로 할당하는 페이징 방식을 메모리 단편화와 함께 살펴보도록 하겠다.
참고 및 출처
생략 내용
동적 연결 라이브러리(DLL)