기본 개념들
Gradient Descent
- loss function에 대한 gradient(partial derivative 편미분)을 구해서 (learning rate를 곱해서) 파라미터에서 빼주는 방식
- 1차 미분값만 사용하게 된다.
- 반복적으로 최적화 시킨다.
- local minimum으로 향하게 된다.
scaling, normalization
- scaling : 데이터들의 범위를 변경
- normalization : 데이터들의 분포 모양을 변경
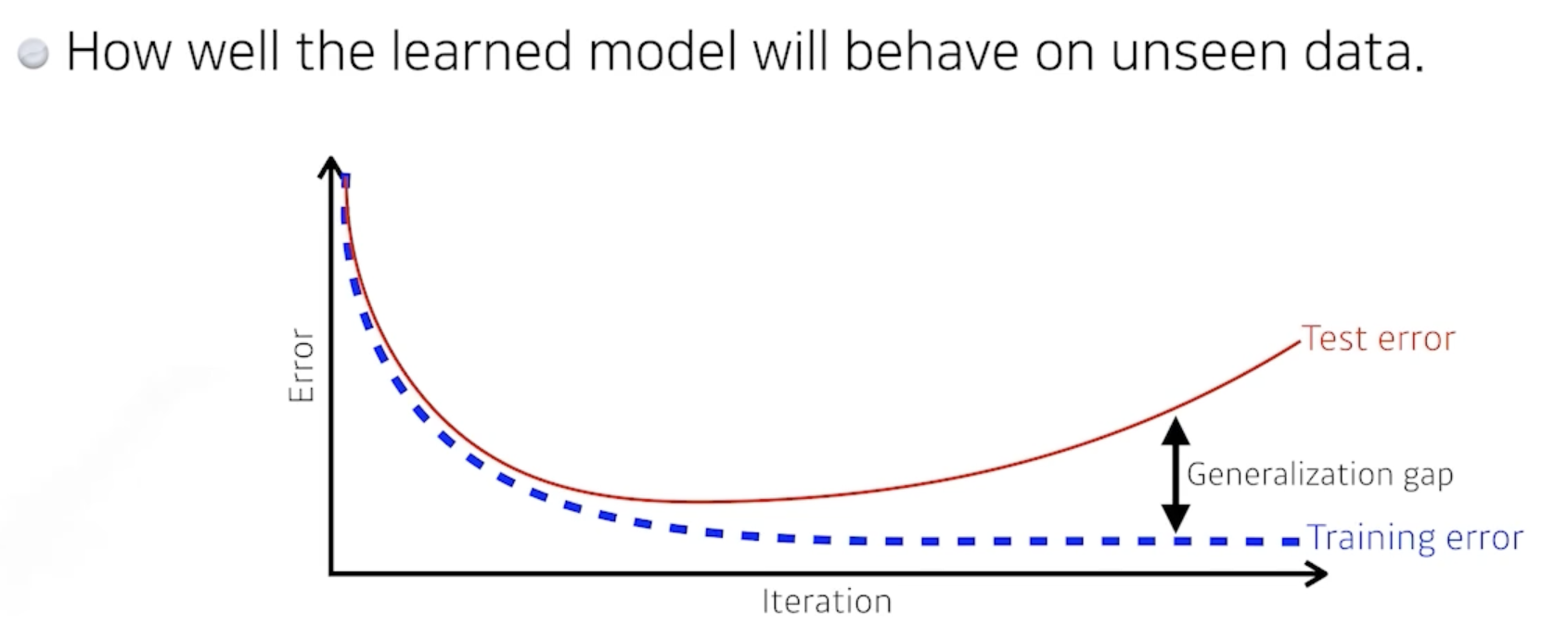
generalization
- 최적화 성능
