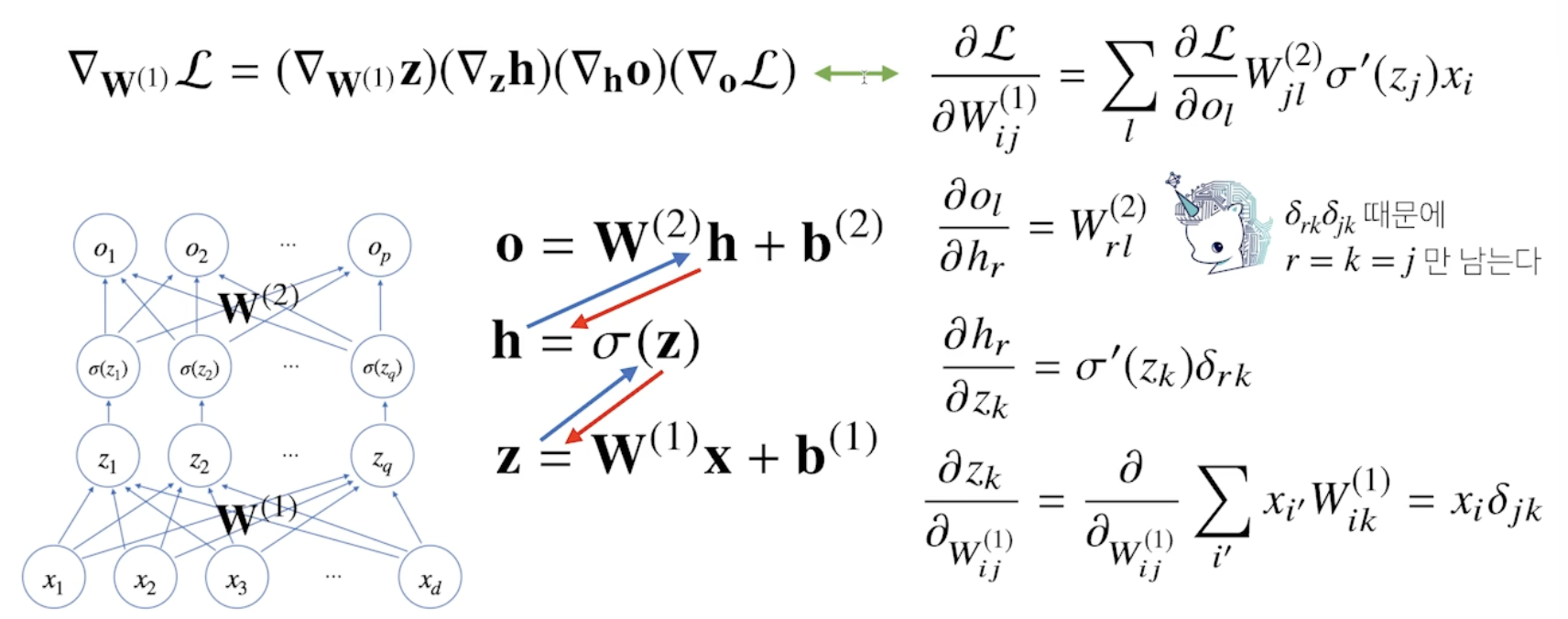신경망
- Neural Network 신경망
: 비선형 모델
: 선형모델과 비선형 함수의 결합
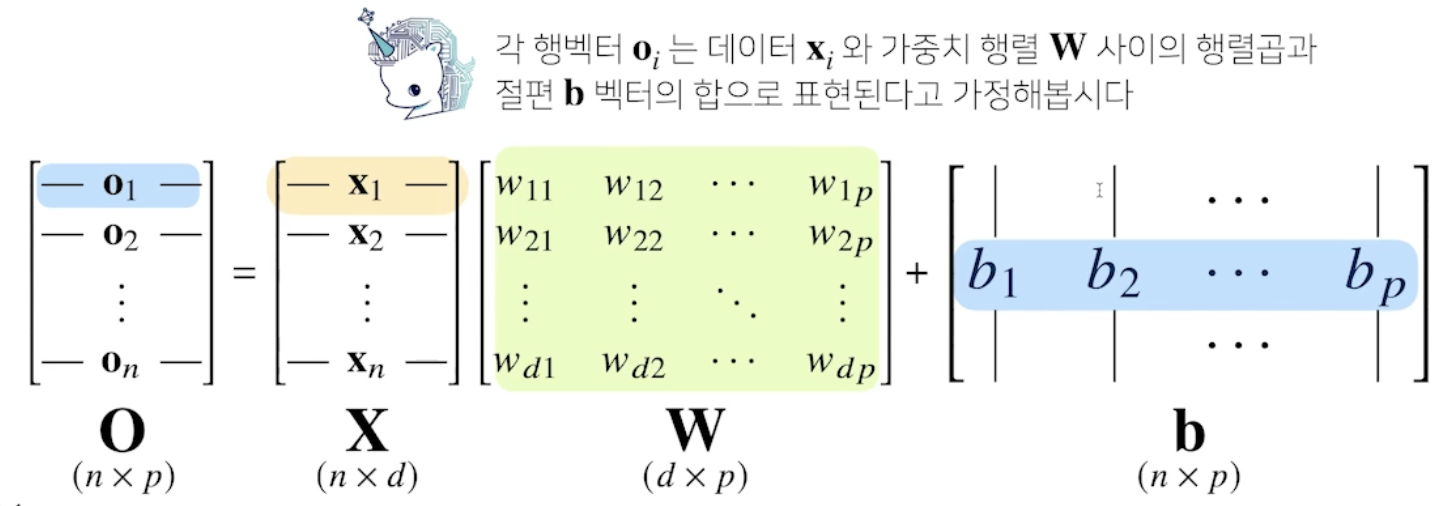
선형 모델
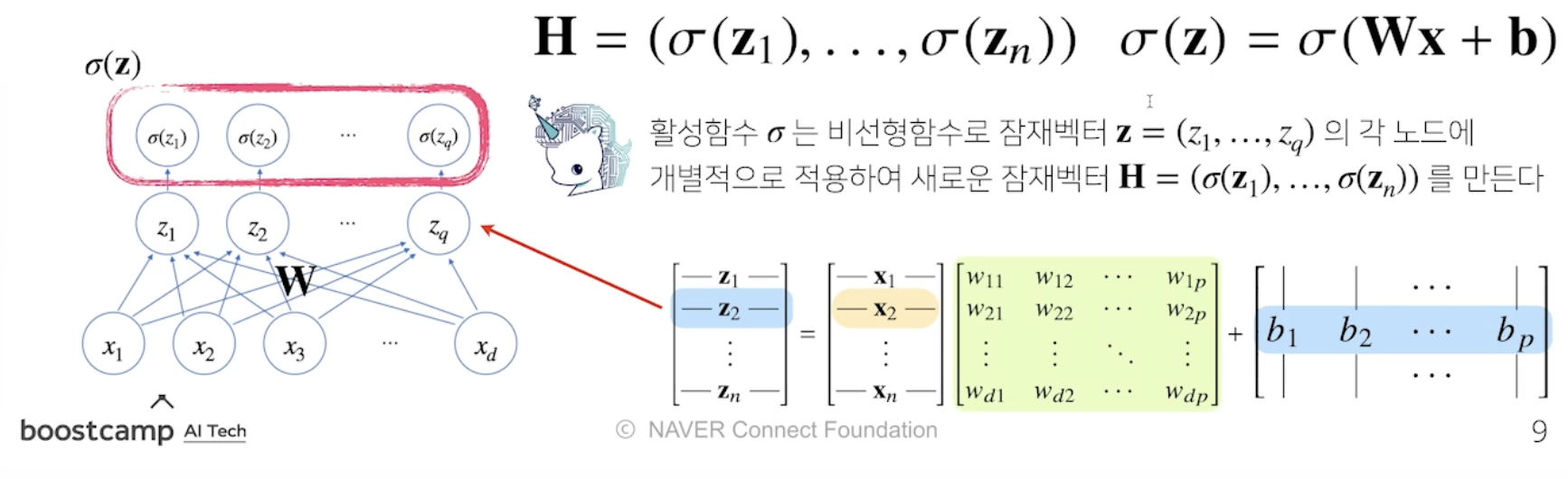
- X : 데이터 행렬
W : 가중치 행렬
b : y절편(Bias)
O : 결과
softmax
- 분류 문제에서 사용
- 모델 출력을 확률로 해석(변환)

- 구현
- vec -np.max()
: 너무 큰 값이 지수함수에 들어오면 overflow발생 가능하므로 최대값을 뺀 후 연산

Cross Entropy
: softmax에 대한 loss function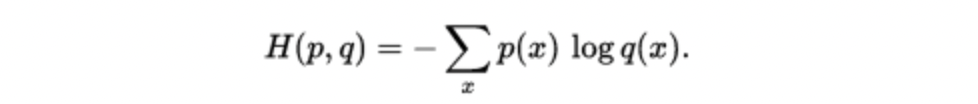
- vec -np.max()
one-hot vector
: 가장 큰 값만 1, 나머지는 0으로 값을 가지는 vector
- 학습 할 때는 softmax
- 마지막에 추론 할 때는 one-hot
- 학습 없이 추론만 하면 softmax필요 없이 one-hot만 쓰면 된다.
