
Evaluation Paradigms
Evaluation Strategies
사용자 스터디
- 사용자들을 모집해서 시스템과 상호작용하게 한 후 피드백 수집
- 활발한 참여에 바탕을 두고 있기에 오히려 Bias로 작용하는 경우가 존재
- 실험 설계에 많은 시간과 비용 소모
- 현실적으로 쉽지 않음
Online 평가
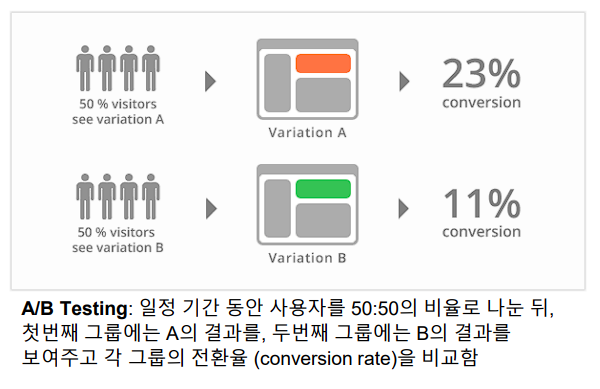
- 흔히 AB 테스트라고 불림
- Bias에 덜 민감
- 가장 정확한 방식이나, 개발 배포까지 시간이 걸리며, 많은 Traffic이 요구됨
Offline 평가
- 이미 수집된 데이터셋을 활용해 알고리즘의 성능을 평가
- traffic이 없어도 테스트가 가능해 널리 사용되는 평가
- 그러나 accuracy 관련 지표가 실제로 추천의 효용을 잘 반영하는가는 의문
- Serendipity, novelty와 같은 중요한 특성을 포착할 수 없음
- 시간에 흐름에 따라 사용자 선호도 및 아이템 특성 변화는 파악하지 못한다는 단점
Evaluation Criteria
Accuracy
- 정확히 얼마나 맞출 수 있는가
- RMSE, MAE, Precision, NDCG 등
- 때로 가격 등의 요소를 고려하여 profit을 최대화 하는 전략을 취하기도 함
- 그러나 실제 효용을 충분히 반영하는지는 불명확
Coverage
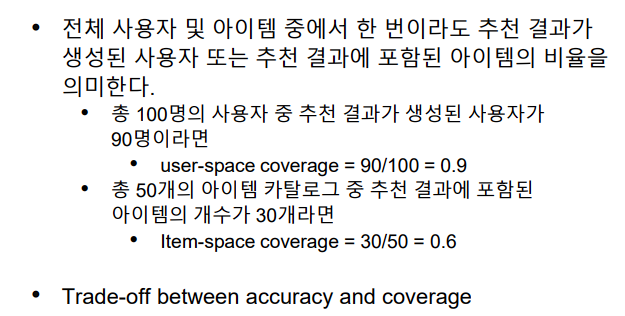
- 전체 사용자 및 아이템 중에서 추천 시스템이 놓치고 있는 부분이 없는지를 판단
Confidence & Trust
- Confidence는 추천 결과의 신뢰성
- 예측된 평균 값이 높더라도, 표준 편차가 적은 추천 시스템일수록 더 높은 Confidence를 가짐

- Trust는 추천 결과에 대해 사용자가 가지고 있는 믿음을 의미
Novelty
- 사용자가 알지 못하거나, 이전에 본적이 없는 추천을 제공할 가능성
- 사용자가 이전에는 알지 못했던 취향에 대한 새로운 발견을 제공

Serendipity

- Lucky Discovery
- 성공적인 추천으로부터 사용자가 느끼는 놀라움의 정도
Diversity
- 추천 결과가 얼마나 다양한 아이템으로 이루어져 있는지
- Diversity가 높으면 Novelty, Serendipity, Coverage가 증가
"니가 뭘 좋아하는지 몰라서 다양하게 준비해봤어"
Robustness & Stability
- 추천 시스템에 가해질 수 있는 공격에 대한 견고함과 안정성을 평가하는 기준
- Fake rating attack 등
Scalability