: 새로운 data에 대해 학습된 모델이 얼마나 잘 작동하는가 - train data와 test data사이의 성능 차이
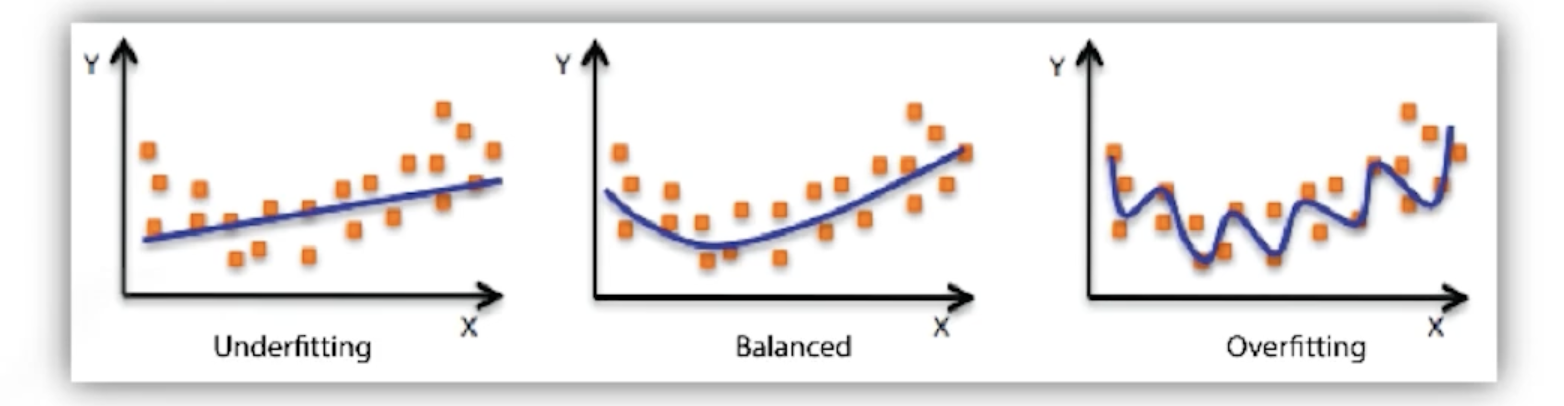
overfitting, underfitting
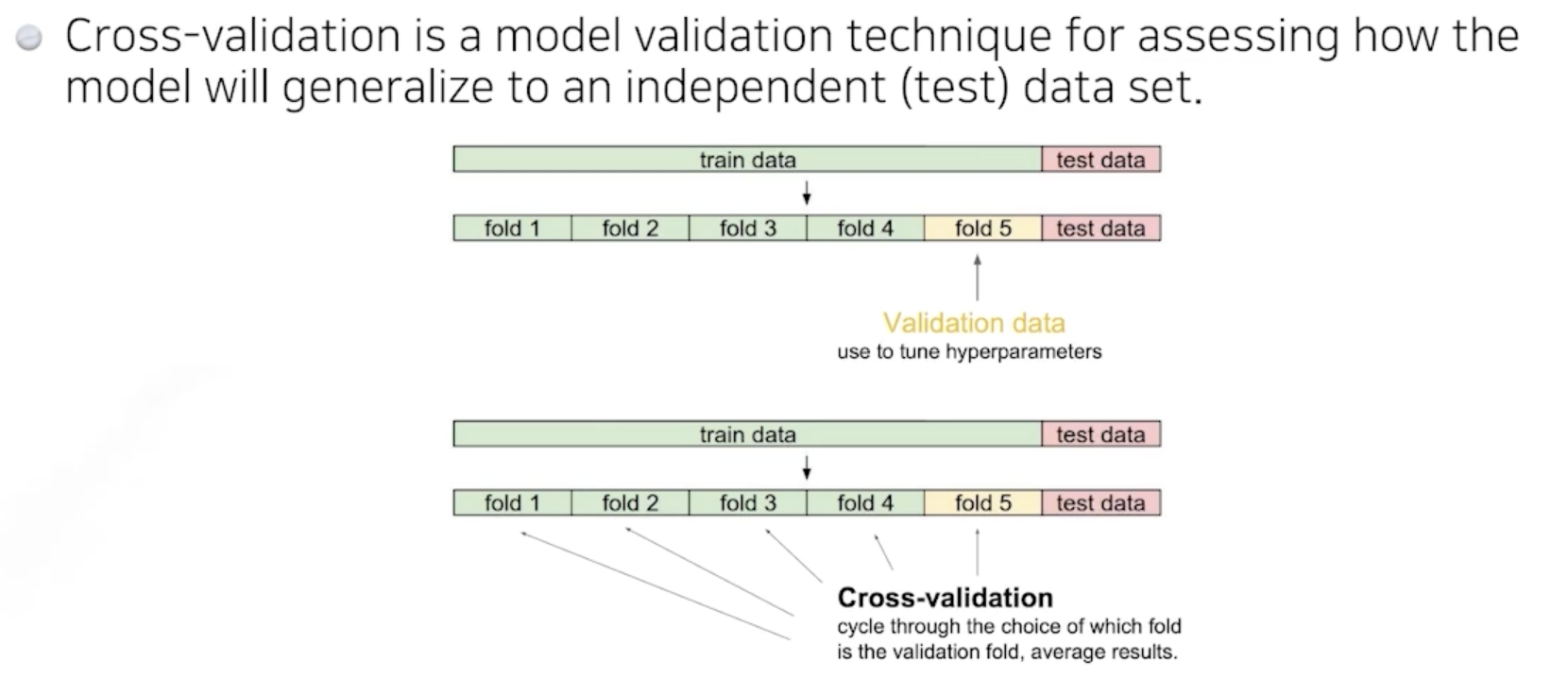
Cross-validation
= k-fold validation
- 제공된 학습데이터(train data)를 나눠서 일부를 validation data로 사용
- train-set와 val-set을 k개의 partition으로 나눈 후, 번갈아가면서 하나의 partition을 val-set으로 사용하고 나머지 k-1개로 학습하는 것을 반복해보는 방법!
