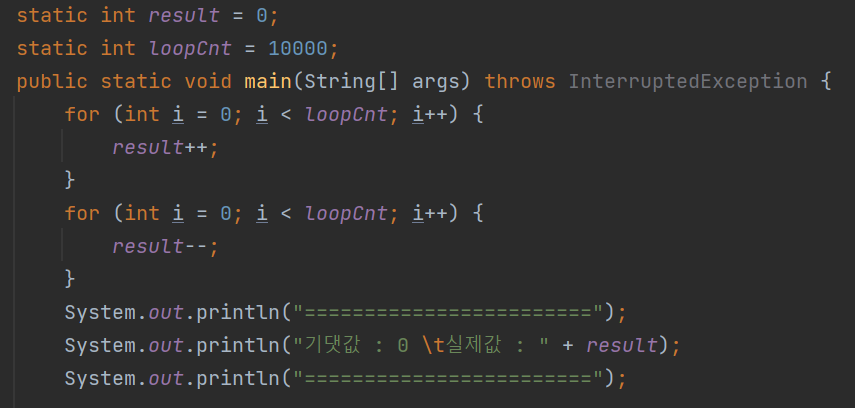
문제의 프로그램 - result
단순하게 result에 값을 loopCnt만큼 더하고 빼는 프로그램이다.
당연히 실제값은 기댓값과 같은 0이 나온다.
성능 향상을 위해서 이 프로그램을 2개의 스레드에서 ++, -- 연산을 실행시켜보자.
기댓값은 실제값과 같을까?
public static void main(String[] args) throws InterruptedException {
Thread plus = new Thread(new Plus());
Thread minus = new Thread(new Minus());
plus.start();
minus.start();
plus.join();
minus.join();
System.out.println("========================");
System.out.println("기댓값 : 0 \t실제값 : " + result);
System.out.println("========================");
}
static int result = 0;
static int loopCnt = 10000;
static class Minus implements Runnable {
@Override
public void run() {
for (int i = 0; i < loopCnt; i++) {
result--;
}
}
}
static class Plus implements Runnable {
@Override
public void run() {
for (int i = 0; i < loopCnt; i++) {
result++;
}
}
}

실행할 때마다 값이 변한다.
프로그램 단순화
static int result = 0;
public static void main(String[] args) throws InterruptedException {
Thread plus = new Thread(() -> result++);
Thread minus = new Thread(() -> result--);
plus.start();
minus.start();
plus.join();
minus.join();
System.out.println("========================");
System.out.println("기댓값 : 0 \t실제값 : " + result);
System.out.println("========================");
}루프문을 빼고 보기 쉽게 프로그램을 단순화해보자.
result를 딱 1번씩만 더하고 빼는 스레드를 만들었다.
문제 인식
문제를 인식하기 위해서는 응용 프로그램 수준이 아닌 컴퓨터 기계어 수준에서 문제를 바라봐야 한다.
만약 처음 코드처럼 result++과 result--를 차례대로 실행할 때
컴퓨터에서 실행시키는 저수준의 기계어의 실행순서는 다음과 같을 것이다.
result++ 실행
++ 실행문 1 : CPU레지스터 A = result(= 0) - CPU에 result 값을 레지스터 A에 가져옴.
++ 실행문 2 : CPU레지스터 A = CPU레지스터 A + 1 (= 0+1)
++ 실행문 3 : result = CPU레지스터 A (= 1) - result 값을 A레지스터 값으로 세팅
result-- 실행
-- 실행문 1 : CPU레지스터 B = result(= 1) - CPU에 result 값을 레지스터 B에 가져옴.
-- 실행문 2 : CPU레지스터 B = CPU레지스터 B - 1 (= 1-1)
-- 실행문 3 : result = CPU레지스터 B (= 0) - result 값을 B레지스터 값으로 세팅하지만 현재 2개의 스레드에서 result라는 공유변수에 접근해서 result++과 result--로 값을 변화시키고 있다.
즉 컨텍스트 스위칭이 발생할 수 있다.
그러므로 실제 동작은 다음과 같다.(컨텍스트 스위칭 시점은 임의로 정했다.)
++ 실행문 1 : CPU레지스터 A = result(= 0) - CPU에 result 값을 A레지스터에 가져옴.
