Pandas
- 구조화된 데이터 처리를 지원하는 Python 데이터분석 라이브러리
- Numpy와 통합하여 기능을 제공하여, 스프레드시트 처리 기능이 강력해졌다.
- Python계의 엑셀
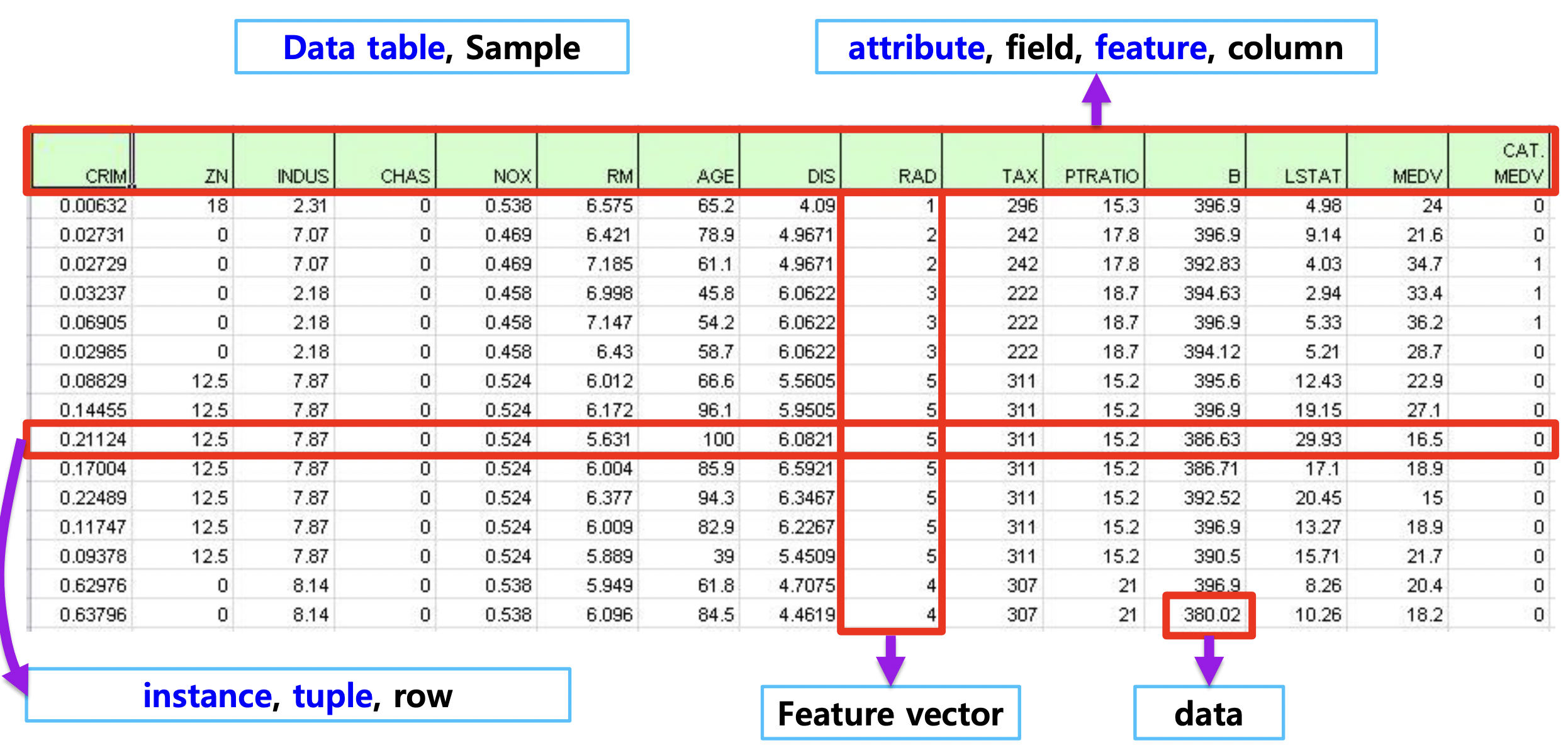
- Tabular : 테이블형태의 (행렬)데이터 (엑셀의 Sheet)
라이브러리 호출
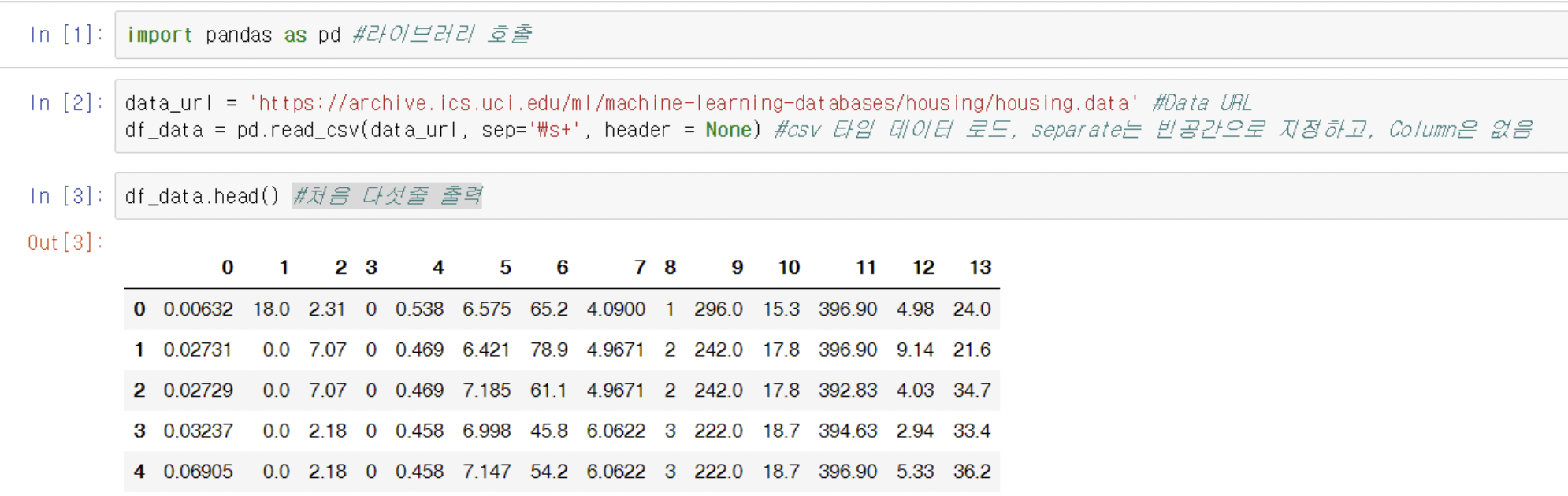
import pandas as pd데이터 로딩
- df_data = pd.read_csv()
: csv파일을 로드해옴 - df_data.columns = [" ", " "]
: Columns Header 이름 지정 - df_data.values
: 모든 데이터를 ndarray 타입으로 반환
pandas의 구성
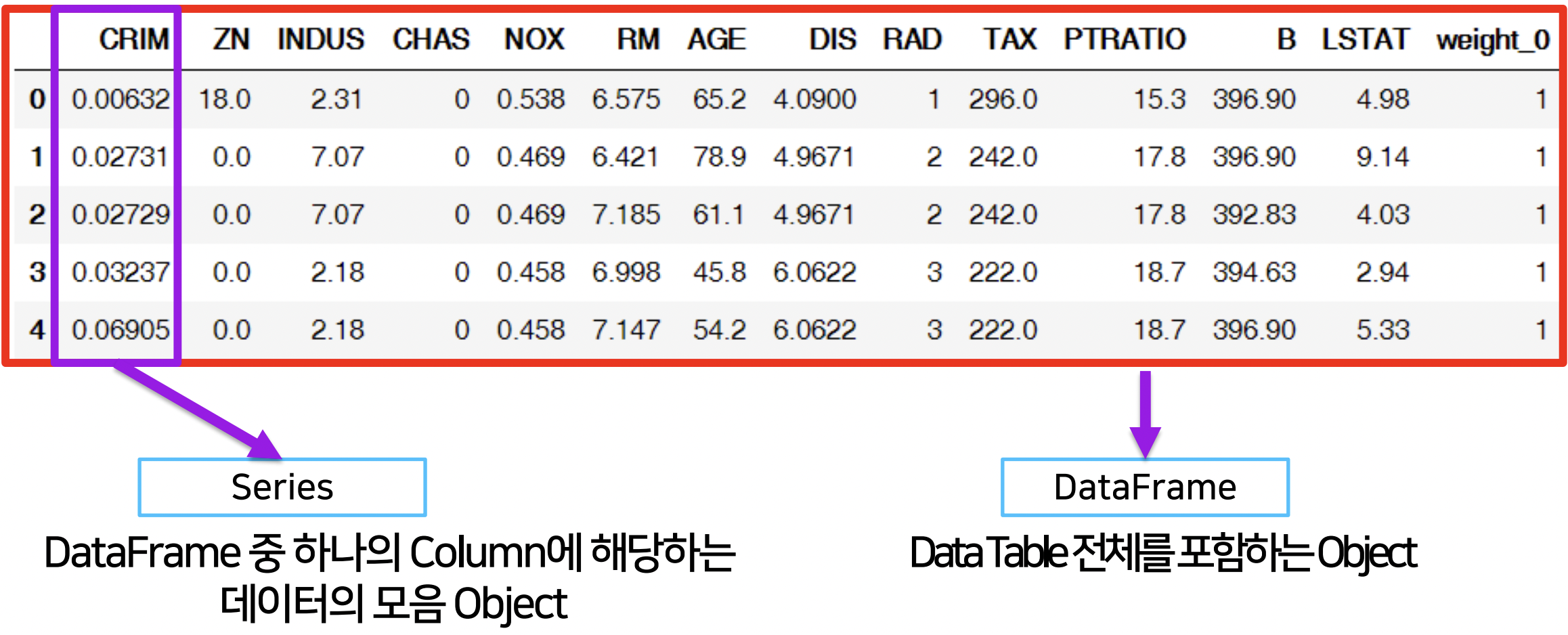
Series
: DataFrame 중 하나의 Column에 해당하는 Object
- ndarray를 기반으로 만든 ndarray의 subclass
- ndarray와 달리 index가 있다.