- 최적의 hyperparameter를 찾은 후,
해당 정보를 활용하여 최종 학습을 한다. (모든 train data이용)
Bias & Variance
- variance
- 일관적인 output이 나오는가 (variance 낮을 수록 일관적임)
- varaince가 크면 비슷한 입력에 대해 출력이 많이 달라진다.
: overfitting될 가능성이 큼
- Bias
- 값들의 평균이 true target에 가깝다. (bias 낮을 수록)
- bias 높으면 평균이 target에서 벗어나있다.
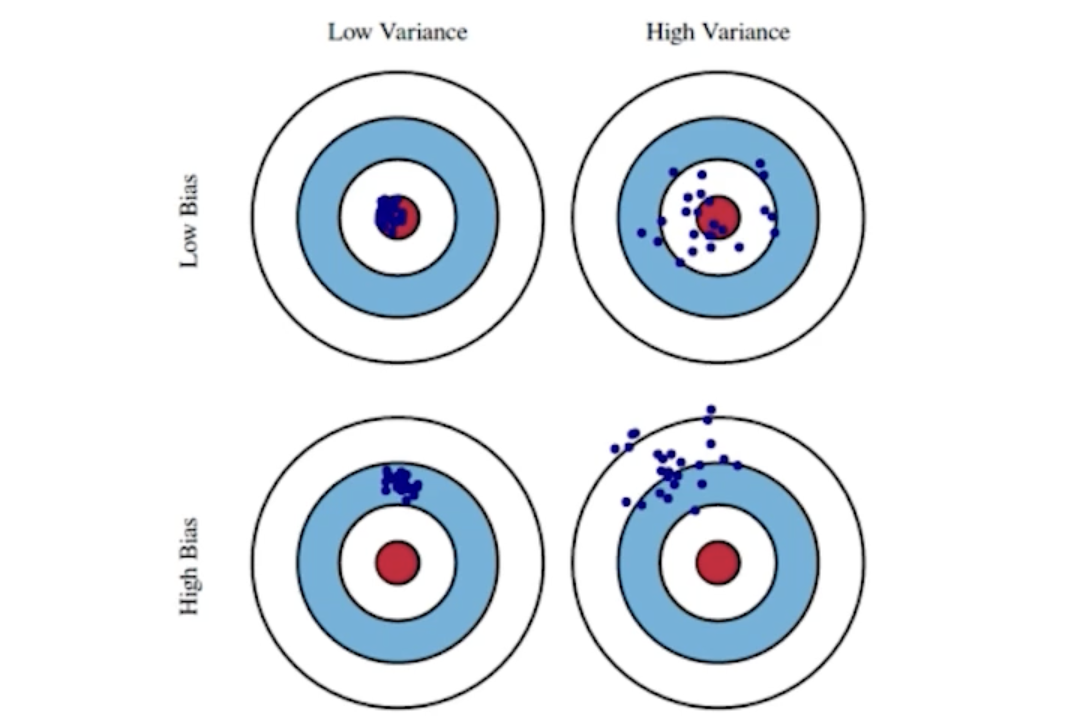
- cost를 최소화하기 위해
: bias(절대값), variance, noise를 최소화해야 한다.