- 대용량 데이터를 얼마나 효과적, 효율적으로 처리할 수 있는지를 평가
평가를 위한 실험 설계
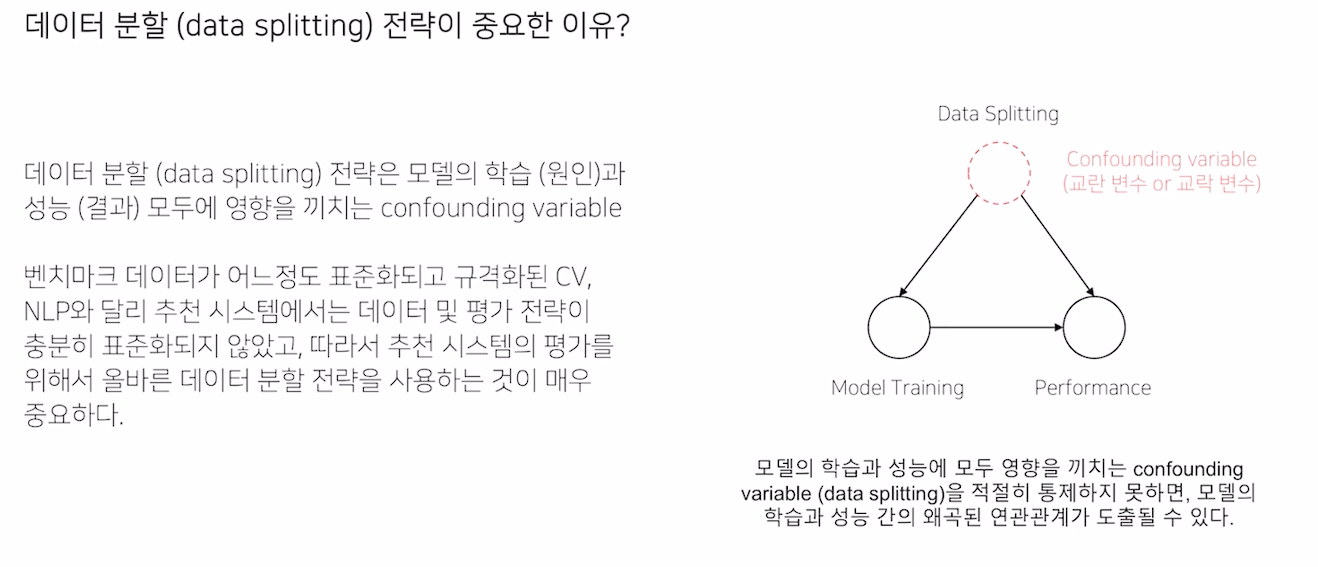
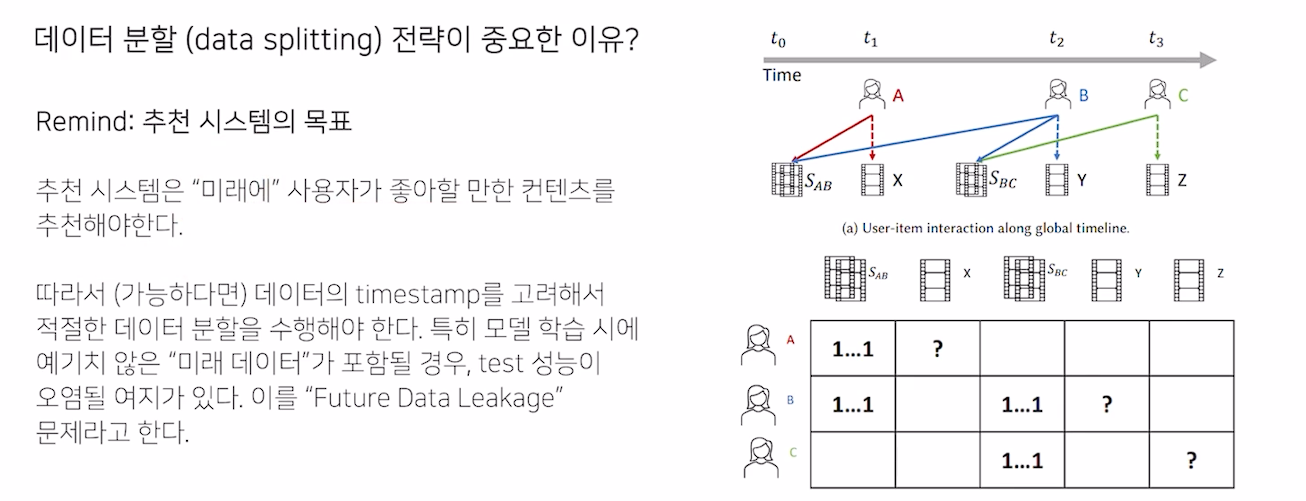
- 가능하다면 미래에 좋아할만한 컨텐츠를 추천해야 한다
Leave One Last

