
Model Serving
프로덕트 서빙의 핵심
Serving Basic
- Production 환경에서 모델을 사용할 수 있도록 배포
- 머신러닝 모델을 개발하고, 현실세계에서 사용할 수 있게 만드는 행위
- 서비스화라고 표현할 수 있음
- Input이 제공되면 모델이 예측 값을 반환
용어 정리

Web Server
- 요청을(request) 받으면, 요청한 내용을 보내주는(response) 프로그램
- 시간이 소요되면 기다려달라고 응답
- Client의 다양한 요청을 처리해주는 역할
- ML Server도 동일함 (전처리, 예측 등)
API
- 운영체제나 프로그래밍 언어가 제공하는 기능을 제어할 수 있게 만든 인터페이스
- 특정 서비스에서 해당 기능을 사용할 수 있도록 외부에 노출
- 라이브러리의 함수 또한 API에 해당
- 카카오, 구글, 네이버, AWS 등에서 API를 제공
- 라이브러리의 API Document
- 하나의 서버에서 여러 API를 가지고 있음
- FastAPI에서 잘 설명하겠음
Online Serving
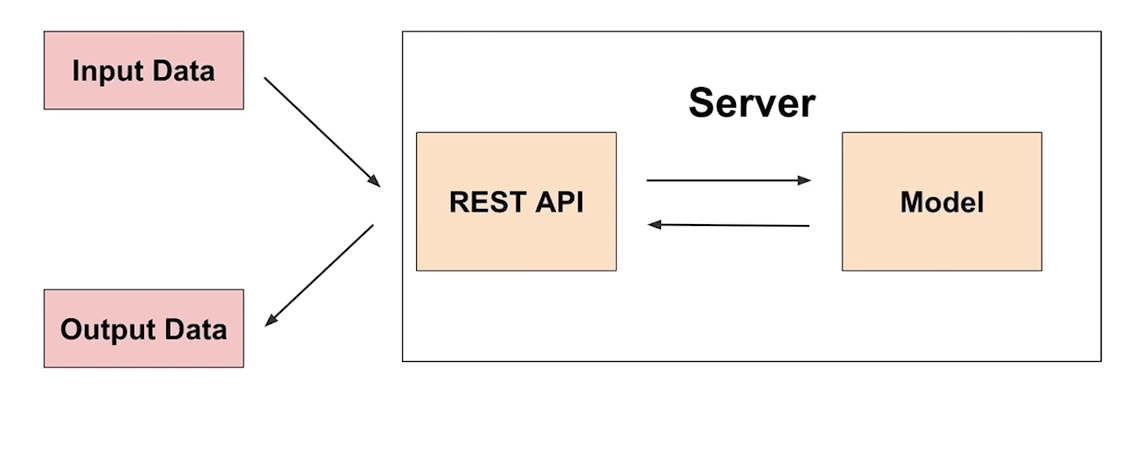
- 요청이 올때마다 실시간 예측
- 클라이언트에서 ML 모델 서버에 HTTP 요청을 하고, 머신러닝 모델 서버에서 예측한 후, 예측 값을 반환
- ML 서버에서 요청할 때, ML 모델 서버에서 데이터 전처리를 할 수 있음
- 다만 규모가 커지면 전처리 서버 모델, 서버 모두 분리할 수 있음
Basic
1) 직접 웹 서버 개발 - Flask, FastAPI
2) 클라우드 서비스 활용 - AWS의 SageMaker, GCP Vertex AI
3) Serving 라이브러리 활용 - Tensorflow Serving, Torch Serve, MLFlow, BentoML
직접 개발

- 나중에 할 것
클라우드 서비스 활용

- 클라우드에 익숙해야 잘 활용할 수 있음
- 직접 운영하는 것 보단 비용이 더 지불될 가능성 높음
라이브러리 활용
- FastAPI는 서버에 대한 이해가 필요함
- 추상화된 패턴을 잘 제공하는 라이브러리를 통해 배포
- 매우 간단

- 바로 서빙 라이브러리를 학습하면, 사용하기엔 편하지만 점진적으로 문제 해결력을 늘려보기 위해 + 라이브러리에 종속되지 말기 위해
- Low Level 이해도를 높이자
Online Serving 시 고려할 부분
- Serving 할 때 Python 버전, 패키지 버전 등 dependency가 굉장히 중요
- Online Serving에서 Latency를 최소화 해야 함
- 모델 경량화
- 결과 값에 대한 보정이 필요할 수 있음 (전처리 뿐만 아니라, 후처리가 필요할 수 있음)
Batch Serving
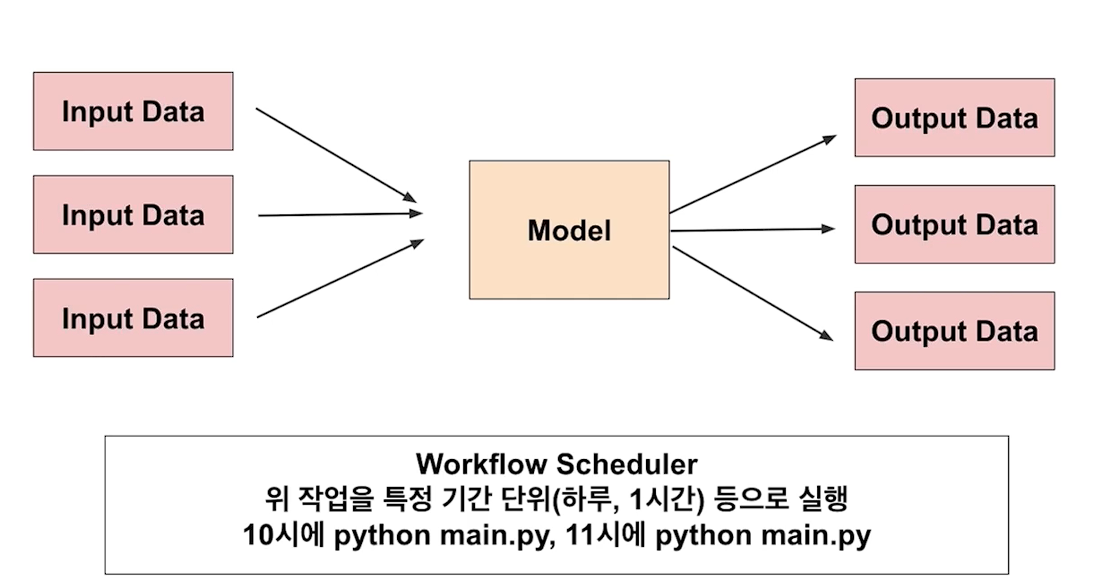
- 주기적으로 학습을 하거나 예측
- Batch 묶음을 한번에 예측
- Batch는 데이터 엔지니어링에서 자주 사용되는 용어
Basic
- Airflow, Cron Job 등으로 스케쥴링 작업
- 학습과 예측을 별도의 작업으로 설정 가능
- 실시간이 필요 없는 대부분의 방식에서 활용 가능
장점
- 주피터 노트북에서 작성한 코드를 함수화 한 후, 주기적으로 실행하는 간단한 구조
- Online Serving보다 구현이 수월, Latency가 문제되지 않음
단점
- 실시간으로 활용할 수 없음
- Cold Start 문제
Workflow Scheduler

Online Serving vs Batch Serving
Input 관점
- 데이터를 하나씩 요청 : Online
- 여러가지 데이터가 한꺼번에 처리되는 경우 : Batch
Output 관점
- API 형태로 바로 결과를 반환해야 함 : Online
- 서버와 통신이 필요 : Online
- 1시간에 1번 예측해도 괜찮음 : Batch