- bias와 variance는 trade-off
Bootstrapping
- 주어진 data에 대해 random으로 일부를 사용해서 (sub-sampling) 학습데이터를 여러개 만들어 train data를 늘린 후,
그에대한 여러가지 모델, metric을 얻는 방법 - 적은 data로 overfitting을 줄일 수 있다.
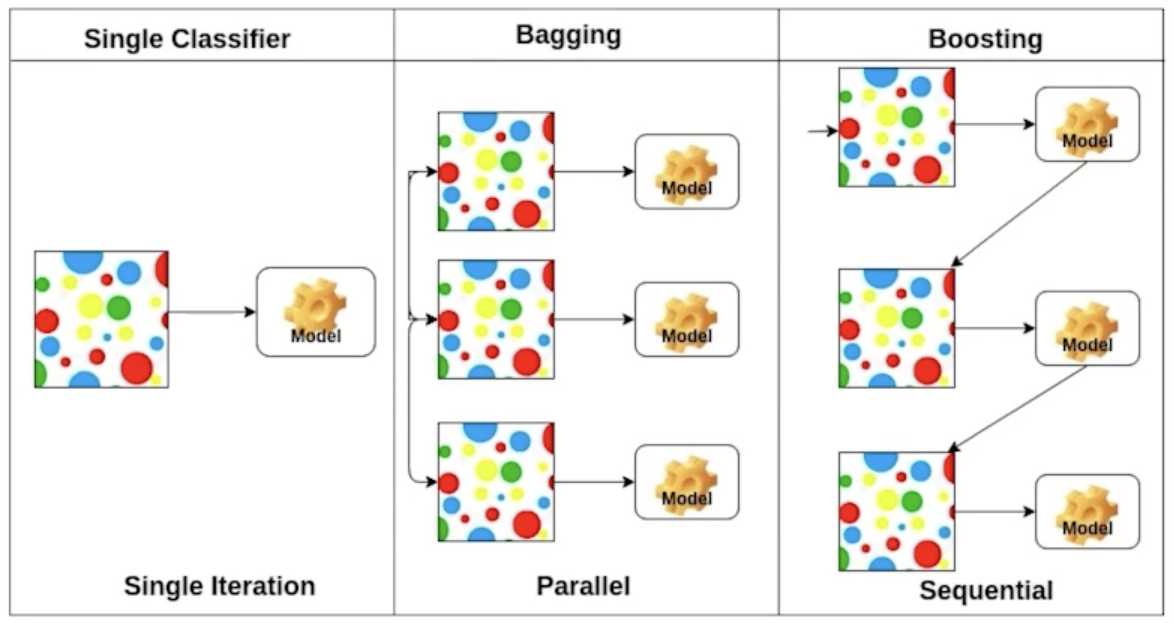
Bagging, Boosting
- Bagging : Bootstrapping aggregation
- bootsrapping을 통해 여러 random sub-sampling을 만들고, 여러 모델들을 만든 후 평균을 내는 방법
: ensemble - 통째로 사용해서 하나의 모델을 만드는 것 보다 성능이 좋을 때가 많다. (overfitting 감소)
- bootsrapping을 통해 여러 random sub-sampling을 만들고, 여러 모델들을 만든 후 평균을 내는 방법
- Boosting
- 이전 모델에서 잘 예측하지 못 한 데이터에 대해 잘 동작하는 모델을 생성.
: 각각 weak model - weak model들을 sequential하게 합쳐서 하나의 strong model을 만든다.
- 이전 모델에서 잘 예측하지 못 한 데이터에 대해 잘 동작하는 모델을 생성.
