https://www.dacon.io/competitions/official/235626/overview/
받은 튜터링
: pesudo labeling
: ensemble modeling
: k-fold modeling
제공된 베이스라인 코드
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings("ignore")
import tensorflow as tfLoad data
train = pd.read_csv('/content/drive/My Drive/project/Competiton/Dacon/MNIST/data/train.csv')
test = pd.read_csv('/content/drive/My Drive/project/Competiton/Dacon/MNIST/data/test.csv')EDA
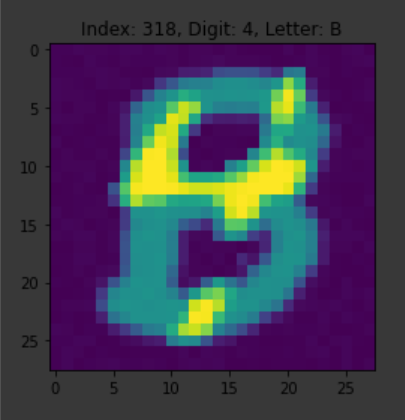
idx = 318
img = train.loc[idx, '0':].values.reshape(28, 28).astype(int)
digit = train.loc[idx, 'digit']
letter = train.loc[idx, 'letter']
plt.title('Index: %i, Digit: %s, Letter: %s'%(idx, digit, letter))
plt.imshow(img)
plt.show()()
Train model
x_train = train.drop(['id', 'digit', 'letter'], axis=1).values
x_train = x_train.reshape(-1, 28, 28, 1)
x_train = x_train/255
y = train['digit']
y_train = np.zeros((len(y), len(y.unique())))
for i, digit in enumerate(y):
y_train[i, digit] = 1def create_cnn_model(x_train):
inputs = tf.keras.layers.Input(x_train.shape[1:])
bn = tf.keras.layers.BatchNormalization()(inputs)
conv = tf.keras.layers.Conv2D(128, kernel_size=5, strides=1, padding='same', activation='relu')(bn)
bn = tf.keras.layers.BatchNormalization()(conv)
conv = tf.keras.layers.Conv2D(128, kernel_size=2, strides=1, padding='same', activation='relu')(bn)
pool = tf.keras.layers.MaxPooling2D((2, 2))(conv)
bn = tf.keras.layers.BatchNormalization()(pool)
conv = tf.keras.layers.Conv2D(256, kernel_size=2, strides=1, padding='same', activation='relu')(bn)
bn = tf.keras.layers.BatchNormalization()(conv)
conv = tf.keras.layers.Conv2D(256, kernel_size=2, strides=1, padding='same', activation='relu')(bn)
pool = tf.keras.layers.MaxPooling2D((2, 2))(conv)
flatten = tf.keras.layers.Flatten()(pool)
bn = tf.keras.layers.BatchNormalization()(flatten)
dense = tf.keras.layers.Dense(1000, activation='relu')(bn)
bn = tf.keras.layers.BatchNormalization()(dense)
outputs = tf.keras.layers.Dense(10, activation='softmax')(bn)
model = tf.keras.models.Model(inputs=inputs, outputs=outputs)
return modelmodel = create_cnn_model(x_train)
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
model.fit(x_train, y_train, epochs=20)
Predict
x_test = test.drop(['id', 'letter'], axis=1).values
x_test = x_test.reshape(-1, 28, 28, 1)
x_test = x_test/255
# submission = pd.read_csv('submission.csv')
submission = pd.read_csv('/content/drive/My Drive/project/Competiton/Dacon/MNIST/data/submission.csv')
submission['digit'] = np.argmax(model.predict(x_test), axis=1)
submission.head()()

submission.to_csv('baseline.csv', index=False)
점수
Private : 0.76311 ( 255위 )
CNN모델의 성능 순위
https://paperswithcode.com/sota/image-classification-on-imagenet
CNN모델의 성능을 향상 시키는 방법
- 위의 모델 중 성능이 괜찮게 나오는 것을 쓴다.