====컨텍스트 스위칭!====
-- 실행문 1 : CPU레지스터 B = result(= 0) - CPU에 result 값을 레지스터 B에 가져옴.
====컨텍스트 스위칭!====
++ 실행문 2 : CPU레지스터 A = CPU레지스터 A + 1 (= 0+1)
++ 실행문 3 : result = CPU레지스터 A (= 1) - result 값을 A레지스터 값으로 세팅
====컨텍스트 스위칭!====
-- 실행문 2 : CPU레지스터 B = CPU레지스터 B - 1 (= 0-1)
-- 실행문 3 : result = CPU레지스터 B (= -1) - result 값을 B레지스터 값으로 세팅최종적으로 result에는 -1의 값이 담기게 됐다.
만약 컨텍스트 스위칭 시점이 바뀌어서 실행문의 순서가 바뀌게 되면 값은 1이 될 수도 있다.
결국 result는 실행문의 순서에 따라 -1, 0, 1 중 하나의 값을 가진다.
경쟁 상태(Race Condition)
여러 스레드가 공유 자원에 접근해 실행결과가 특정 실행 순서에 의존하는 상황을 경쟁 상태라 부른다.
앞서 본 result 예시의 결과는 특정 실행 순서에 따라 실행결과가 -1, 0, 1 중 하나의 값이 나오므로 경쟁 상태라고 할 수 있다.
result에 대한 문제를 해결하기 위해선 어떻게 하면좋을까?
한 순간 하나의 스레드만 result에 접근할 수 있도록 허용하면 해결될 것이다.
즉 동기화를 하면 해결될 것이다.
해결방법이 쉬워보이지만 그렇게 만만하지 않다.
임계구역(Critical Section)
한 순간 하나의 스레드만 result에 접근할 수 있도록 허용하는 방식으로 문제를 해결하기 위해서는 result에 접근하는 코드 영역을 알아야 한다.
이렇게 둘 이상의 스레드가 동시에 접근해서는 안 되는 코드 구역(공유 자원에 접근하는 코드 구역)을 임계구역이라 말한다.
result에 접근하는 코드 영역은 2가지가 있었다.
이 두 코드 부분을 임계 구역이라 부른다.
...
result++; // 임계 구역
......
result--; // 임계 구역
...임계구역 문제
이 문제를 일반화한 것이 임계구역 문제이다.
임계구역에 동시에 접근해서 발생하는 문제를 임계구역 문제라 부른다.
프로세스(스레드) 동기화에 관한 논의는 이 문제에서 시작한다.
- 입출금 문제
- 생산자 - 소비자 문제
- Reader-Writer 문제
위와 같은 임계구역 문제 예시가 있지만
일단 현재 글에서는 result에 관한 문제를 임계구역 문제로 보자.
글의 도입부에서 말한 result 문제에서 좀 더 복잡해질 뿐 주요 개념은 같다.
문제를 해결하기 위한 3가지 요구사항
이 문제를 해결하기 위해서는 다음 3가지 요구사항을 모두 만족해야 한다.
- 상호배제(Mutual Exclusion)
- 진행(Progress)
- 한정된 대기(Bounded Waiting)
상호배제(Mutual Exclusion)
특정 프로세스가 임계구역에 진입해서 실행중이라면 다른 프로세스는 진입할 수 없다.
상호배제는 앞서 본 result문제를 해결하기 위해 생각했던 방법이다.
진행(Progress)
임계구역의 코드를 실행중인 프로세스가 없어서 진입할 수 있을 때
특정 프로세스를 선택해서 실행하게 만들어 줘야 한다.
이 선택은 무한정 연기되면 안된다.
이 요구사항은 데드락을 회피하기 위한 요구사항이다.
한정된 대기(Bounded Waiting)
프로세스는 임계구역의 코드를 실행하기 위해서 무한히 대기하지 않고,
한정된 시간 내에는 임계구역에 진입할 수 있어야 한다.
이 요구사항은 기아를 회피하기 위한 요구사항이다.
간단한 해결방법?
임계구역 문제를 해결하는 간단한 해결방법이 있다.
바로 인터럽트를 막아버리는 방법이다.
즉 비선점 방식으로 동작시켜서 프로세스가 자발적으로 CPU 사용을 중단할 때 컨텍스트 스위칭을 해주는 방식이다.
단일 코어에서는 이러한 비선점 방식이 좋을 수 있다.