Gradient Descent
Stochastic gradient descent
: 한 개의 data (single sample)로 gradient를 구해서 update
-> 계속 반복
Mini-batch gradient descent
: batch-size에 따라 나눠진 data의 subset단위로 gradient를 구해서 update
-> 계속 반복
Batch gradient descent
: 모든 data를 한 번에 다 써서 gradient구해서 update
batch-size
- batch-size 크면 -> sharp minimizer 도달
batch-size 작으면 -> flat minimizer 도달
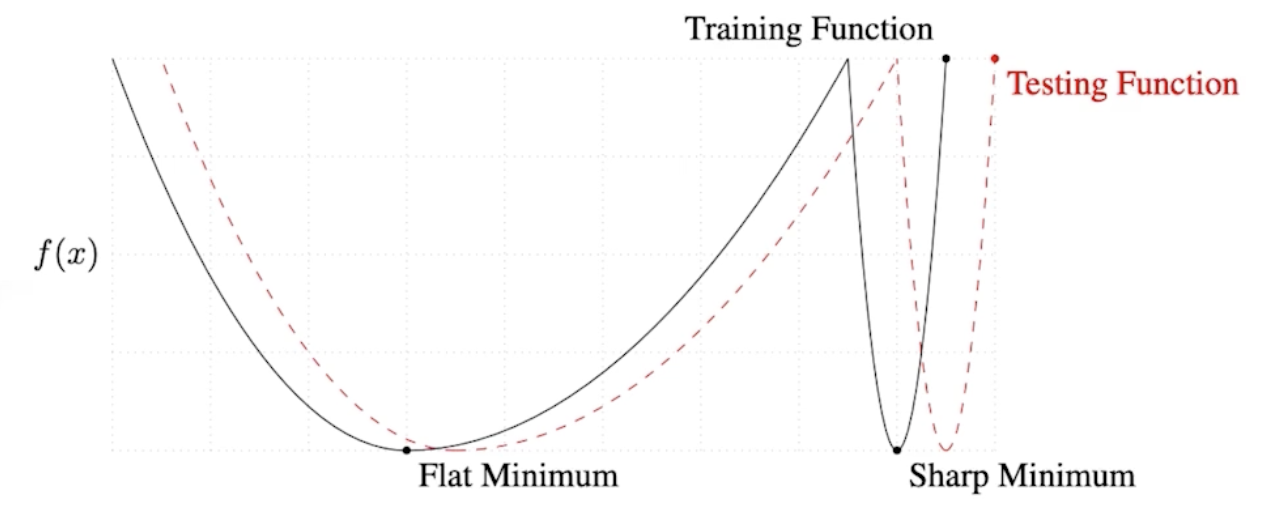
- sharp minimum : 예측이 조금만 벗어나도 오차가(loss값) 크다.
- batch-size 작을 수록 generalize performance가 좋아진다.
Optimization
: Gradient Descent Method
- gradient는 라이브러리에서 auto로 계산해준다.
- g에 대해 사용할 Optimizer를 골라야 한다.
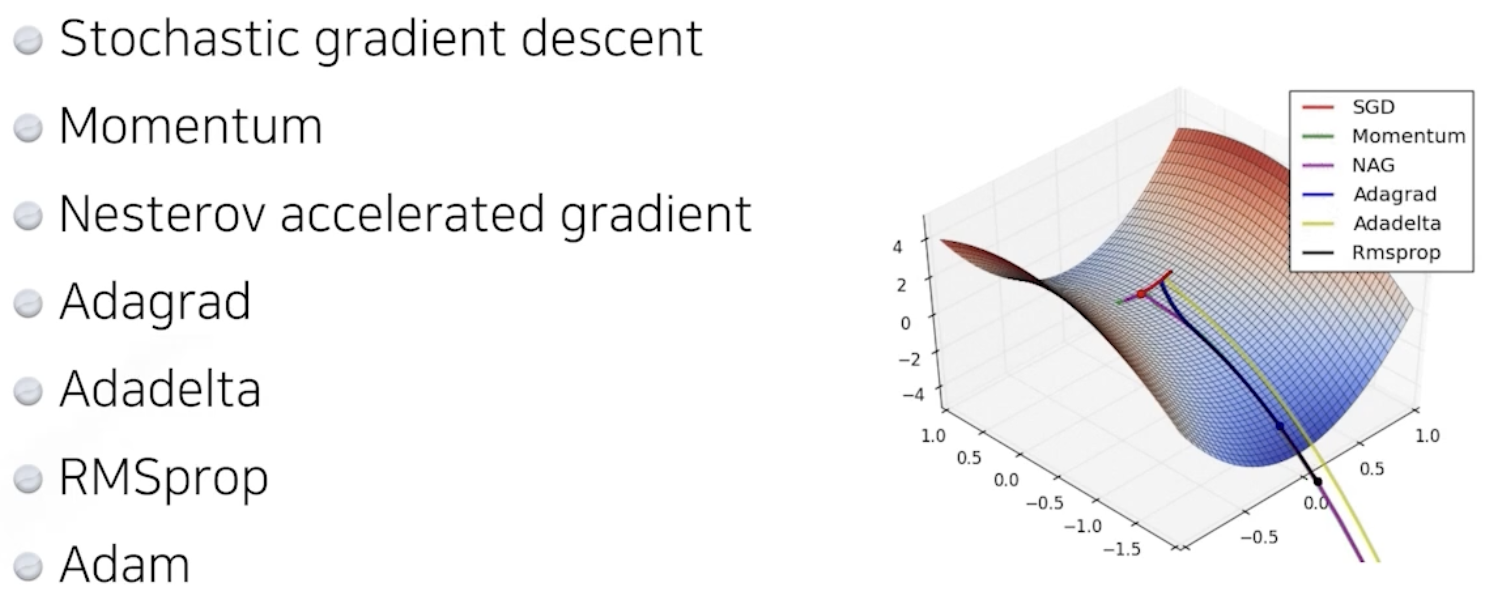
(stochastic) gradient descent
- 적절한 learning rate를 잡는 것이 어렵다.