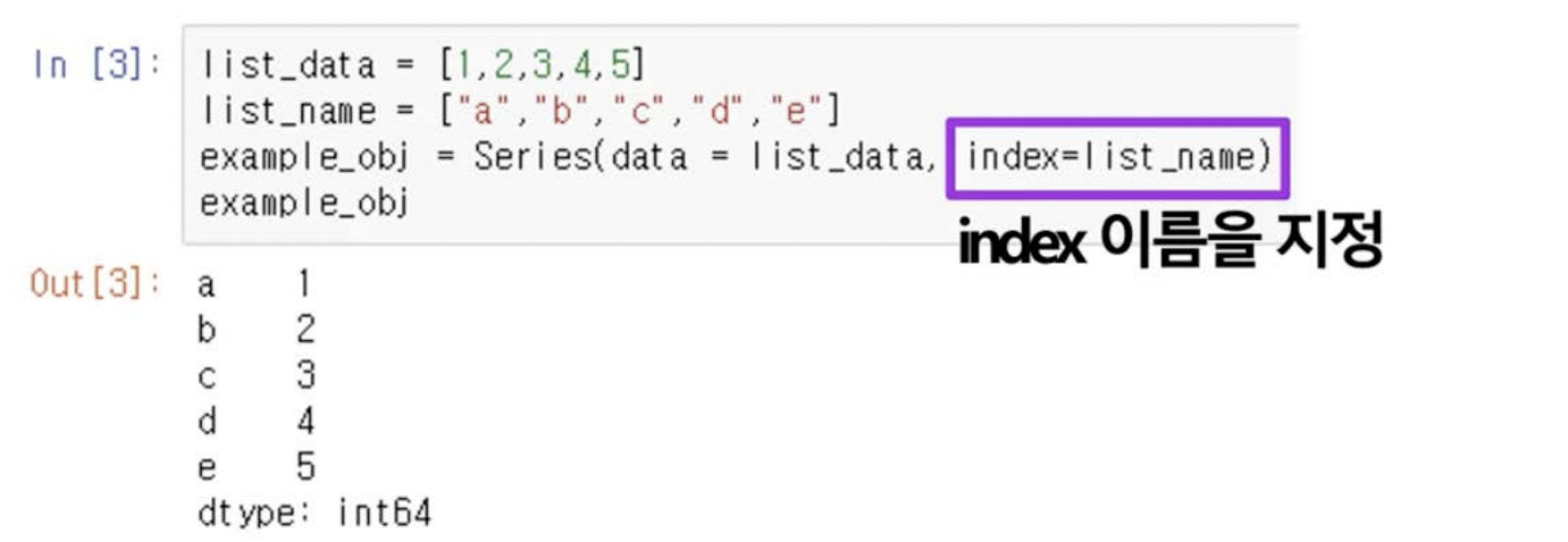
생성
- index는 문자로도 설정 가능
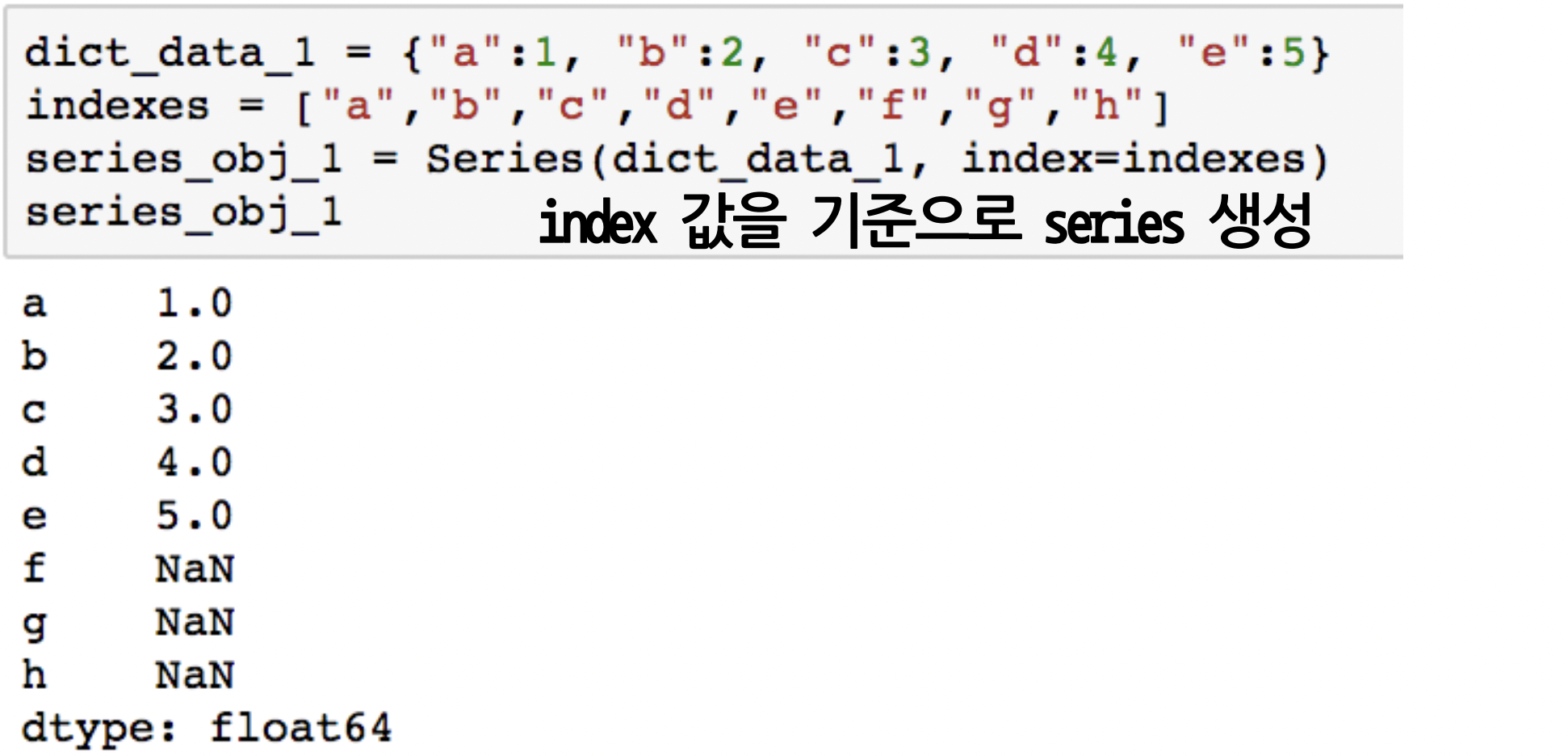
- Dict type으로도 Series 객체 생성 가능

- 값 할당을 안 하면 NaN 할당
data 호출
- index로 접근 가능
- my_series[2]
my_series["apple"] - my_series["a"] = 2

- my_series[2]
변수
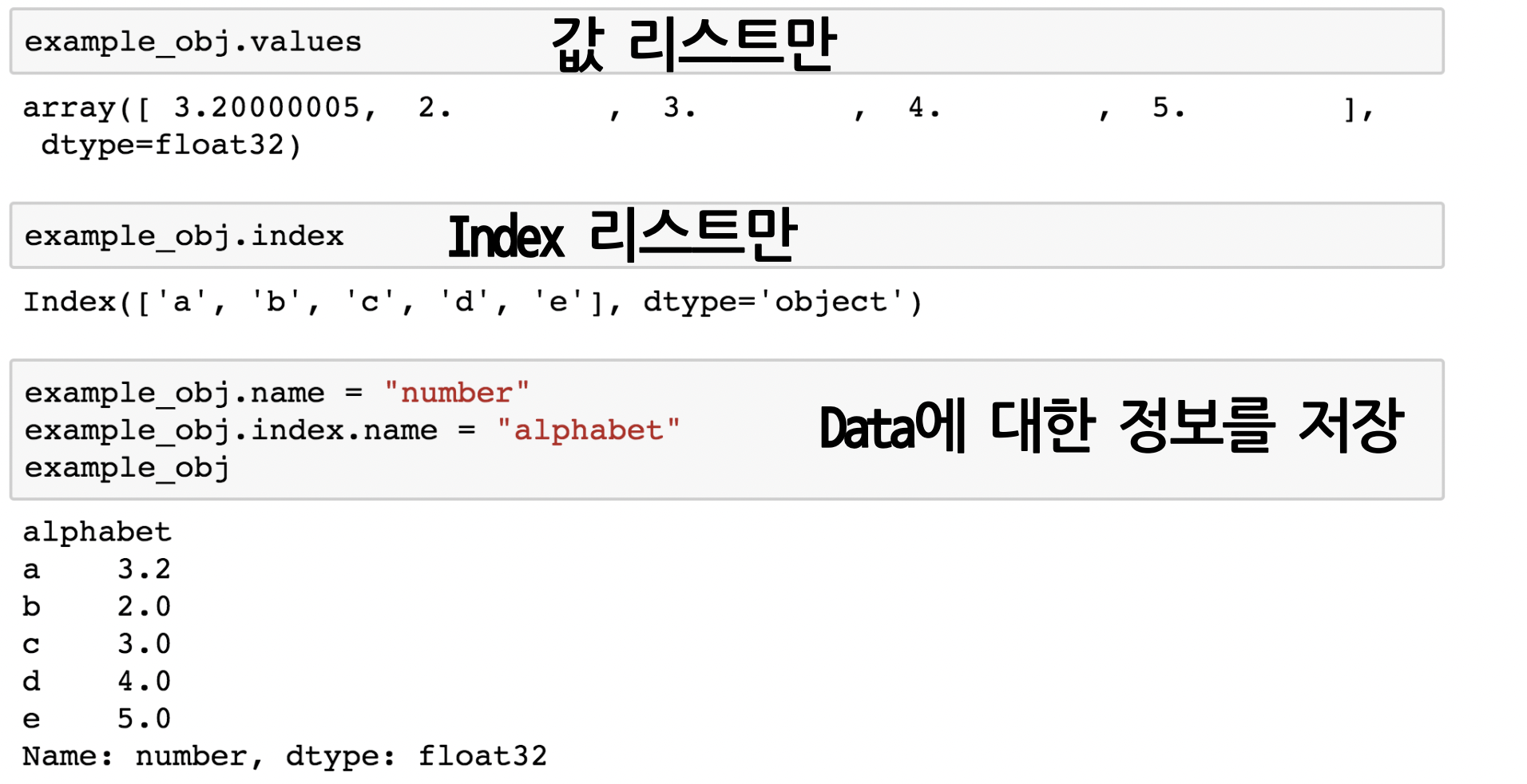
- my_series.values
: 값들 ndarray로 리턴 - my_series.index
: index값들 ndarray로 리턴 - my_series.name
: series 객체의 이름 - my_series.index.name
: index의 이름
DataFrame
: data table 전체에 대한 Object
- Series를 모아서 만든 Data Table
- column(feature) 마다 datatype이 각각 지정되어 있다.