하지만 멀티 프로세서라면 여러 코어의 인터럽트를 전부 막아야 한다.
이런 방식은 성능상에 문제를 유발한다.
해결을 위한 피터슨 알고리즘
우리는 임계구역 문제를 인식했고, 이 문제를 해결하기 위한 3가지 요구사항을 알아봤다.
이 문제를 해결하는 소프트웨어 기반의 해결책인 피터슨 알고리즘을 알아보자.
소프트웨어 기반의 해결책이니 저수준의 기계어에 대한 생각은 잠시 접어두고, 자바 코드 레벨에서 생각해보자.
피터슨 알고리즘 구현
피터슨 알고리즘의 아이디어는 다른 프로세스의 turn이고 다른 프로세스의 flag가 true라면 while문에서 루프를 돌면서 대기하는 방식이다.
// 기본 아이디어 : 다른 프로세스(스레드)의 turn이고, flag가 true라면 대기한다.
static boolean[] flag = new boolean[2]; // 구현을 위한 변수들이 추가됨
static int turn;
static class Minus implements Runnable {
static final int id = 0; // 스레드의 id가 추가됨
@Override
public void run() {
for (int i = 0; i < loopCnt; i++) {
flag[this.id] = true;
turn = Plus.id;
while(flag[Plus.id] && turn == Plus.id) // Plus의 상태를 확인함.
; // 루프를 돌고 임계구역을 진입하지 않음.
result--; // 임계 구역
flag[this.id] = false;
}
}
}
static class Plus implements Runnable {
static final int id = 1;
@Override
public void run() {
for (int i = 0; i < loopCnt; i++) {
flag[this.id] = true;
turn = Minus.id;//
while(flag[Minus.id] && turn == Minus.id) // Minus의 상태를 확인함.
; // 루프를 돌고 임계구역을 진입하지 않음.
result++; // 임계 구역
flag[this.id] = false;
}
}
}자바 레벨에서 생각해보면 해당 코드는 상호배제, 진행, 한정된 대기를 모두 만족한다.
코드를 보면서 천천히 생각해보길 권장한다.
소프트웨어의 한계

이제 구현한 코드를 실행해보면 위와 유사한 결과를 얻거나 무한루프에 빠질 수 있다.
결과를 얻어도 기댓값이 아닌 이상한 값을 얻을 수 있다.
즉 임계구역 문제가 해결되지 않았다.
다시 글의 전반부를 살펴보면 알 수 있듯이, 결국 컴퓨터는 기계어 수준에서 load와 store를 하며 돌아가기 때문에 문제가 해결되지 않은 것을 확인할 수 있다.
또한 최신 컴퓨터 아키텍처에서는 종속성이 없는 읽기 및 쓰기 작업을 재정렬 시킬 수 있기 때문에 피터슨 알고리즘이 올바르게 작동한다는 것을 보장할 수 없다.
종속성이 없는 읽기 및 쓰기 작업을 재정렬 예시
x는0으로,flag는false로 초기화돼 있다.- 스레드 1 while(!flag) /* 대기 */; print x;- 스레드 2 x = 100 flag = true;
스레드 1에서x는 100이 출력되길 원한다.
하지만 최신 아키텍처에서는스레드 2에서 코드를 순서대로 실행시키지 않고
flag를 먼저true로 바꾸고x를 100으로 바꿀 수 있다.
즉스레드 1의while문이스레드 2에 의해 종료되어도x는 0 일 수 있다.
왜 피터슨 알고리즘을 알아봤나?
피터슨 알고리즘은 소프트웨어 기반의 알고리즘이기 때문에 올바르게 실행된다고 보장할 수 없다.
근데 왜 피터슨 알고리즘을 알아봤을까?
피터슨 알고리즘은 상호배제, 진행, 한정된 대기의 복잡성을 명료하게 설명할 수 있는 알고리즘이였기 때문이다.
하드웨어의 지원
결국 문제를 해결하기 위해선 소프트웨어 수준이 아닌 하드웨어 수준의 무엇인가가 필요하다.
예를 들어 CPU의 한 클럭안에 result 데이터를 불러와서 변경해주는 회로가 필요할 수 있다.
다음 글에서 하드웨어의 지원과 뮤텍스, 세마포어, 모니터를 알아보겠다.
참고