momentum
- gradient에 momentum을 더한 accumulation으로 update한다.
- 한 번 gradient가 흐르는 방향을 유지함으로써(관성) g가 너무 자주 바뀌더라도 좋은 학습이 가능하도록 해준다.
- 관성때문에 local-minimal로 수렴하지 못하고 계속 지나치는 (진자운동) 현상이 생길 수 있다.

Nesterov Accelerated Gradient
- Lookahead gradient를 이용
- local minima로 수렴을 더 빨리할 수 있다.
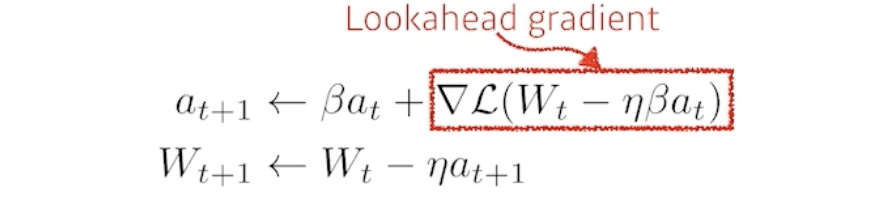
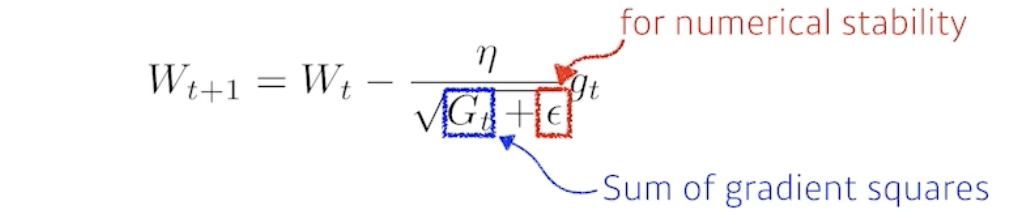
Adagard
- G : 현재까지 해당 파라미터가 변화한 정도
-> 분모에 있기에 많이 변한 파라미터는 적게, 적게 변한 파라미터는 많이 update 한다. - G가 계속 커지기 때문에 학습이 이어질 수록 무한대로 가서 (update)학습이 멈추게 된다.
Adadelta
- G가 계속 커지는 것을 막기 위해 최근 몇 개의 학습에 대한 변화만 저장한다.
- learning rate가 없다.
