C++의 배열
- c++의 array : 연속된 메모리 공간을 할당받는다. 인덱스가 있다.
- c++의 list : double linked list (할당된 메모리 공간이 연속되지 않을 수 있다.) 인덱스로 각 elements에 접근할 수 없다.
- c++의 vector
pyton의 list
- Dynamic Array
- 연속된 메모리 공간 할당 받는다.
- index가 있다.
- 한 list에 다른 타입의 elements를 저장 할 수 있다.
- 문자열과 달리 list는 elements가 가변함(insert, delete, update 가능)
list의 대입연산자
- iterable 타입
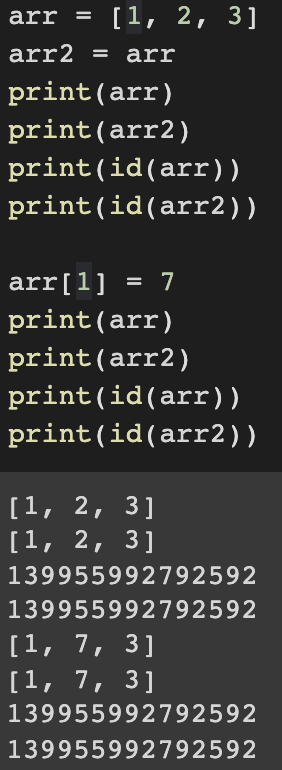
- b = a
: list a의 주소값을 b와 공유 (레퍼런스)
: 값이 바뀌어도 주소값 유지
list의 내장함수
- len(a) : list 길이(elements 개수) 리턴
- a.append(k) : list 맨 뒤에 value가 k인 element 추가
- a.insert(a,b) : index가 a인 위치에 value가 b인 element 추가
- a1.extend(a2) : (a1 += a2) list a1 뒤에 a2를 이어붙인다.
- a.remove(k) : 가장 index가 작은 value가 k인 element 삭제
- del a[i] : i번째 (index로) element 삭제
: list 본체에서 삭제
: 리턴 값 없음 - a.pop() : list의 맨 뒤 element 삭제하고, 그 value 리턴
a.pop(i) : index i인 element 삭제
: list 본체에서 삭제
: 삭제한 element 리턴 - a.index(k) : value가 k인 가장 작은 index 리턴
- a.count(k) : list에 value k가 몇 개 들어있는지 리턴
- a.sort() : list 오름차순 정렬 (본체 정렬, 리턴 : None)
: list의 내장함수
: python 내장함수
: 모든 iterable객체에 사용가능 - list 리턴 - a.reverse() : list 역순으로 뒤집기
: list 본체 재정렬
: 리턴 값 X
그 외 함수
- sorted(a) : 본체 두고 정렬된 list 리턴
- sum(a) : 모든 원소 합 리턴
empty
- 조건문에 iterable 객체 자체를 넣어서 empty판별 가능
- 조건문에서 list가 비어있으면 False, 안비어있으면 True 리턴
list1 = []
list2 = [1, 2, 3]
if not list1:
print("list1 is empty")
if list2:
print("list2 is not empty")
# list1 is empty
# list2 is not empty정렬
list.sort( )
- list.sort(key= < function > , reverse = < bool >)
- 본체 정렬
- 리턴 값 X
sorted( iterable )
- sorted(< iterable >, key= < function > , reverse = < bool >)
- 본체 그대로 두고
- 정렬된 "list" 리턴
lambda 함수
ex. 인자로 받아온 숫자x에 1을 더해서 리턴하는 함수
func = lambda x : x + 1
func(4) #5

- key
: 함수를 넣어서 정렬 기준을 설정한다.- 함수의 인자는 iterable 객체에서 하나씩 받아오는 element를 넘긴다.
- 람다 함수 사용시 매개변수 x에 element를 넘긴다.