: 각각 하나의 Series이기 때문에
생성, 접근
feature(column) 접근
- 특정 (Series data) feature data 접근 - 2가지 방법
- df.feature1
- df["feature1"]
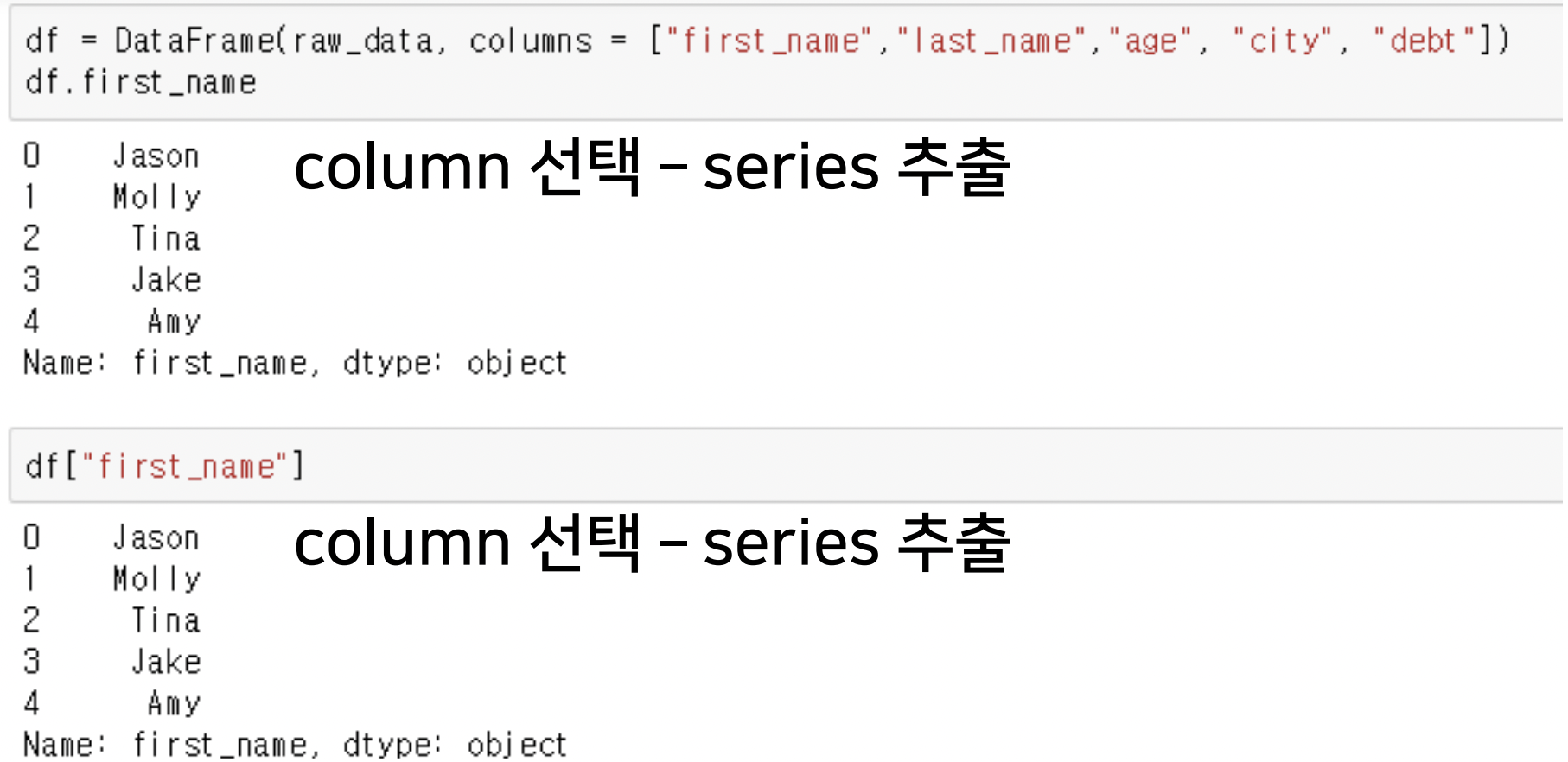
- 한개의 feature 선택
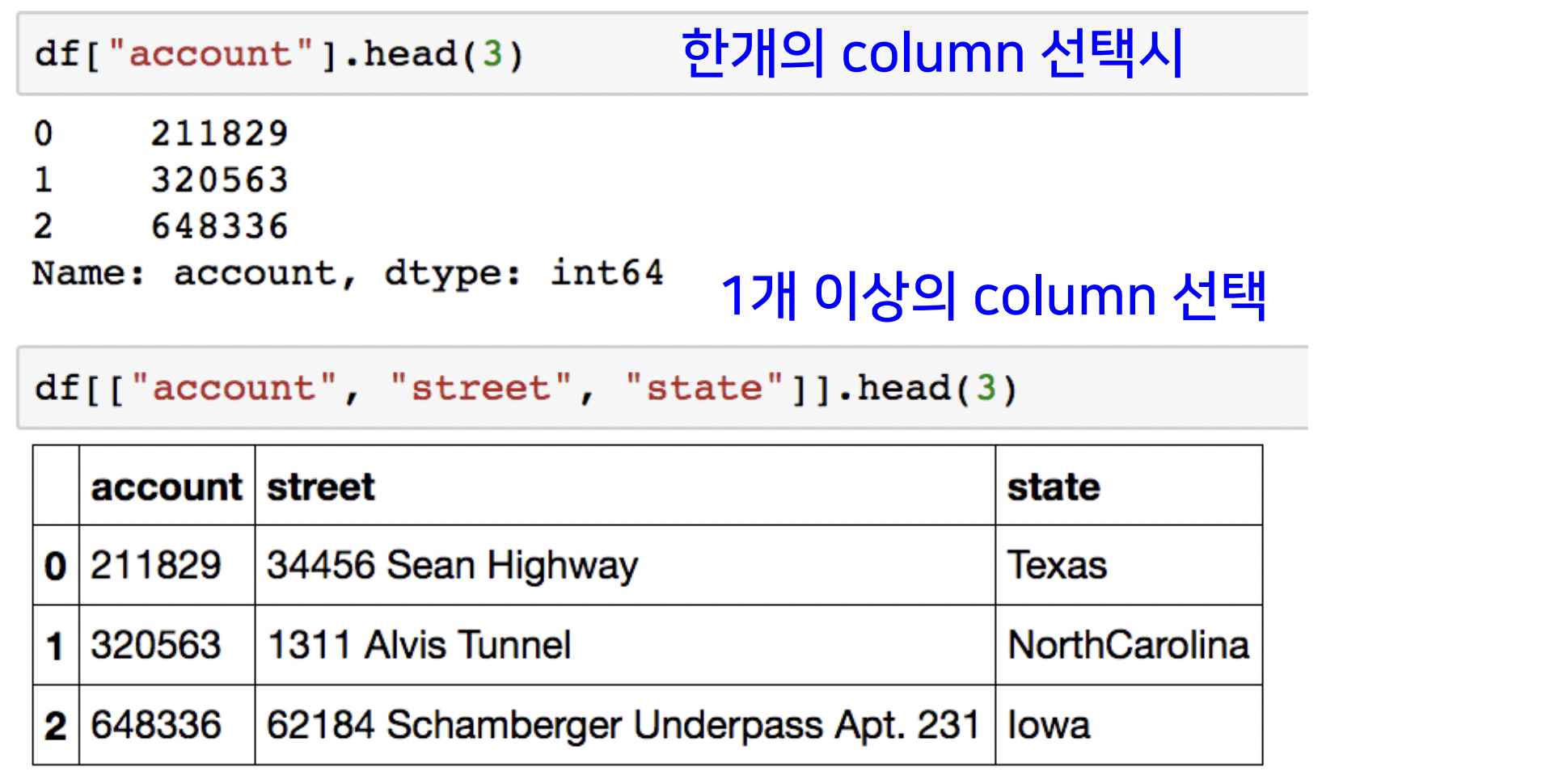
-> Series 리턴 - 여러개 feature 선택 : list형태로 feature들 넘겨줘야함
-> DataFrame 리턴
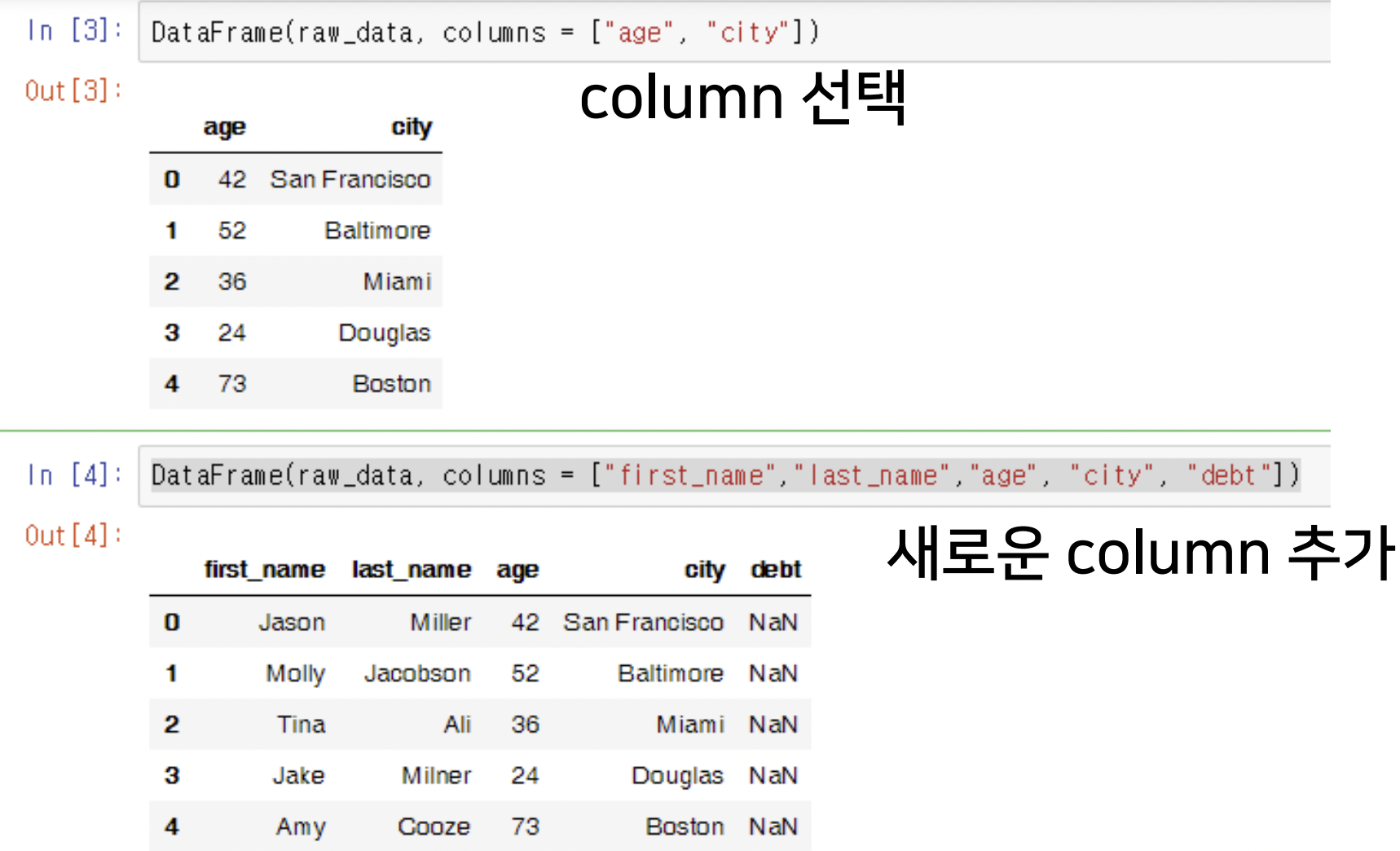
- DataFrame 생성
- 불러온 전체 DataFrame 중 일부 feature(column, series)만 선택해서 새로운 DataFrame 생성
: 새로운 feature 추가도 가능
- 실제로는 DataFrmae()함수 안 쓰고 그냥 feature 접근으로 DataFrame 생성
(생성하면서 새로운 feature 추가는 불가능)
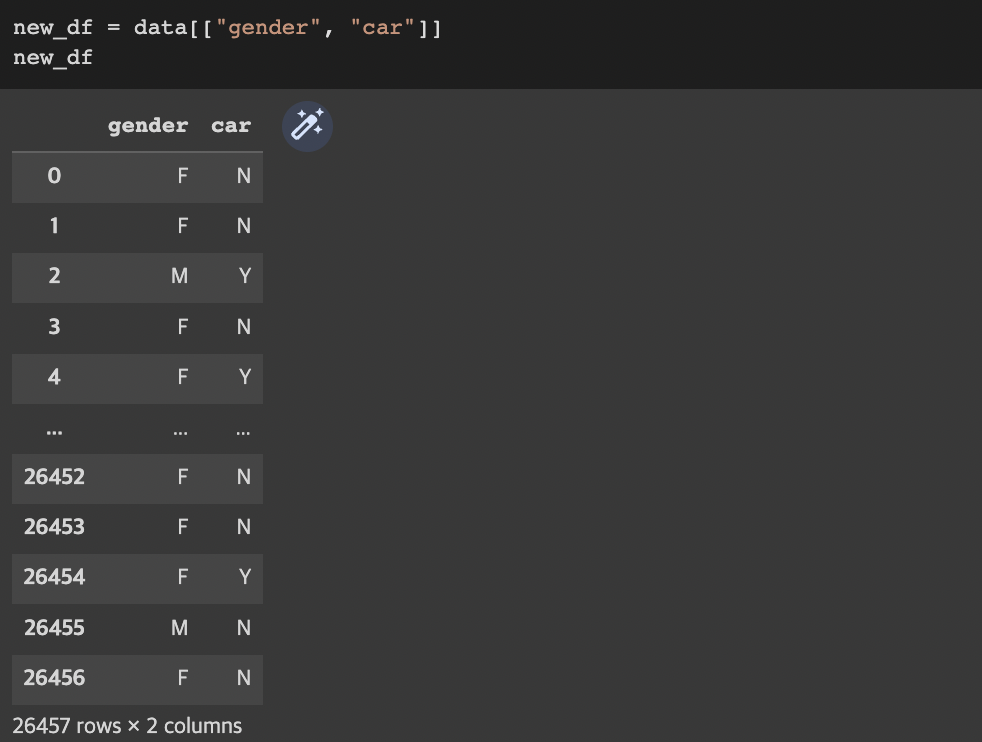
- 불러온 전체 DataFrame 중 일부 feature(column, series)만 선택해서 새로운 DataFrame 생성
조건에 맞는 feature data 접근
- Series(ndarray)의 조건연산자를 활용하여 조건에 맞는 feature의 data들만 뽑아올 수 있다.
