
다중 GPU 환경에서 딥러닝을 학습할 때 효율적으로 하드웨어를 사용하는 방법
- 딥러닝은 엄청난 데이터와의 사용
- GPT-3는 10^11개의 parameter
개념
-
Single vs Multi
-
GPU vs Node(System)
-
Single Node Single GPU (한 개의 컴퓨터의 한 개 GPU)
-
Single Node Multi GPU (한 개의 컴퓨터의 여러 개 GPU)
-
Multi Node Multi GPU (여러 개의 컴퓨터의 여러 개 GPU)
-
우리는 주로 Single Node Multi GPU
Model Parallel
- 다중 GPU에 학습을 분산
- 모델을 나누기 / 데이터를 나누기
- 모델을 나누는 것은 고전적인 방법 (alexnet)
- 모델의 병목, 파이프라인의 어려움 등으로 인해 모델 병렬화는 고난이도 과제
class ModelParallelResNet50(ResNet):
def __init__(self,*args,**kwargs):
super(ModelParallelResNet50,self).__init__(
Bottleneck,[3,4,6,3],num_classes=num_classes,*args,**kwargs)
self.seq1 = nn.Sequential(self.conv1,self.bn1,self.relu...).to('cuda:0')
self.seq2 = nn.Sequential(self.layer3,self.layer4...).to('cuda:1')
self.fc.to('cuda:1')
def forward(self,x):
x = self.seq2(self.seq1(x).to('cuda:1'))
return self.fc(x.view(x.size(0),-1))Data Parallel
- 데이터를 나눠 GPU에 할당 후 결과의 평균을 취하는 방법
- minibatch 수식과 유사한데 한번에 여러 GPU에서 수행
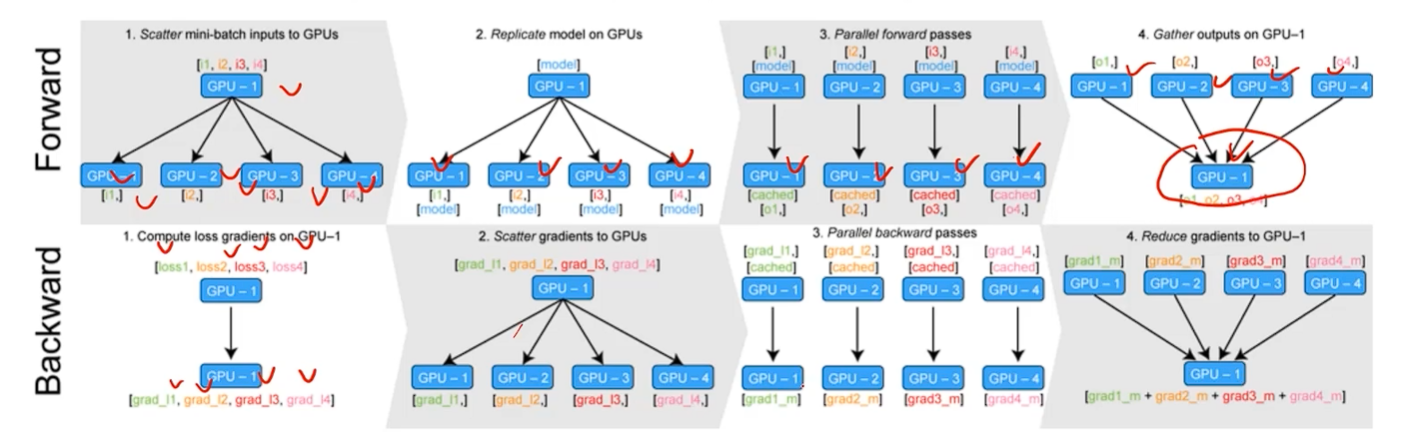
- 중간 중간에 하나의 GPU가 여러가지 일을 해야하므로 GPU가 폭발하는 일이 생김
- DataParallel - 단순히 데이터를 분배한 후 평균을 취함 (GPU 사용 불균형 문제 발생, Batch 사이즈 감소 등으로 해결할 필요가 있음)
- DistributedDataParallel - 각 CPU 마다 process 생성하여 개별 GPU에 할당 (기본적으로 dataparallel로 하나 개별적으로 연산의 평균을 냄)
DataParallel
# encapsule model
parallel_model = torch.nn.DataParallel(model)
predictions = parallel_model(inputs)
loss = loss_fn(predictions,labels)
loss.mean().backward()
optimizer.step()
predictions = parallel_model(inputs)DistributedDataParallel
train_sampler = torch.utils.data.distributed.DistributedSampler(train_data)
shuffle = False
pin_memory = True
trainloader = torch.utils.data.DataLoader(train_data,batch_size=20,shuffle = False, pin_memory = pin_memory,num_workers=3,
sampler=train_sampler) 
- 쪼꼼 귀찮을 가능성 있음