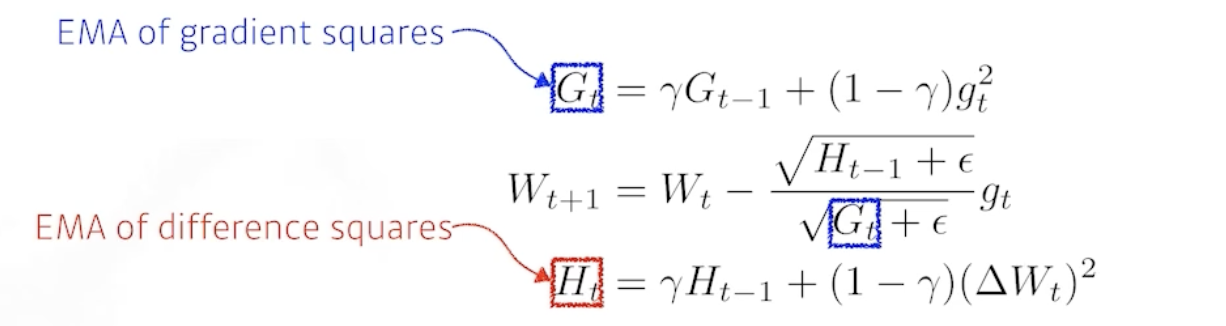
RMSprop
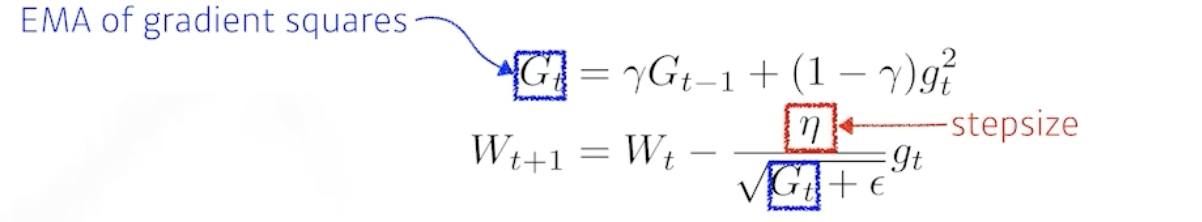
Adam
- G와 함께 momentum을 사용하는 방법

Regularization
- generalization performance를 높이기 위해 학습을 방해하는 방향으로 규제를 거는 것
- Train-data뿐만아니라, Test-data에 대해서도 예측을 잘 하도록 해준다.
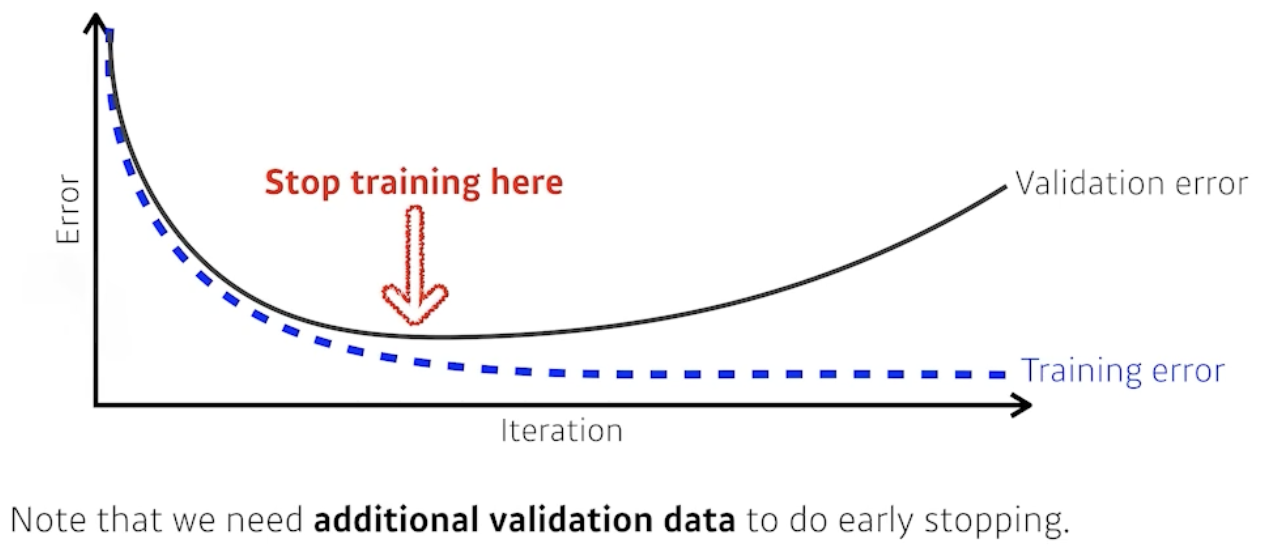
Eearly stopping
- validation-data를 활용하여, overfitting이 발생하기 전에 학습을 멈춘다.
Parameter Norm Penalty
- network (weight)parameter의 값을 작게하기 위해 숫자를 다같이 줄인다.
- parameter가 작아지면 -> 부드러운 함수

Data Augmentation
- 데이터의 규모와 DeepLearning 성능은 영향이 크다.
