서론
이 글부터 나는 앤드류 응 교수님이 사용하는 효과적인 논문 읽기 방법으로 논문을 읽어 볼 것이다. 앤드류 응 교수의 효과적으로 논문 읽는 방법 한번 봐보자!
논문의 제목과 초록과 도표를 먼저보자!
논문 제목
우선 논문의 제목은 "You Only Look Once: Unified, Real-Time Object Detection"이다. 한국어로 번역하면 "넌 한번만 봐! : 통합적, 실시간 객체 분할"이다. 느낌상 모델이 이미지를 한번 쑥 흝어보고 객체 분할을 해서 시간이 많이 걸리지 않고 실시간으로 객체 감지를 할 수 있는 모델인갑다...싶다.
논문 초록(abstract)
이 논문에서는 객체 감지에 대한 새로운 접근법인 YOLO를 제시한다. 객체 감지에 대한 이전의 분류기(classifiers)의 용도를 변경하고 대신에 객체 감지를 공간적으로 분리된 경계 상자(bounding boxes)와 관련 클래스(label) 확률을 나오게 만든다. 단일 신경망은 경계 상자와 클래스 확률을 예측한다. 하나의 평가에서 full image를 볼 수 있다. 이 모든 것이 하나의 파이프라인이 단일 네트워크이기 때문에 end-to-end로 바로 탐지 성능을 낼 수 있다...라고 첫 문단 해석을 했다. 그러니까 이 논문에서 강조하고 싶은 것은 이전의 모델과는 달리 경계 상자 예측과 클래스 분류에 대한 것을 단일 신경망으로 처리하게 하여 실시간 처리가 가능하게 한 것이라고 생각한다. 그 다음 문단에서는 그래서 이 YOLO architecture는 굉장히 빠르고, 그 단위가 초당 45프레임으로 빠르다고 한다. 작은 버전인 Fast YOLO는 초당 155프레임이지만 mAP가 다른 실시간 detectors보다 2배가량 높다는 것을 알 수 있다. YOLO는 다른 객체 감지 모델보다는 localization오류를 더 많이 발생시키지만 배경을 예측하는 것(background error)를 줄여준다. 마지막으로 일반화하는 능력이 뛰어나 input image가 깨져도 망가지는 경우가 적고, DPM과 R-CNN을 포함한 다른 방법을 능가한다고 한다. 이 문단에서도 강조하는 것은 굉장히 빠르고, 일반화에대한 오류도 적다인 것 같다.
도표 보기

이 그림은 YOLO 시스템에 대한 전반적인 그림이다. 1. 이미지 사이즈를 448 * 448 사이즈로 변경하고, 2. 단일 컨볼루션 네트워크를 거친후, 탐지를 통해 결과를 도출하는 느낌인 것 같다.
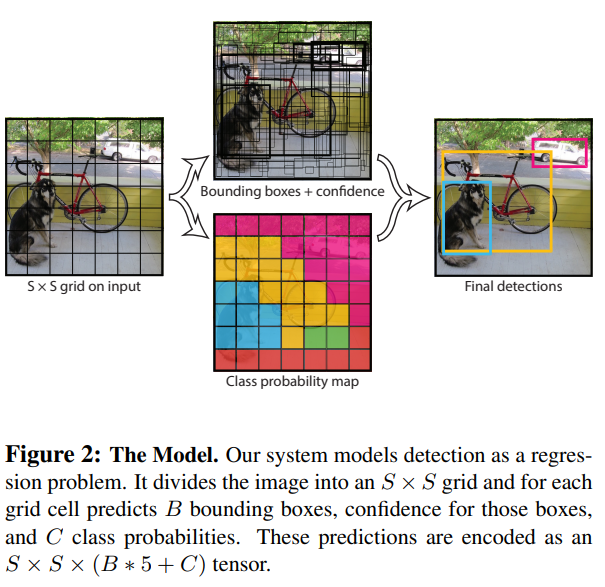
모델에 대한 설명이다. YOLO는 감지를 회귀로 모델링하여, 이미지를 S S grid로 분할하고 각 grid cell은 B 경계 상자(Bounding boxes)와 그 경계 상자에 대한 confidence를 예측하고,
C 클래스 확률에 대해서도 예측한다. 이 예측값들은 S S * (B <= 5 + C)텐서로 인코딩된다.

