
최적화
Generalization
- Training error가 0이라는 것이 학습의 종료를 의미하지는 않음
- 일반화 성능이 좋아야 함
Validation
- 학습 데이터와 검증 데이터를 어떻게 나누는게 좋을까?
cross validation
- 학습 데이터와 검증 데이터를 k개로 나누어서, k-1 개로 학습 후 남은 1개로 검증하는 방법
- 일반적으로 cross validation을 통해 최적의 하이퍼 파라미터셋을 찾고, 모든 데이터를 사용해 모델을 학습
- 엄밀하게, test data는 학습에 어떤식으로든 사용하면 안됨
bias and variance
- 편향과 분산
- 노이즈가 껴있다고 가정할 때, cost를 minimize하는 것은 bias, variance, noise 총 3가지로 나눌 수 있음
bootstrapping
- random sampling with replacement
- 학습 데이터가 고정되어 있을 때, 여러 sample로 여러 모델을 만드는 것
Bagging
- Boostrapping aggregating
- multiple models을 사용해 예측한 값을 종합
Boosting
- 여러개의 모델을 쌓아서 합치는 것
- Bagging과 다르게 sequential 하게 합쳐 정보를 취합
Gradient Descent Methods
- SGD - 한 개의 샘플로 계산 후 gradient update
- Mini batch GD - subset of data로 계산 후 gradient update
- Batch GD - 모든 데이터로 계산 후 gradient update
- 보통 Mini batch GD 사용
Batch Size Matters
- 배치 사이즈가 크면 sharp minimizers에 도달
- 배치 사이즈가 작으면 flat minimizers에 도달
- flat minimizers가 더 generalization 되어 있기에 일반적으로 배치 사이즈가 작은 것이 더 좋음
Optimization technique
Momentum
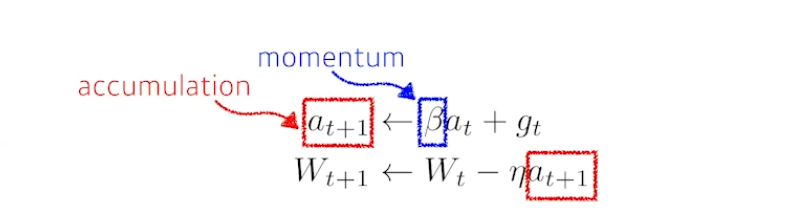
- 관성을 사용
Nesterov Accelerated Gradient
- local minimal로 더욱 빨리 converge하게 만듬
Adagrad
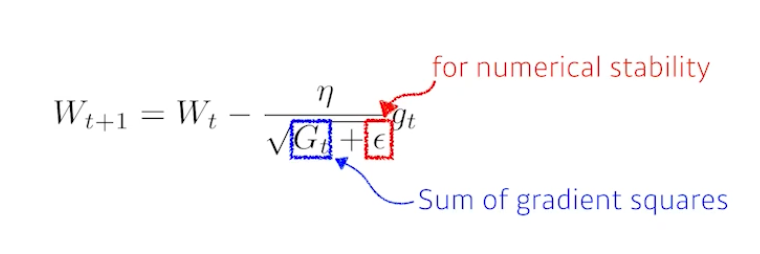
- nueral network의 많이 변한 parameter는 적게, 적게 변한 parmeter는 많이 변화시켜줌
- sum of gradient squares를 사용
- 학습이 너무 많아지면 gradient update가 멈추는 현상이 생김
Adadelta
- window size를 잡아 sum of gradient squares를 저장
- parameter 마다 gradient를 저장해야 하니, gpu가 터지는 현상
- Adadelta 내부에는 learning rate가 존재하지 않아 자주 사용하지 않음
Rmsprop
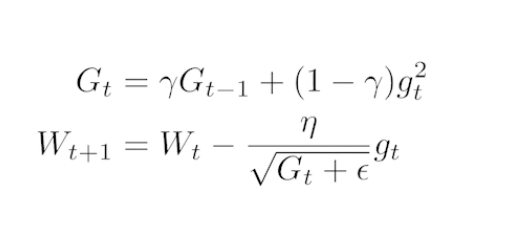
- Ema of gradient squares를 사용
Adam
- Adaptive Moment Estimation
- momentom + Ema of gradient squares
Regularization
- 규제를 거는 것
- 학습을 방해
- generalization 을 얻기 위함
Early Stopping
- val error가 떨어지기 전에 학습 멈춰 버리기
Parameter Norm Panalty
- 함수의 공간 속에서 평활화 하는 것
- weight decay, L1 norm, L2 norm 이라고 부름
Data Augmentation
- 데이터셋 늘려 버리기
Noise Robustness
- noise를 weight와 input에 집어 넣어 버리기
Label Smoothing
- decision boundary를 부드럽게
Mix up
- 이미지를 합성
CutMix
- 특정 영역을 분리해서 합침
Dropout
- Inference시에 random 하게 weight를 0으로 바꿈
Batch Normalization
- BN을 적용하고자 하는 layer의 statistics를 정규화 하는 것 N(0,1)