- 정렬 기준이 여러개인 경우 우선순위대로 tuple을 람다함수 결과로 리턴한다.
str_list = ['좋은하루','good_morning','굿모닝','niceday']
print(sorted(str_list, key=len))
# ['굿모닝', '좋은하루', 'niceday', 'good_morning']array = [[50, "apple"], [400, "melon"], [30, "banana"], [50, "pear"] ]
print(sorted(array, key = lambda x: x[1]))
# [[50, 'apple'], [30, 'banana'], [400, 'melon'], [50, 'pear']]
print(sorted(array, key = lambda x: (-x[0], x[1])))
# [[400, 'melon'], [50, 'apple'], [50, 'pear'], [30, 'banana']]# index=2인 글자 순으로 정렬, 같은 단어끼리는 사전순으로 정렬
l = ["abce", "abcd", "cdx"]
l.sort(key= lambda x:(x[2],x))
print(l) #['abcd', 'abce', 'cdx']- reverse
- 디폴트 == False : 오름차순
list 슬라이싱, 연산
slicing 슬라이싱
arr[n:m] #arr[n]부터 arr[m-1]까지 슬라이싱- slicing해서 복사 한 list 리턴
- 가장 끝 index == -1
복사
- arr2 = arr1 -> arr2에 arr1의 레퍼런스(포인터) 복사. 같은 주소값 가지게 됨
- 값 복사
from copy import deepcopy
arr2 = arr1[:]
arr2 = deepcopy(arr1)
arr2 = copy(arr1)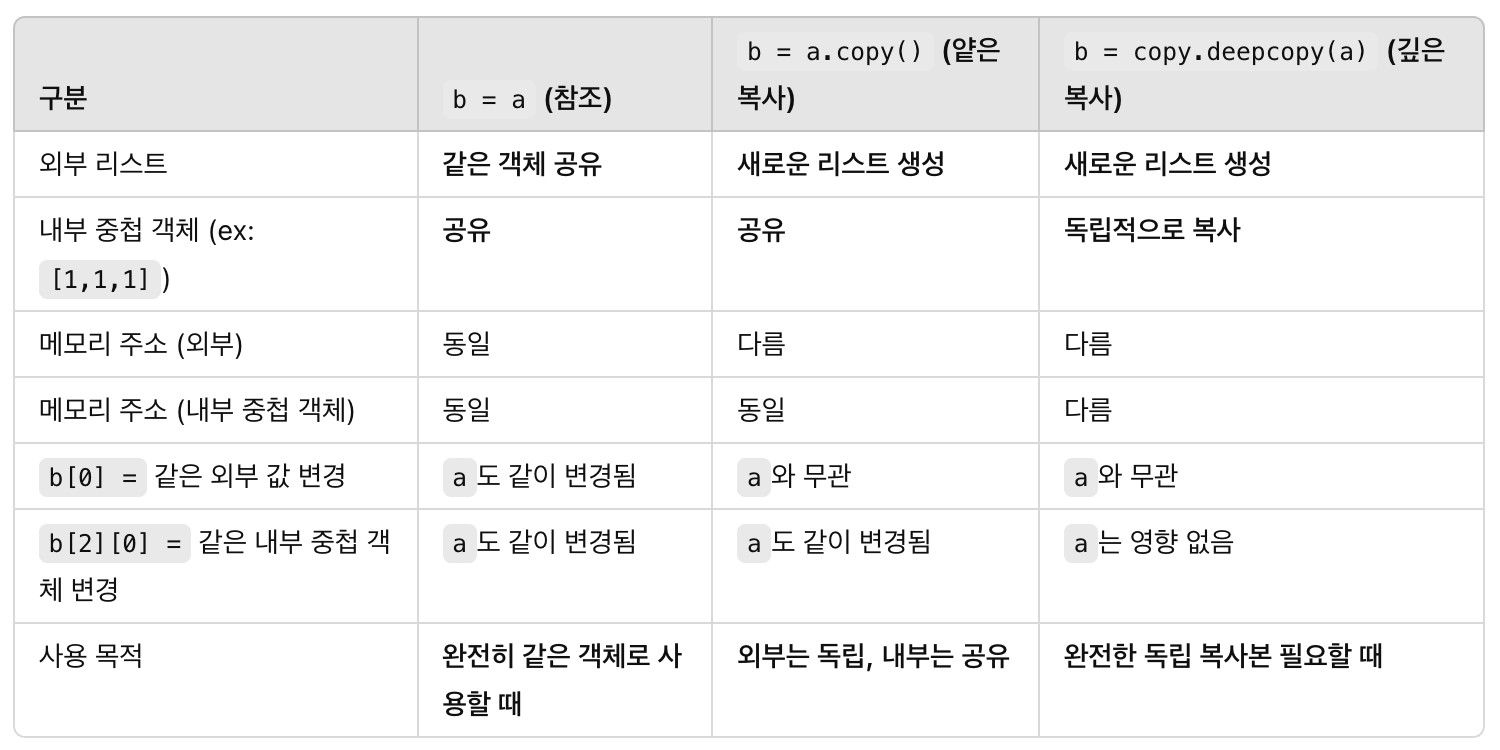
연산
- arr1 + arr2 : 두 list 이어붙인 list 리턴
- arr * 3 : list의 elements를 3번 반복시킨 list 리턴
- [ x ] * n 으로 elements가 반복된 1차원 list 만드는 용으로만 사용하자
- [ [ x ] ] * n 으로 2차원 배열 만들면 내부 list가 얕은 복사되어서 같은 주소값 가지는 하나의 객체를 복사해놓은 형태 된다.
: elements 변화 같이 공유
l = [0] * 5
print(l)
l[2] += 1
print(l)
# [0, 0, 0, 0, 0]
# [0, 0, 1, 0, 0]
l = [[]] * 5
print(l)
l[2].append(1)
print(l)
# [[], [], [], [], []]
# [[1], [1], [1], [1], [1]]one-line for문
-
list comprehension
https://velog.io/@sangyun/%EC%A0%9C%EC%96%B4%EB%AC%B8#list-comprehension -
list 내부에서 for문 one-line으로 사용 가능