모델 구성도이다. YOLO는 24개의 컨볼루션 네트워크와 2개의 FC layer로 구성되어 있다. 또한 1 1 conv layer에서 feature 공간을 줄인다. 모델의 훈련은 ImageNet 분류 도구를 통해 사전학습을 했다고 한다. 작업은 해상도의 절반에서 수행한 다음(입력 이미지는 224 224) 검출을 할 떄는 두 배의 해상도를 사용한다고 한다.
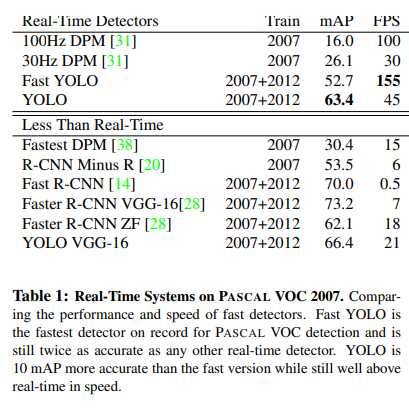
파스칼 VOC 2007 dataset을 이용하여 모델을 훈련시켰을 때 결과를 비교한 표이다. Real-Time Detector에서는 Faster YOLO가 압도적으로 초당 155프레임으로 높고, YOLO는 mAP가 가장 높음을 알 수 있다. 이 부분에서 강조하는 것은 FPS는 월등하게 다른 R-CNN모델보다 높고, mAP에서도 그렇게 나쁘지 않은 모습을 보여주어 실시간 처리에는 YOLO가 탑이다! 라는 것을 강조하는 것같다.
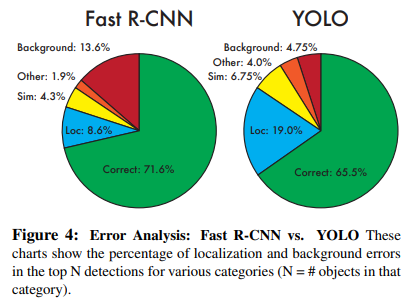
또한 background error에서도 Fast R-CNN과 비교했을 떄 YOLO가 거의 1/4차이가 난다고 한다. 하지만 초록에서 말했듯이 localization오류는 Fast R-CNN보다 높다는 것을 알 수 있다.
결론
YOLO 모델은 구축과 훈련이 간단하고, 전체 이미지를 살펴본다. 분류기 기반 접근법과는 다르게 전체 이미지에 직접 대응을 하는 손실 함수에 대해 훈련된다. Fast YOLO는 가장 빠른 detector이며 YOLO는 최신 기술이다. 또한 잘 일반화가 되고 빠르고 강력하게 물체를 감지 할 수 있다.
논문을 읽고 해야할 것!
- 저자가 뭘 해내고 싶어 했는가?
- 실시간으로 Object detection이 될 수 있는 모델을 만들어내고자 한 것 같다. 실제로 Fast YOLO는 155 FPS로 빠르고 mAP에서도 나쁘지 않다는 것을 보여준다.
- 이 연구의 접근에서 중요한 요소는 무엇인가?
- bbox예측과 클래스 예측을 동시에, 통합적으로 다루는 것인것 같다. 또한 전체 이미지를 직접 접근해서 훈련하는 방식도 중요한 요소인 것같다.
- 나는 스스로 이 논문을 이용할 수 있겠는가?
- 지금하는 프로젝트 중에 얼굴 감정 인식 프로젝트가 있는데, 거기에 YOLO를 사용할 예정이다. pretrained 모델을 사용할 것이긴하지만, 밑바닥부터 구현을 하는 도전도 해볼 것이다.
- 내가 참고하고 싶은 다른 레퍼런스에는 어떤 것이 있나?
- 논문에서 YOLO를 Fast R-CNN에 비교를 많이 하던데, Fast R-CNN은 실시간에서는 YOLO에 밀리지만 성능측에서는 YOLO를 뛰어넘는다고 하니 공부해보고 싶다.