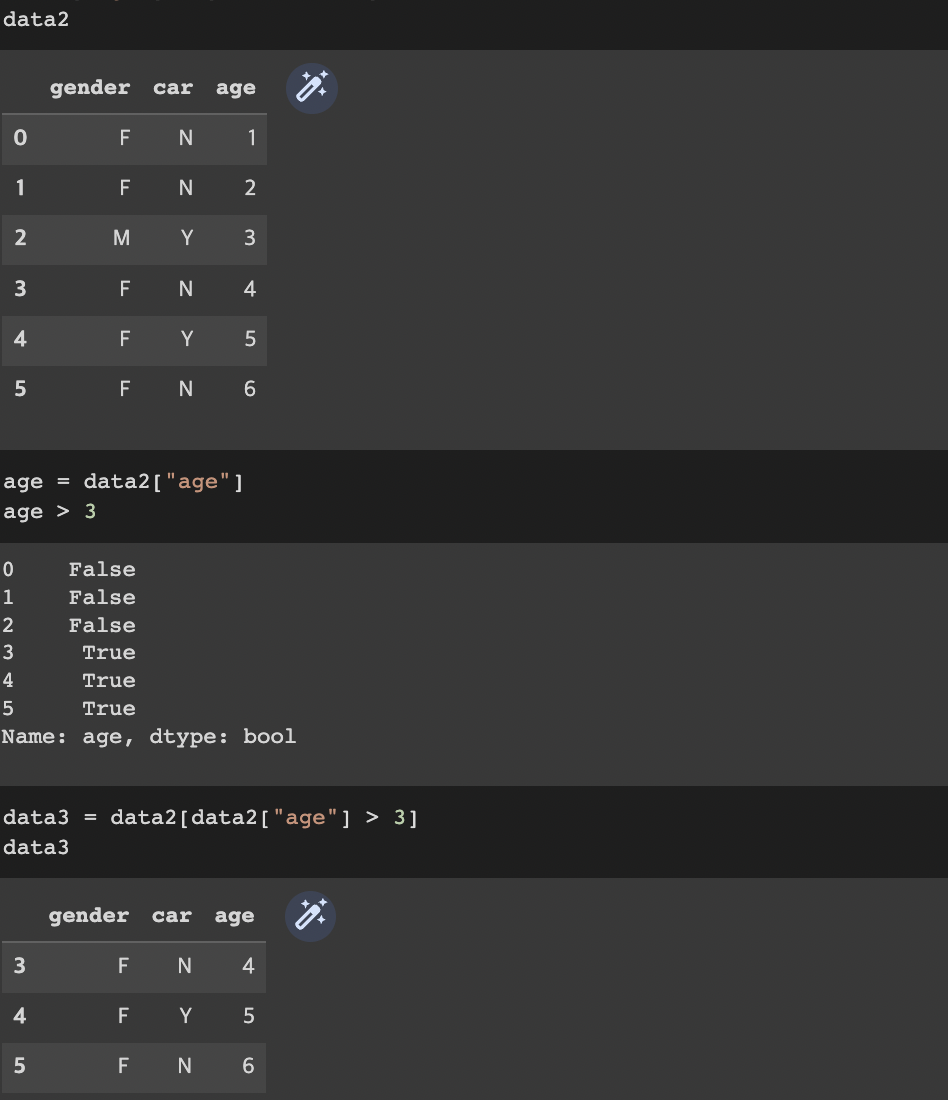
index(row) 접근 _ loc / iloc
- indexing된 새로운 DataFrame 리턴
- Indexing
- df.loc[인덱스의값] / df.loc[인덱스의값:인덱스의값]
: index의 값으로 접근 _ 문자열이면 문자 열값으로 접근
: 해당 index 명이 존재하지 않는 경우에는, 새로운 행으로 데이터가 추가 - df.iloc[n:m]
: index를 0부터 할당해 숫자로 변형한 position을 이용해 범위 data 접근
: 행 추가는 안 되고, 수정 만 가능
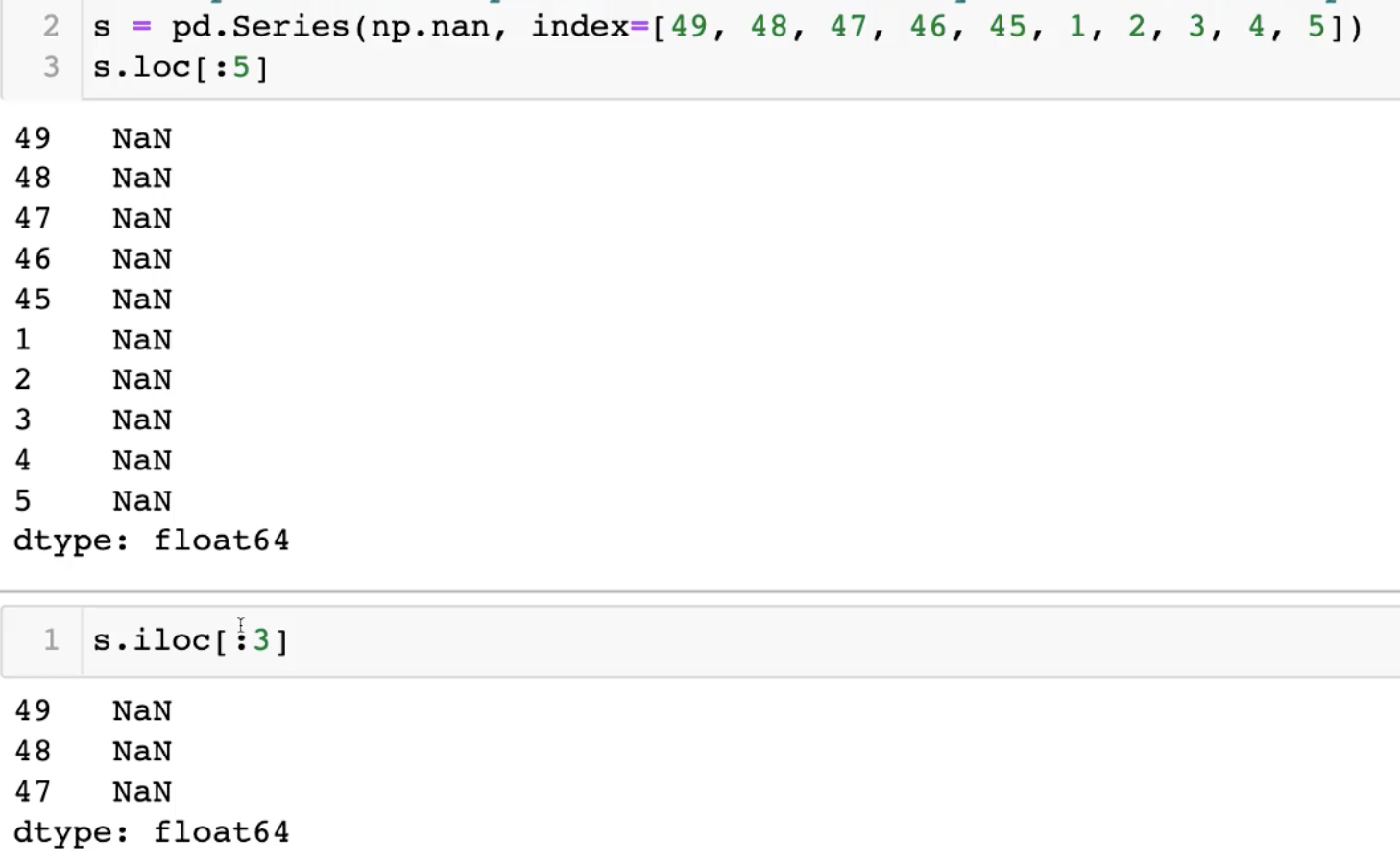
- df.loc[인덱스의값] / df.loc[인덱스의값:인덱스의값]
- df[n:m]
@df["feature"]로 접근하면 해당 feature(column) 기준으로 접근하지만, 숫자(index)를 넣으면 row 기준으로 data을 뽑아온다.