- overfitting 방지하기
- ensemble
- pseudo labeling
- k-fold
- ImageDataGenerator
- 신경망 튜닝하기
Overfitting 방지하기
- Overfitting : 학습데이터에 지나치게 맞는 모델을 학습함으로써 일반화 성능이 떨어지는 현상.
학습이 진행함에 따라 Training data의 오차는 줄어들지만, 검증데이터인 Validation data의 오차는 감소하다가 일정 시점이 지나면 증가하게 된다.
보통 이 시점에서 학습을 멈추어 딥러닝 모델을 생성.
- 방지 하는 법
-
데이터의 양을 늘리기
-
모델의 복잡도 줄이기
-
가중치 규제 적용하기
-
드롭아웃
Ensemble
- 앙상블 학습이란 여러개의 모델을 학습시키는 기법.
가장좋은 모델 하나의 예측보다 앙상블을 이용해 여러개의 모델의 예측을 이용해 최종 예측을 결정하는 것이 좋은 결과를 도출.
- 여러개의 모델에 대한 앙상블을 통해 최종 예측을 결정. 전형적인 분류 문제일 경우 통계적 최빈값을 사용 회귀의 경우 평균을 계산.
Pseudo labeling
- 수도 라벨링. SSL( semi-supervised learning )의 여러가지 방법 중 하나.
- 필요한 상황.
-
만들고자 하는 Model에 쓸, Training data가 절대적으로 부족할 때
-
Large dataset이 될 수록 새로 생성되는 data들에 대한 human annotation 이 힘들고, 비쌀 때.
-
Labeled data만으로는 도달 할 수 있는 성능에 한계가 있을 때, Unlabeled data를 사용하여 전반적인 성능을 더 높일 때.
K-Folds Cross Validation Method
- K개의 fold를 만들어서 진행하는 알고리즘/
- 모든 데이터가 최소 한 번은 테스트셋으로 쓰이도록 한다.
- 데이터셋의 크기가 작은 경우 테스트셋에 대한 성능 평가의 신뢰성이 떨어진다.
ImageDataGenerator
- 이미지 데이터 뻥튀기.
- 데이터를 이리저리 변형시켜서 새로운 학습 데이터를 만들어 준다.
- 변형의 예시는 회전, 이동 등 매우 다양.
신경망 튜닝하기
- GridSearchCV를 이용하여 하이퍼파라미터를 최적화하면 모델 성능 향상에 도움된다.
- k-fold 교차검증과 함께 사용하면 세부 튜닝하기 좋음.
이외...
- Early Stopping
- ModelCheckPoint
: 긴 학습시간동안 영문모를 셧다운에 대비하여 위를 이용.
code
colab에서 진행.
import pandas as pd
pd.read_csv('train.csv')
pd.read_csv('test.csv')# train 이미지들과 test 이미지들을 저장해놓을 폴더를 생성합니다.
!mkdir images_train
!mkdir images_train/0
!mkdir images_train/1
!mkdir images_train/2
!mkdir images_train/3
!mkdir images_train/4
!mkdir images_train/5
!mkdir images_train/6
!mkdir images_train/7
!mkdir images_train/8
!mkdir images_train/9
!mkdir images_testimport cv2
for idx in range(len(train)) :
img = train.loc[idx, '0':].values.reshape(28, 28).astype(int)
digit = train.loc[idx, 'digit']
cv2.imwrite(f'./images_train/{digit}/{train["id"][idx]}.png', img)
for idx in range(len(test)) :
img = test.loc[idx, '0':].values.reshape(28, 28).astype(int)
cv2.imwrite(f'./images_test/{test["id"][idx]}.png', img)open CV를 통해 train, test 데이터의 이미지들을 저장.