: 확률로 변환 안 해도 최대값은 똑같으므로
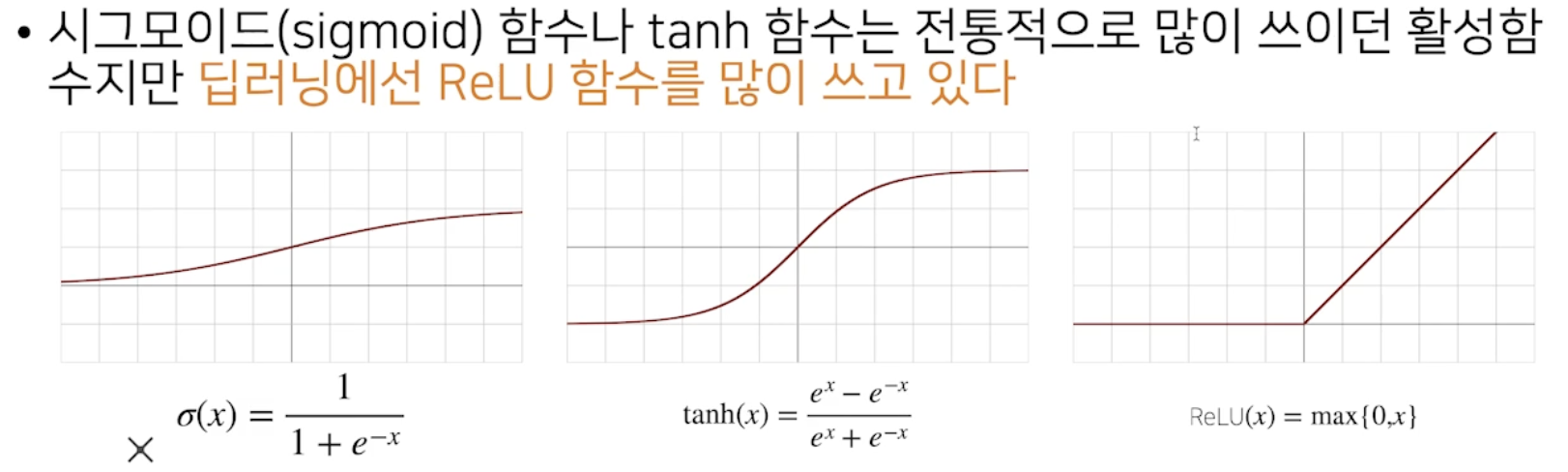
활성함수 activation function
활성 함수
: 비선형 함수
- 활성함수 종류
신경망
- Perceptron
: 선형 모델의 output에 활성함수를 씌운 구조의 NeuralNet신경망 - 신경망에서 활성함수를 씌우지 않으면 선형모델과 차이가 없다.
MLP
- 여러 (선형모델)Layer를 반복적으로 거쳐서 최종 output으로 연결
: Multi Layer Perseptron - 선형모델 중간에 활성함수를 거쳐야 한다.
- nonlinear function(활성함수)가 중간에 없으면, 선형 모델과 다를바없다.
( W1 W2 X = W3 * X )
 ( : forward propagation)
( : forward propagation)
back propagation
- 각 층에 gradient descent 적용
- 모든 W의 원소, B의 원소만큼 gradient descent 적용
- 역순으로 순차적으로 적용
- Chain-Rule 활용