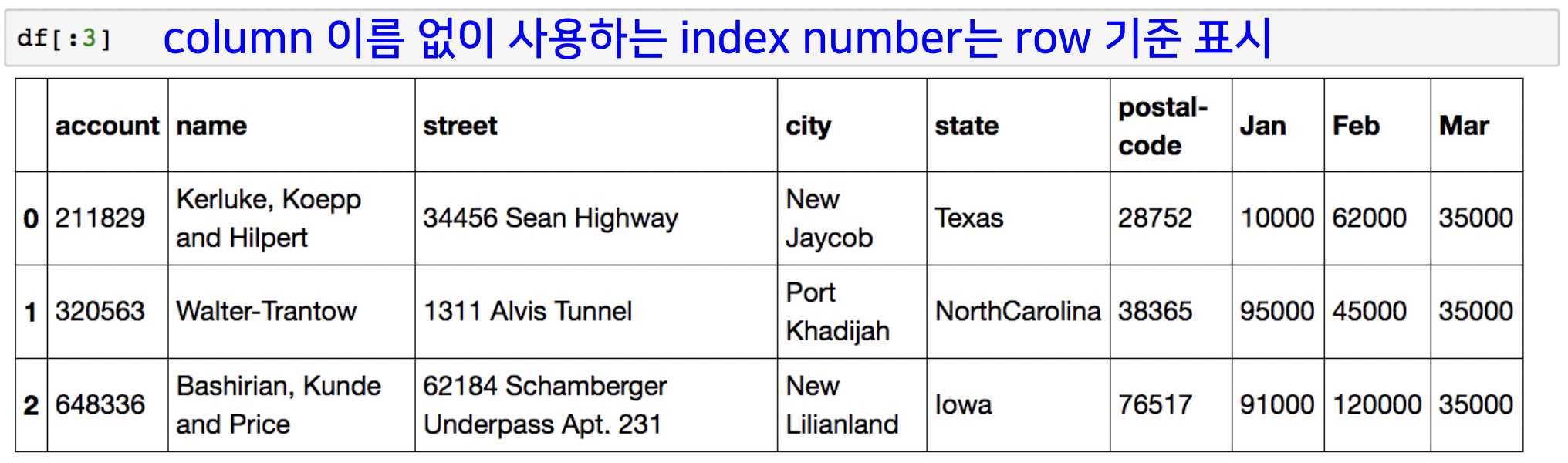
feature, row 동시 접근
- df["feature1"][n:m]
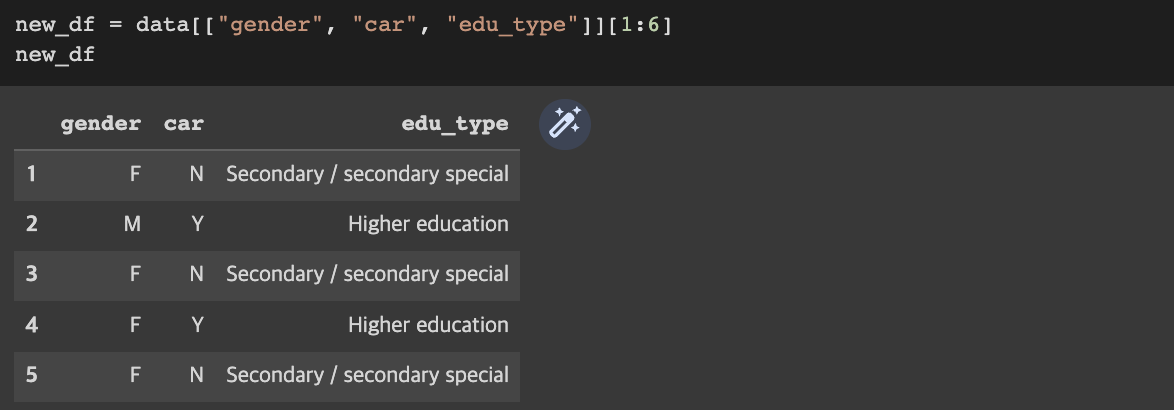
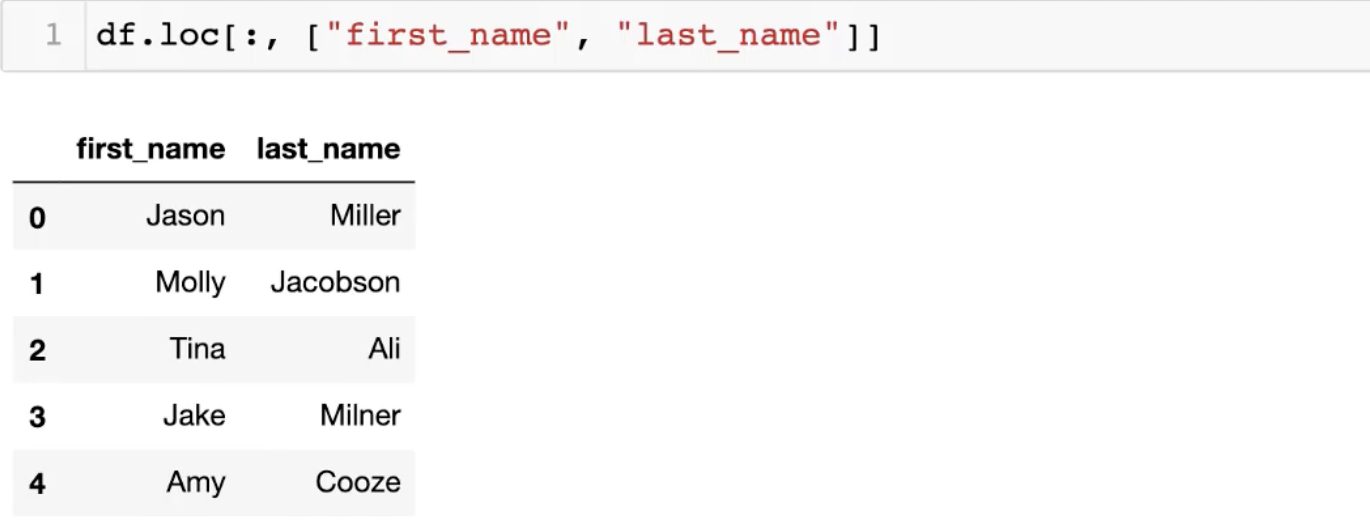
- df.loc[a:b, ["f1", "f2"]]
- a와 b는 명확한 index의 값 (position X)
- list 형태로 feature 인자를 넘겨서 특정 feature와 index에 접근 가능
- df.iloc[n:m, i:j]
조작
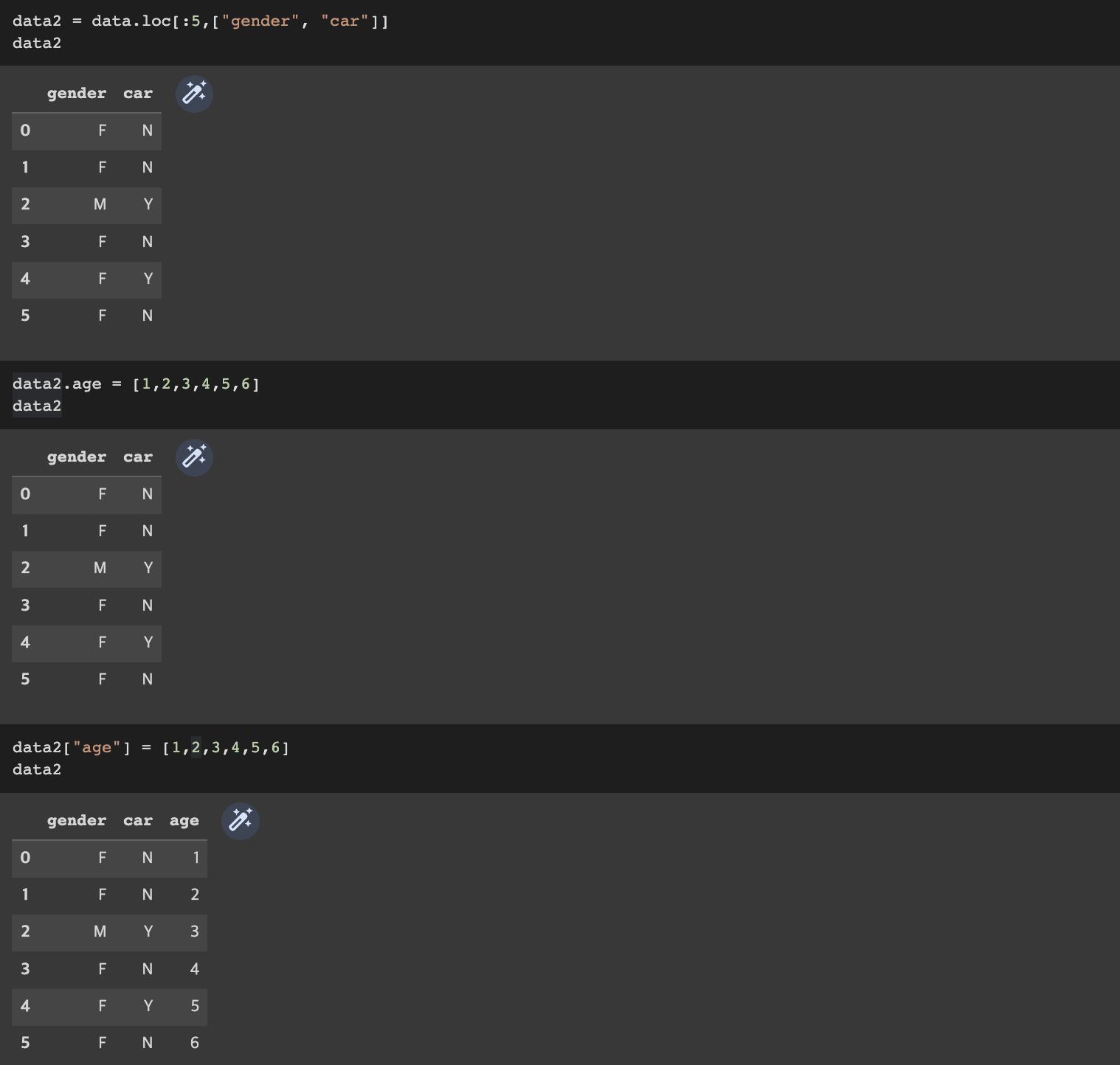
feature 추가
- df["new_feature"] 접근법으로만 새로운 feature 추가 가능
- Boolean feature 생성 _ feature 비교연산자
- feature에 비교 연산자를 수행하면 각 data값에 대한 연산 결과 Boolean값으로 구성된 새로운 Series 리턴
- 새로 추가한 feature에 조건을 이용한 Boolean data 추가
feature 삭제
- del df["feature_name"]
- df.drop("feature_name", axis=1)

- df.drop("f2", axis=1, inplace=True)
: df 자기 자신에도 "f2" feature 삭제 동작이 적용"inplace = True" 파라미터
: DataFrame의 함수들은 기본적으로 객체 본체에 변화를 주지 않고, 함수를 적용한 새로운 DataFrame을 리턴 할 뿐이다.
: inplace에 True 값을 주면 함수를 호출한 DataFrame 객체 본체에 변화가 적용된다.
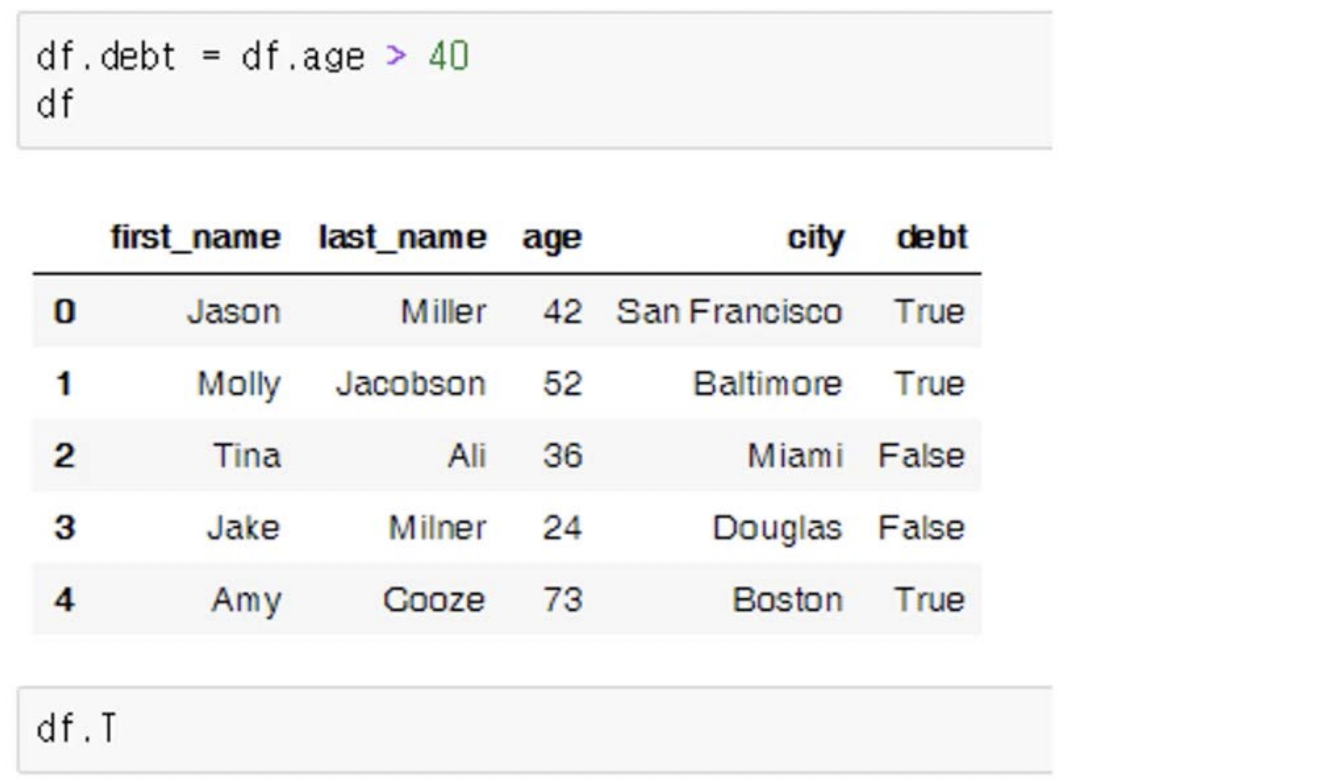
index 재설정
- df.index = list(range(n))
- df.reset_index()
: index가 하나 더 생긴다. (df 자신은 두고 조작한 DataFrame 리턴)- df.reset_index(drop=True)
: 기존 index를 죽인다. - df.reset_index(inplace=True, drop=True)
: df 자기 자신에도 변화가 적용된다.