: 정의한 element을 for 문에 따라 반복해서 list에 추가
strings = [['a','b','c'], ['c','a','r']]
l = [''.join(x) for x in strings]
# ['abc', 'car']빈 리스트 생성
- list()
: 빈 list 생성 (ex. 후 element 추가)
a = list()
for x in range(3):
a.append(x)- 빈 2차원 list 생성
arr = [[] for i in range(n+1)]다차원 list
arr1 = [[] for i in range(5)]
# [[], [], [], [], []]
arr2 = [0]*5
# [0, 0, 0, 0, 0]
arr3 = [0 for _ in range(5)]
# [0, 0, 0, 0, 0]
arr4 = [[0] for _ in range(5)]
# [[0], [0], [0], [0], [0]]
arr5 = [[0]*5 for _ in range(5)]
# [[0, 0, 0, 0, 0], [0, 0, 0, 0, 0], [0, 0, 0, 0, 0], [0, 0, 0, 0, 0], [0, 0, 0, 0, 0]]
arr6 = [[0 for _ in range(5)] for _ in range(5)]
# [[0, 0, 0, 0, 0], [0, 0, 0, 0, 0], [0, 0, 0, 0, 0], [0, 0, 0, 0, 0], [0, 0, 0, 0, 0]]- 2차원 (m x n) list 선언
m = 3
n = 5
arr1 = [[0 for j in range(m)] for i in range(n)]
arr2 = [[0] * m for i in range(n) ]
arr3 = [[0] * m for i in range(n)]- 2차원 list가 아닌 하나의 1차원 list 객체를 복사해놓은 형태
arr = [[0] * m] * n
print(id(arr[0]) == id(arr[1])) // True- 3차원 list 선언
dist = [[[0]*k for _ in range(m)] for _ in range(n)]list와 문자열
- 문자열 -> list : s.slpit()
s.split() #공백을 기준으로 elements를 나누어 list 타입으로 리턴
s.split('x') #x를 기준으로 elements를 나누어 list 타입으로 리턴
- list -> 문자열 : "".join(arr) _ list의 elements가 문자열일 때
"".join(a) #각 elements를 이어붙여 string 타입으로 리턴
"x".join(a) #각 elements 사이에 x를 추가하여 이어붙여 string 타입으로 리턴List 활용
출력
print(*list)
: elements들 사아 공백 두고 출력
in
if item in list:
print('리스트에 값이 있습니다.')
if item not in list:
print('리스트에 값이 없습니다.')