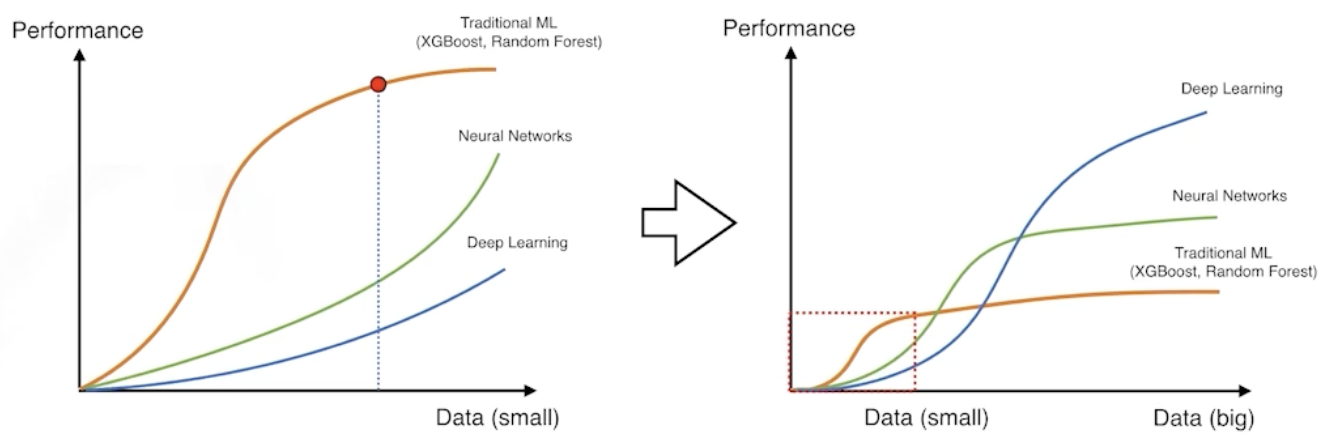
- 데이터의 label이 바뀌지 않는 선에서 데이터를 조작해 데이터 수를 늘리는 방법

Noise Robustness
- 데이터에 noise를 넣어서 데이터를 늘리는 것
- 학습 때, weight에도 noise를 넣어서 흔들어주면 성능이 좋아진다.

Label smooting
- 학습 데이터 두개를 뽑아서, classification label의 경계를 부드럽게 하는 것
- 성능이 잘 올라간다.

Drop-out
- Neural Network의 일부 weight를 0으로 바꾸는 것
-> 각 뉴런들 Robust한 feature를 잡을 수 있다.
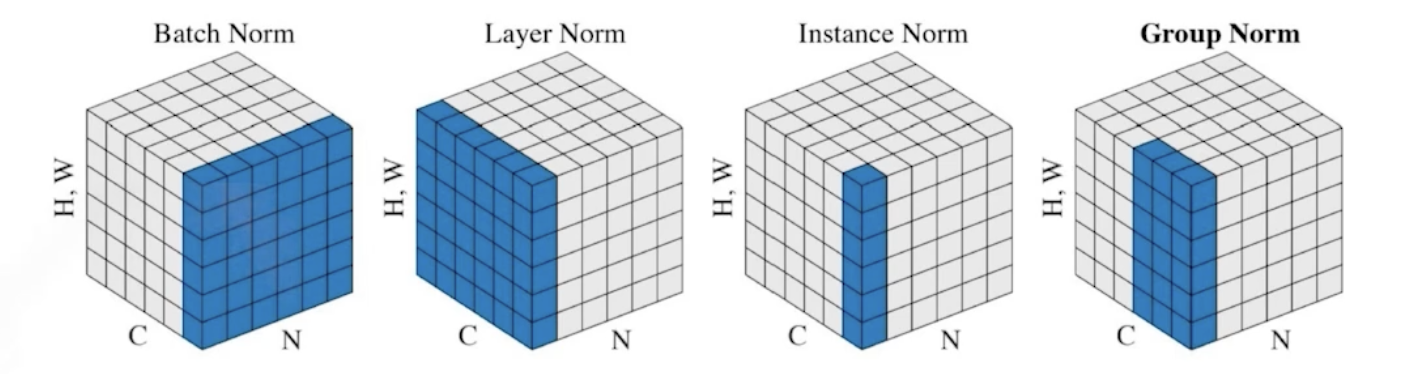
Batch Normalization
- 적용하려는 Layer의 모든 parameter에 대해, 평균을 빼고 표준편차로 나눈다.
(예를들어 모두 100정도의 값을 가지고 있었으면 0으로 줄이는 동작) - 후속

{kind=link}