- df.reset_index(drop=True)
Operation
- 한 쪽이라도 값이 없으면, 결과가 NaN값으로 할당
- (fill_value=x) 파라미터를 통해 NaN값 대신 들어갈 값을 설정 가능
- 한 쪽에 어떤 index가 2개 이상 있으면 각각에 대해 모두 연산을 수행하여 결과 row 여러개 생성
- Series

- DataFrame

- Series
map
- Series 데이터에 map 함수 사용 가능
: 각 element에 설정한 값을 mapping - DataFrame(여러개의 Series)에 호출 불가능
- 원본 data를 바꾸려면, 역시 inplace에 True를 줘야한다.
- Series 정보
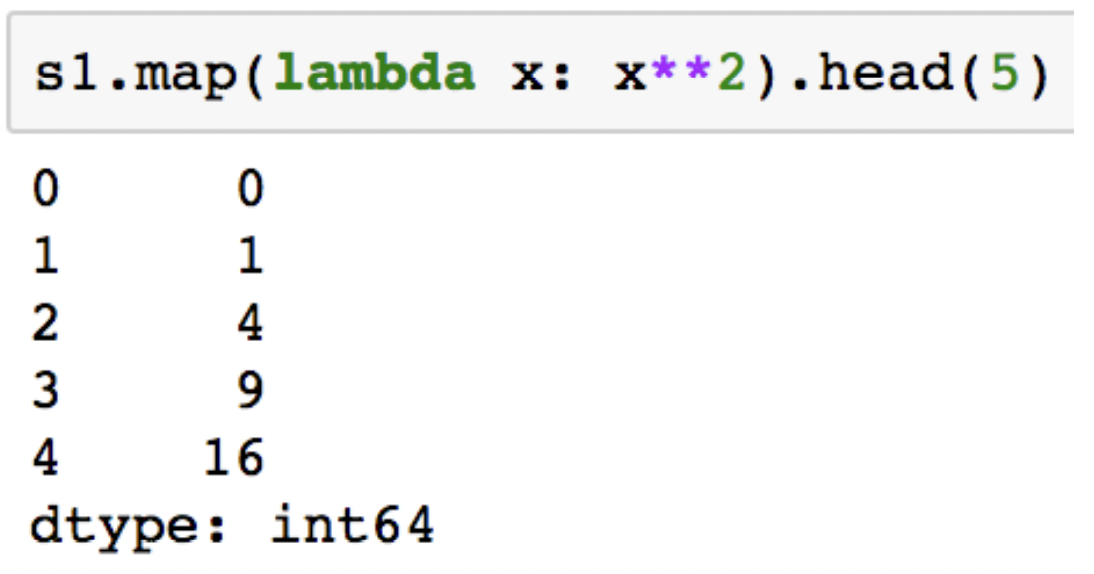
- lambda 식
: Series의 각 element에 lambda 수식 적용
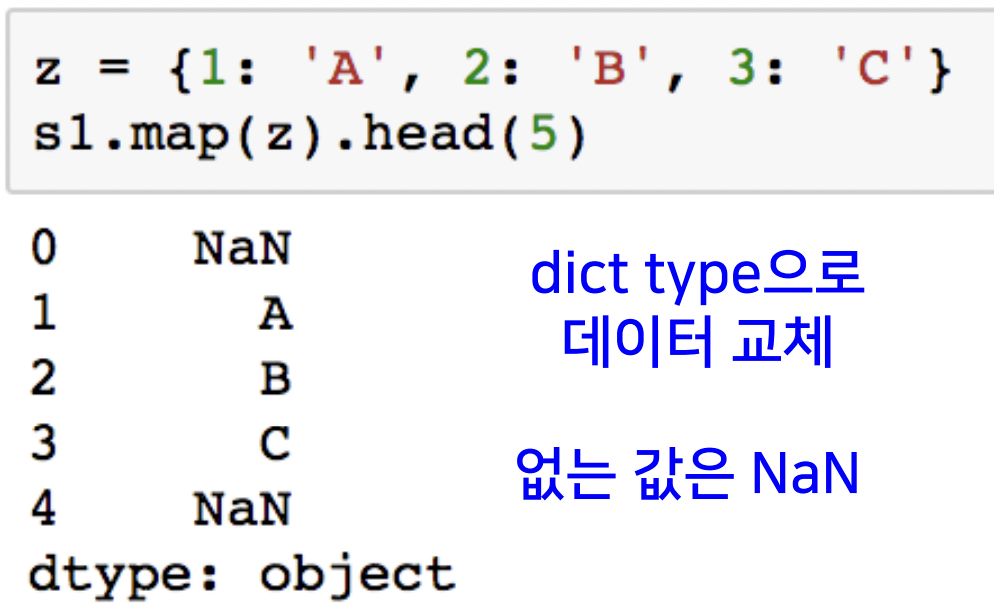
- Dict type
: Dict data를 넘겨줌으로써, 대응하는 값으로 element 값 변경

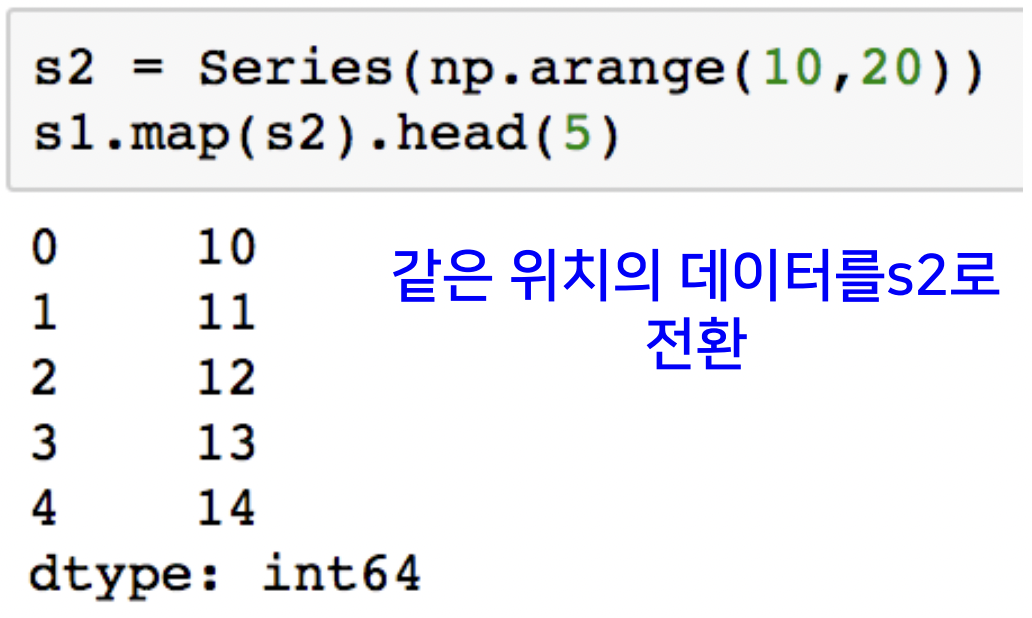