import tensorflow as tf
model_1 = tf.keras.applications.InceptionResNetV2(weights=None, include_top=True, input_shape=(224, 224, 1), classes=10)
model_2 = tf.keras.Sequential([
tf.keras.applications.InceptionV3(weights=None, include_top=False, input_shape=(224, 224, 1)),
tf.keras.layers.GlobalAveragePooling2D(),
tf.keras.layers.Dense(1024, kernel_initializer='he_normal'),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Activation('relu'),
tf.keras.layers.Dense(512, kernel_initializer='he_normal'),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Activation('relu'),
tf.keras.layers.Dense(256, kernel_initializer='he_normal'),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Activation('relu'),
tf.keras.layers.Dense(10, kernel_initializer='he_normal', activation='softmax', name='predictions')
])
model_3 = tf.keras.Sequential([
tf.keras.applications.Xception(weights=None, include_top=False, input_shape=(224, 224, 1)),
tf.keras.layers.GlobalAveragePooling2D(),
tf.keras.layers.Dense(1024, kernel_initializer='he_normal'),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Activation('relu'),
tf.keras.layers.Dense(512, kernel_initializer='he_normal'),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Activation('relu'),
tf.keras.layers.Dense(256, kernel_initializer='he_normal'),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Activation('relu'),
tf.keras.layers.Dense(10, kernel_initializer='he_normal', activation='softmax', name='predictions')
])3가지 모델의 앙상블. 최종 예측값은 최빈값으로 결정.
model_1.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
model_2.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
model_3.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])from tensorflow.keras.preprocessing.image import ImageDataGenerator
datagen = ImageDataGenerator(rescale=1./255, validation_split=0.2,
rotation_range=10,
width_shift_range=0.1,
height_shift_range=0.1)
train_generator = datagen.flow_from_directory('./images_train', target_size=(224,224), color_mode='grayscale', class_mode='categorical', subset='training')
val_generator = datagen.flow_from_directory('./images_train', target_size=(224,224), color_mode='grayscale', class_mode='categorical', subset='validation')ImageDataGenerator은 이미지에 대한 회전, 이동 등의 전처리를 쉽게 수행. 이미지 데이터 뻥튀기.
전체 2048개의 train 중에 20% validation으로 사용.
checkpoint_1 = tf.keras.callbacks.ModelCheckpoint(f'./drive/My Drive//content/drive/My Drive/project/Competiton/Dacon/월간 데이콘 7 : 컴퓨터 비전 학습 경진대회/data/model_1.h5', monitor='val_accuracy', save_best_only=True, verbose=1)
checkpoint_2 = tf.keras.callbacks.ModelCheckpoint(f'./drive/My Drive//content/drive/My Drive/project/Competiton/Dacon/월간 데이콘 7 : 컴퓨터 비전 학습 경진대회/data/model_2.h5', monitor='val_accuracy', save_best_only=True, verbose=1)
checkpoint_3 = tf.keras.callbacks.ModelCheckpoint(f'./drive/My Drive//content/drive/My Drive/project/Competiton/Dacon/월간 데이콘 7 : 컴퓨터 비전 학습 경진대회/data/model_3.h5', monitor='val_accuracy', save_best_only=True, verbose=1)ModelCheckPoint를 통해 val_accuracy가 가장 좋게 나온 epoch에서 모델 저장.
h5파일을 구글 드라이브에 저장. colab연결이 끊겨도 다음에 저장된 모델 다시 불러옴.
model_1.fit_generator(train_generator, epochs=500, validation_data=val_generator, callbacks=[checkpoint_1])
model_2.fit_generator(train_generator, epochs=500, validation_data=val_generator, callbacks=[checkpoint_2])
model_3.fit_generator(train_generator, epochs=500, validation_data=val_generator, callbacks=[checkpoint_3])import matplotlib.pyplot as plt
plt.plot(model_1.history.history["accuracy"], label='m1_acc')
plt.plot(model_1.history.history["val_accuracy"], label='m1_vacc')
plt.plot(model_2.history.history["accuracy"], label='m2_acc')
plt.plot(model_2.history.history["val_accuracy"], label='m2_vacc')
plt.plot(model_3.history.history["accuracy"], label='m3_acc')
plt.plot(model_3.history.history["val_accuracy"], label='m3_acc')
plt.legend()
plt.show()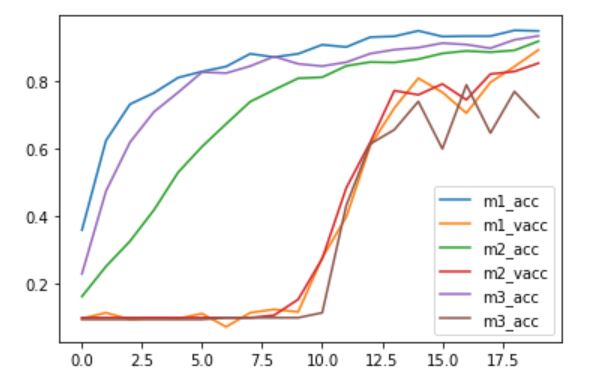
학습한 모델의 accuracy 와 val_accuracy 시각화.