여러가지 자료구조

iterable, sequence
- iterable
- 멤버를 차례로 하나씩 반환할 수 있는 객체
- iterator를 반환하는 빌트인 함수 iter()를 위한 매직 메소드인iter()를 구현하고 있는 객체
- list, str, tuple, dict
- sequence
- 정수 index를 통해 각 멤버에 접근할 수 있는 iterable 객체
- dict type은 key index를 통해 각 멤버에 접근하므로 sequence가 아니다.
set
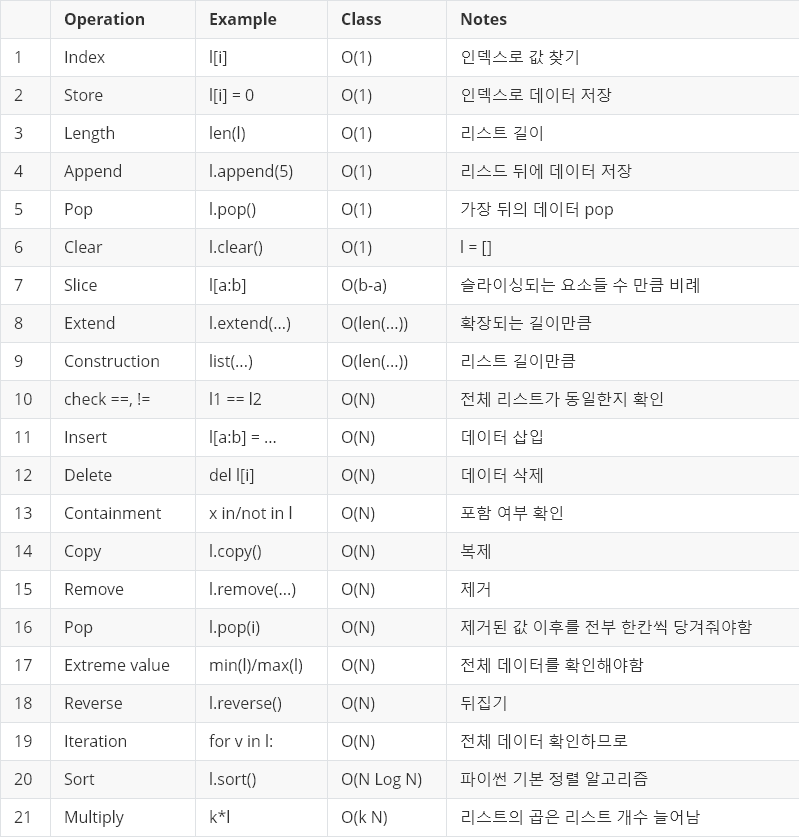
- set을 활용하면 list 보다 시간복잡도를 줄일 수 있는 경우들이 있다.