- Series data
: Series 객체를 넘겨줌으로써, 대응하는 index위치의 데이터로 변경
- lambda 식
apply
- DataFrame(여러개의 Series)에 호출
- column(feature) elements 값들 전체에 대한 연산 수행
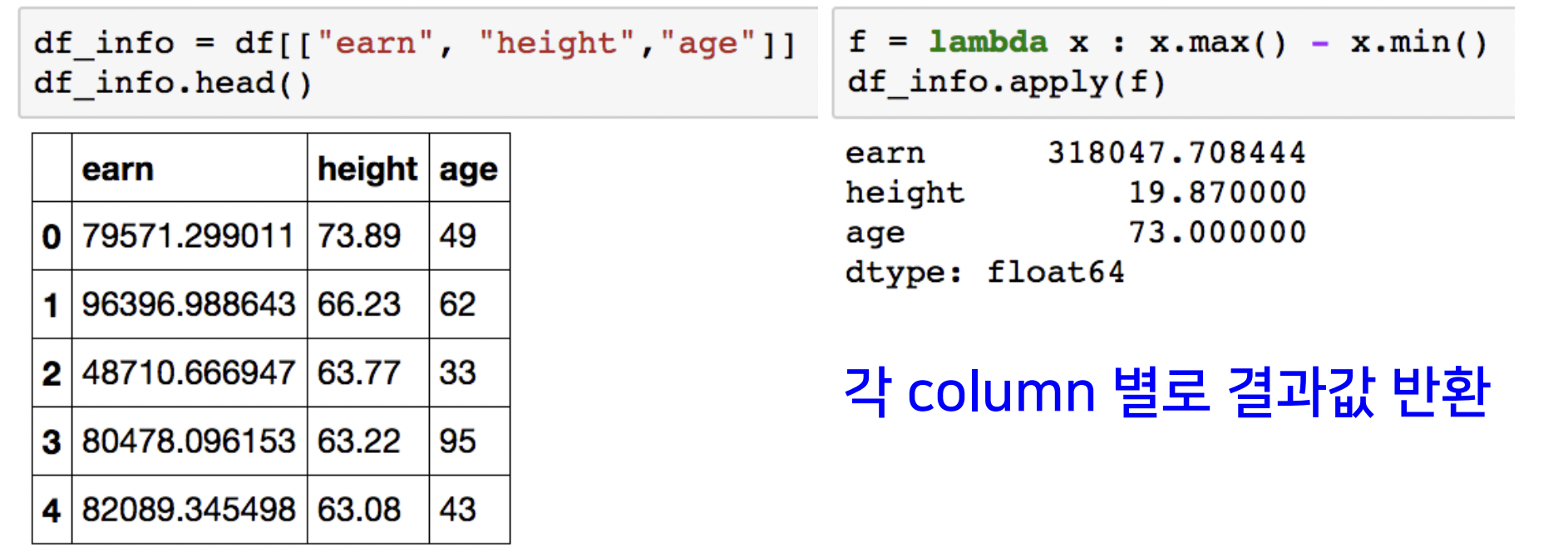
- Series 단위에 호출하면 map과 역할이 같음
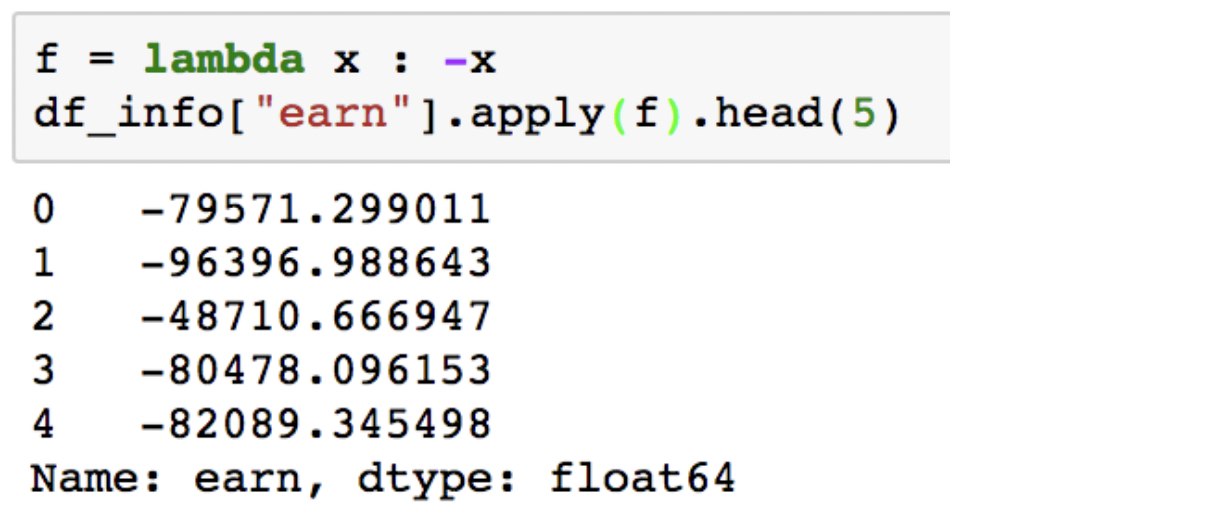
- 내장 함수와 동일한 역할
applymap
- DataFrame(여러개의 Series)에 호출
- map, Series에 호출한 apply처럼
모든 element 값들에 각각 함수 연산 적용

pandas의 함수 (built-in function)
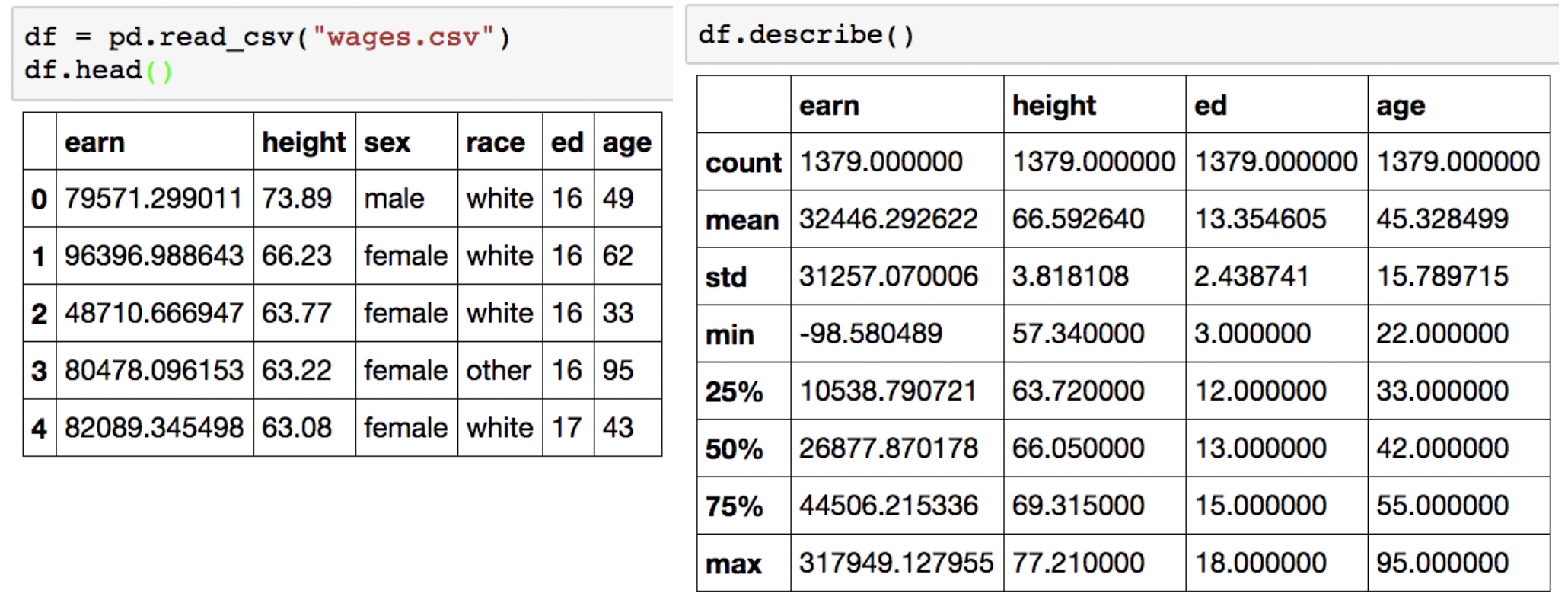
df.describe()
: (Numeric type)수치형 변수의 데이터 요약 정보를 출력
df["f1"].unique()
- Series data의 유일한 value를 (value의 종류) list로 리턴