model_1 = tf.keras.models.load_model('./drive/My Drive//content/drive/My Drive/project/Competiton/Dacon/월간 데이콘 7 : 컴퓨터 비전 학습 경진대회/data/model_1.h5', compile=False)
model_2 = tf.keras.models.load_model('./drive/My Drive//content/drive/My Drive/project/Competiton/Dacon/월간 데이콘 7 : 컴퓨터 비전 학습 경진대회/data/model_2.h5', compile=False)
model_3 = tf.keras.models.load_model('./drive/My Drive//content/drive/My Drive/project/Competiton/Dacon/월간 데이콘 7 : 컴퓨터 비전 학습 경진대회/data/model_3.h5', compile=False)저장한 h5파일 불러오기
!mkdir images_test/none
!mv images_test/*.png images_test/nonedatagen = ImageDataGenerator(rescale=1./255)
test_generator = datagen.flow_from_directory('./images_test', target_size=(224,224), color_mode='grayscale', class_mode='categorical', shuffle=False)test 이미지들에 대해 ImageDataGenerator 사용.
가상의 클래스 none 폴더 생성하여 모든 파일 이동.
predict_1 = model_1.predict_generator(test_generator).argmax(axis=1)
predict_2 = model_2.predict_generator(test_generator).argmax(axis=1)
predict_3 = model_3.predict_generator(test_generator).argmax(axis=1)submission = pd.read_csv('./data/submission.csv')
submission.head()submission["predict_1"] = predict_1
submission["predict_2"] = predict_2
submission["predict_3"] = predict_3
submission.head()from collections import Counter
for i in range(len(submission)) :
predicts = submission.loc[i, ['predict_1','predict_2','predict_3']]
submission.at[i, "digit"] = Counter(predicts).most_common(n=1)[0][0]
submission.head()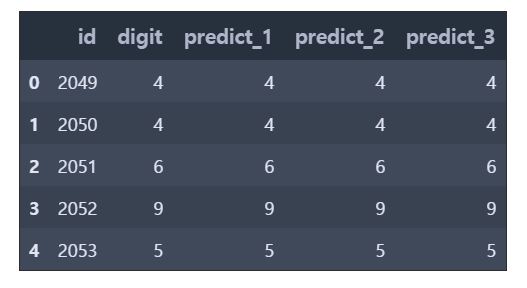
submission = submission[['id', 'digit']]
submission.head()submission.to_csv('submission_ensemble_3.csv', index=False)점수
public : 0.95588 ( 2위 )
Private : 0.93134 ( 6위 )
결론
공부한 것을 복습하는 겸 나름 쉬워보이는 MNIST 데이콘 대회로 준비해보았는데 계획한것을 코드로 구현하기가 아직 힘들었고 무엇보다 학습시간이 매우...길다는... ㅠ 위의 코드는 코드공유 올려주신 분의 코드를 따라 치며 리뷰한 것이고 이외 더 좋은 코드가 많지만 이해조차 아직 힘든 부분이 있었습니다.
또 코드를 보면 위와같이 제 생각으로는 간단해 보여도 나름 점수가 좋은 부분이 있고 복잡하고 뭔가 좋은 모델 같아도 점수가 안좋은 것도 있는거 같았습니다. ( 아직 알아야 할게 많은... )
아직 더 많이 공부해야 하고 그래도 준비하면서 많은 부분 공부가 되었던거 같습니다.