- list 시간복잡도
- set 시간복잡도
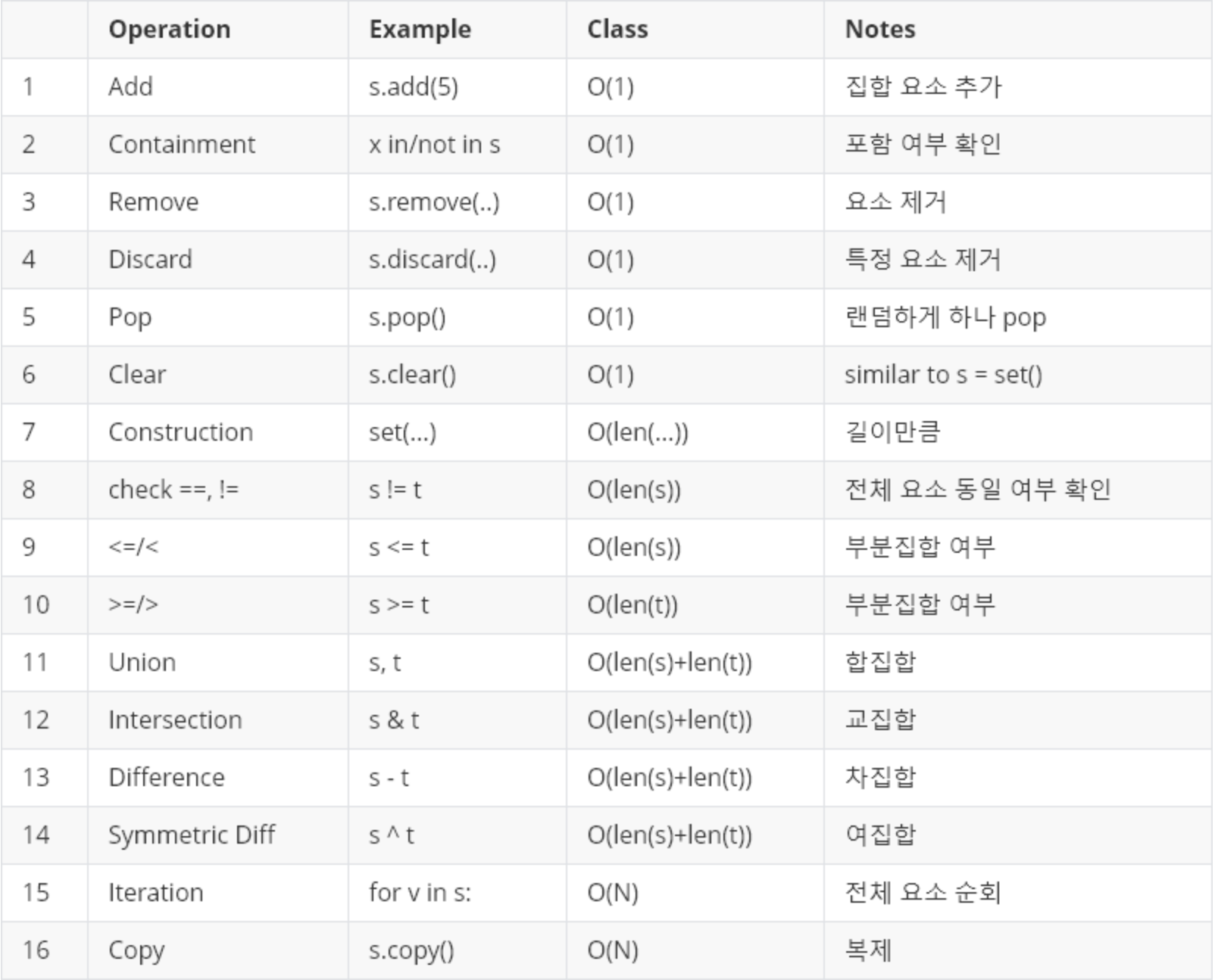 : set
: set
원소 추가, 삭제
- set.add(x)
:element 추가
s1.add(10)- set.remove(x)
- O(1)
- 특정 element 삭제
- 없는 element 삭제 시 error 발생
s1 = set([1, 2, 3])
s1.remove(2)
s1
# {1, 3}- set.discard(x)
- 없는 element 삭제해도 error 발생 안 함
포함관계
- in
- O(1)
- element가 set에 들어있는지 확인
s1 = set()
s2 = set([1,2,3])
if 2 in s2:
print("yes")
if 5 not in s2:
print("yes")
# yes
# yes- set1이 set2의 부분집합인지 확인
(자기 자신도 부분집합임)
set1 = {1, 3}
set2 = {1, 2, 3, 4}
print(set1 <= set2)
print(set1.issubset(set2))참고
https://docs.python.org/ko/3/tutorial/introduction.html#lists
https://duck-tube.tistory.com/1
https://velog.io/@choonghee-lee/%EB%B2%88%EC%97%ADstring-Text-Constants-and-Templates
https://teddylee777.github.io/python/python-tutorial-03
https://codechacha.com/ko/python-check-empty-list/
https://chancoding.tistory.com/43
https://ooyoung.tistory.com/59
https://velog.io/@optjyy/python-iterable-sequence