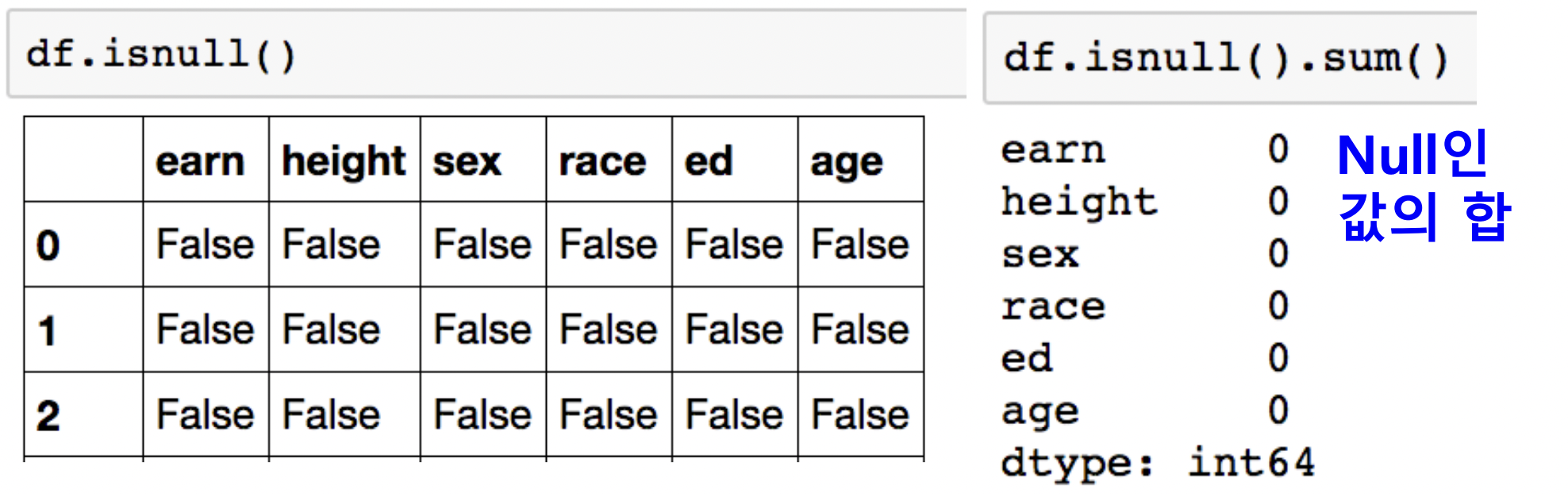
df.isnull()
- NaN(null)이면 True, 값이 있으면 False
- sum() 함수를 이어서 쓰면 결측치 data 개수를 반환 가능
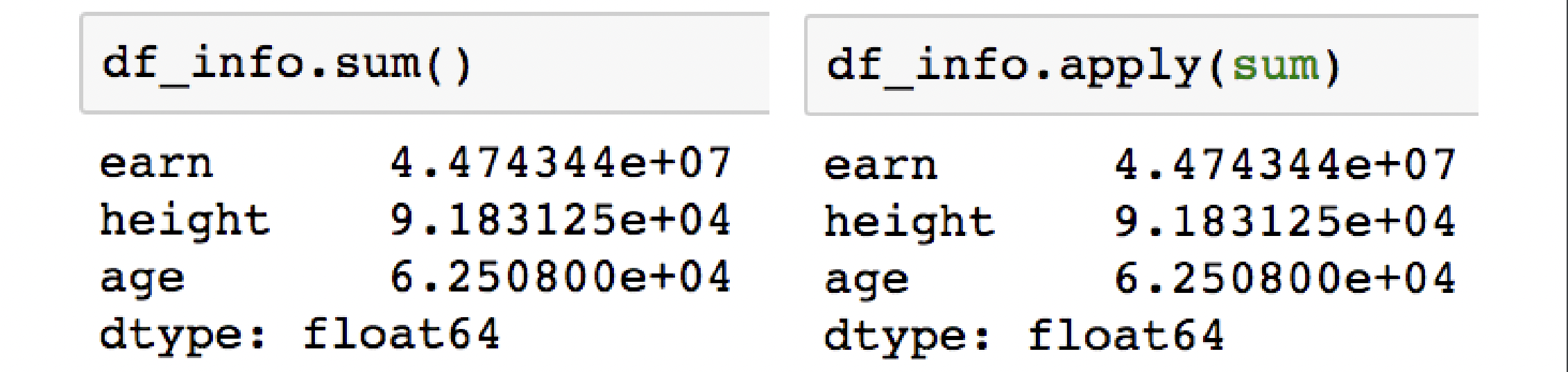
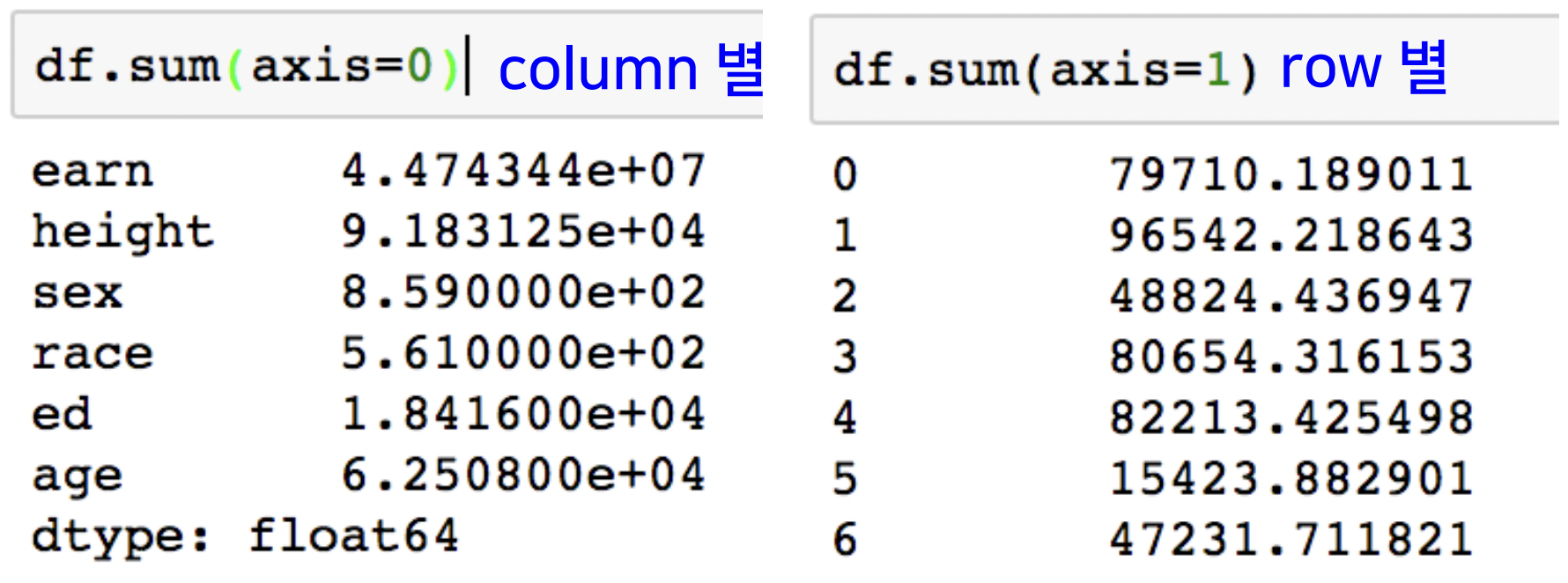
df.sum(axis= )
- axis=0 : column(feature) 합
- axis=1 : row (index) 합
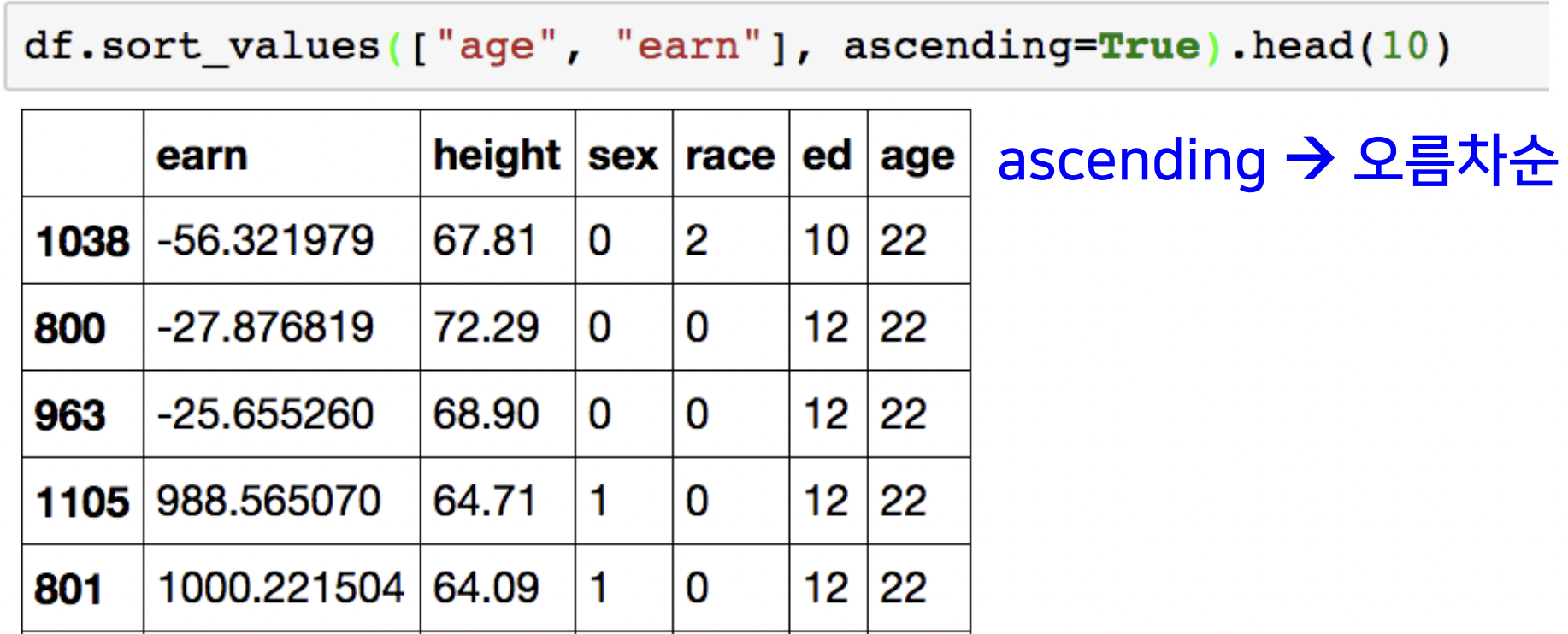
df.sort_values()
- feature를 기준으로 정렬
- ascending : 오름차순
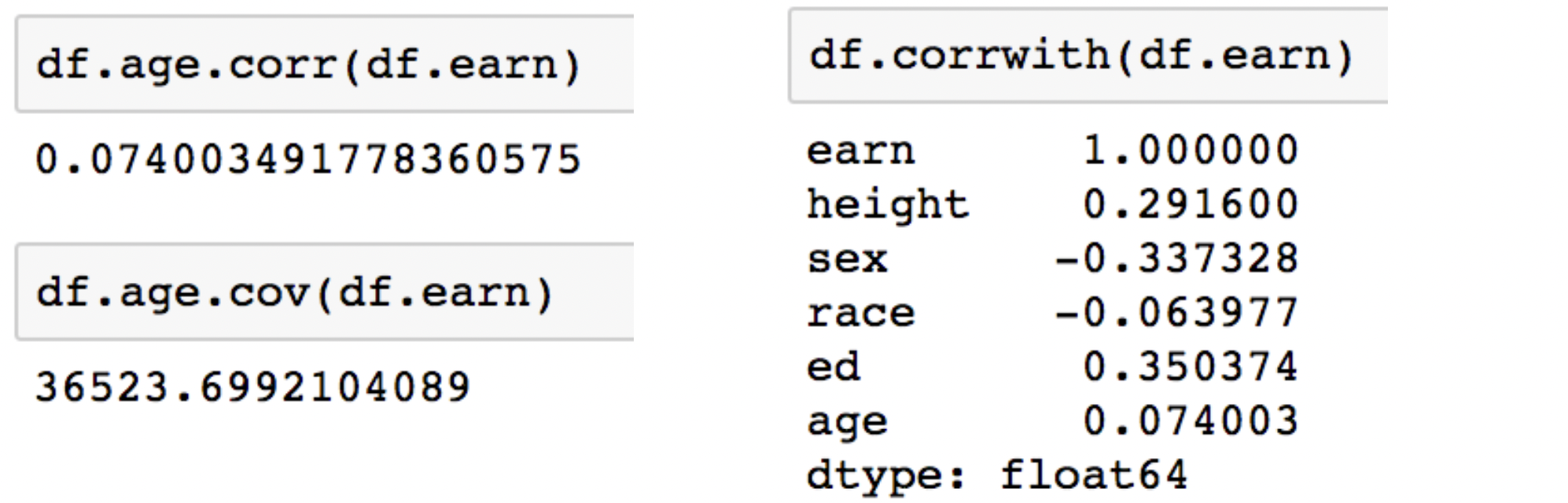
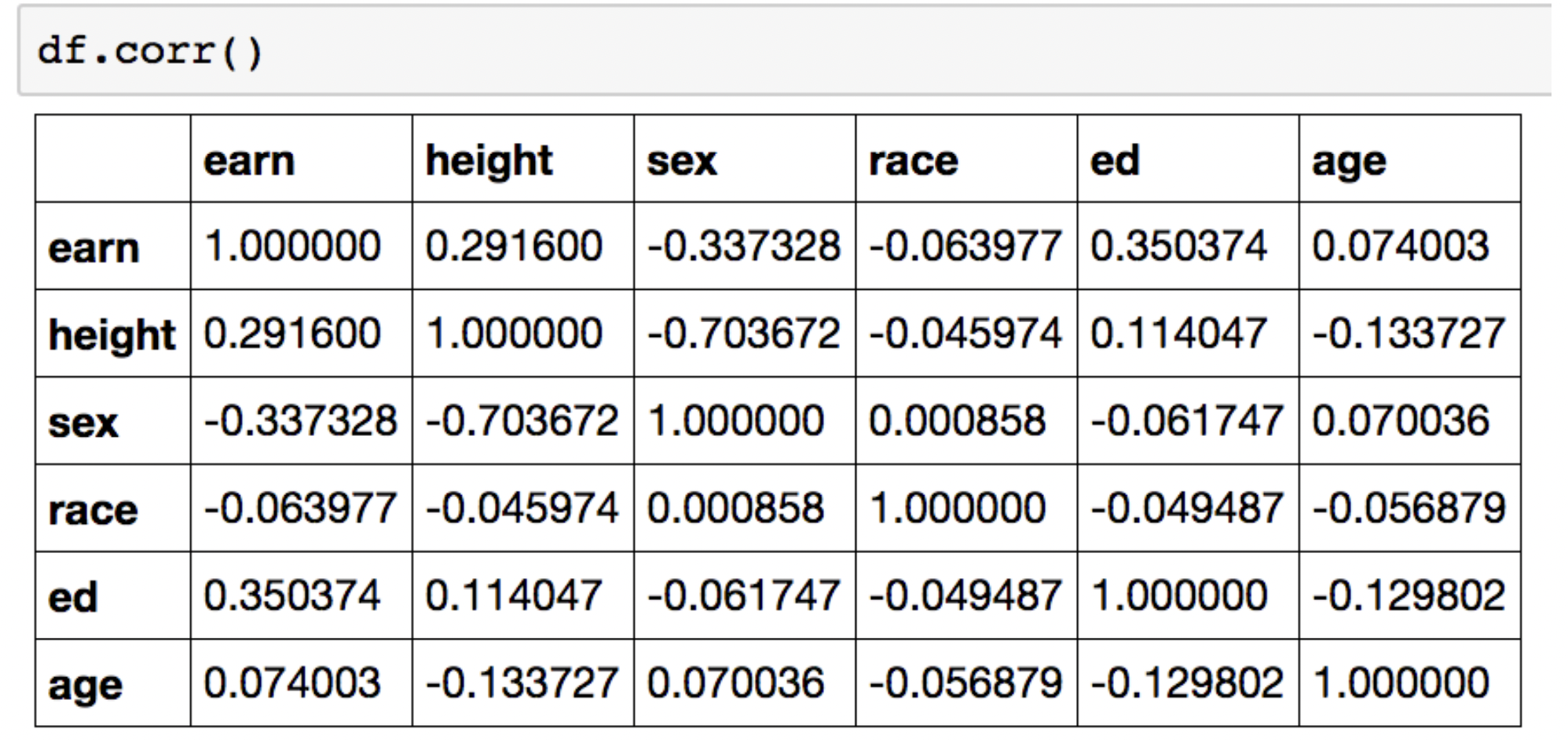
Correlation & Covariance
- correlation : 상관계수
covariance : 공분산 - df["f1"].corr(df["f2"])
df["f1"].cov(df["f2"])
: 두 feature에 대한 수치를 리턴