Temporal Split
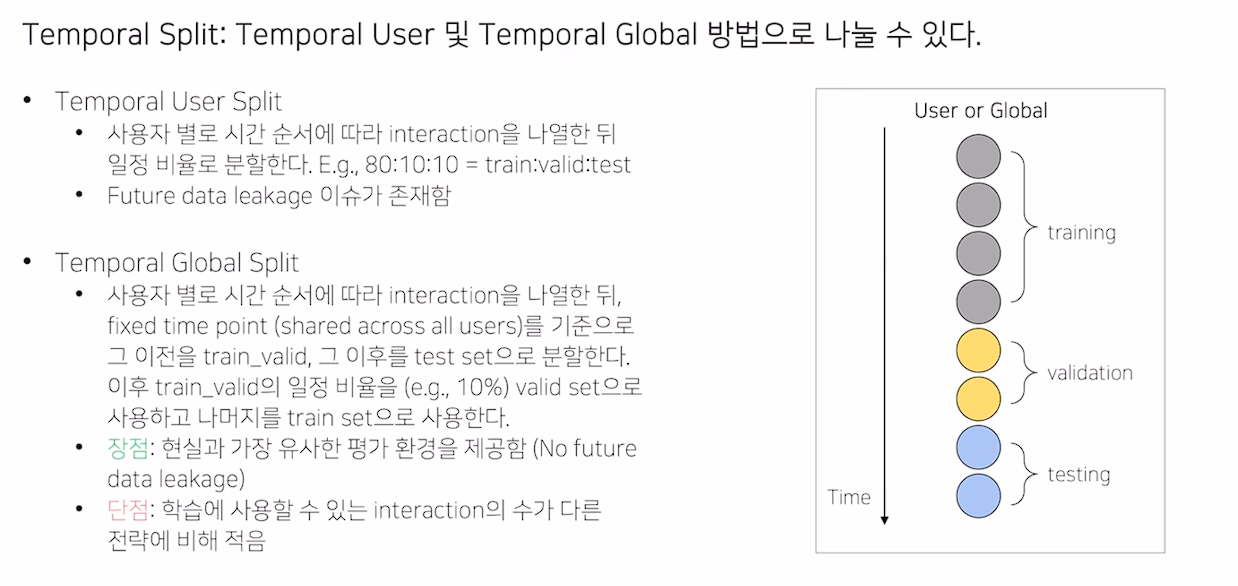
- Leave One Last와 유사하지만, 비율로 나뉘는 Temporal User Split
- Timeline을 기준으로 train, test를 분리하는 Temporal Global Split (data leakage에 자유로움)
Random Split
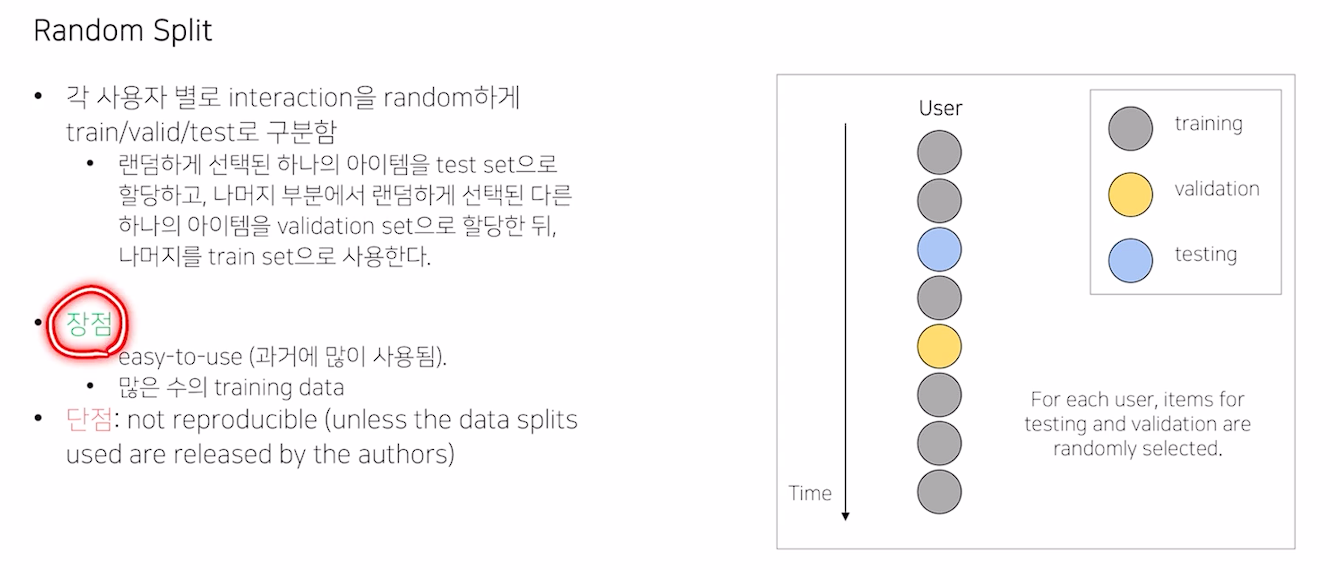
- 시간을 고려하지 않고 추출되기에, 재현이 힘듬
User Split

- 사용자를 기준으로 분할하니, Cold Start Problem에 대응할 수 있음 (User free model 등을 사용해야 함)
- data leakage 존재
Accuracy 기반 추천의 한계
feedback loop
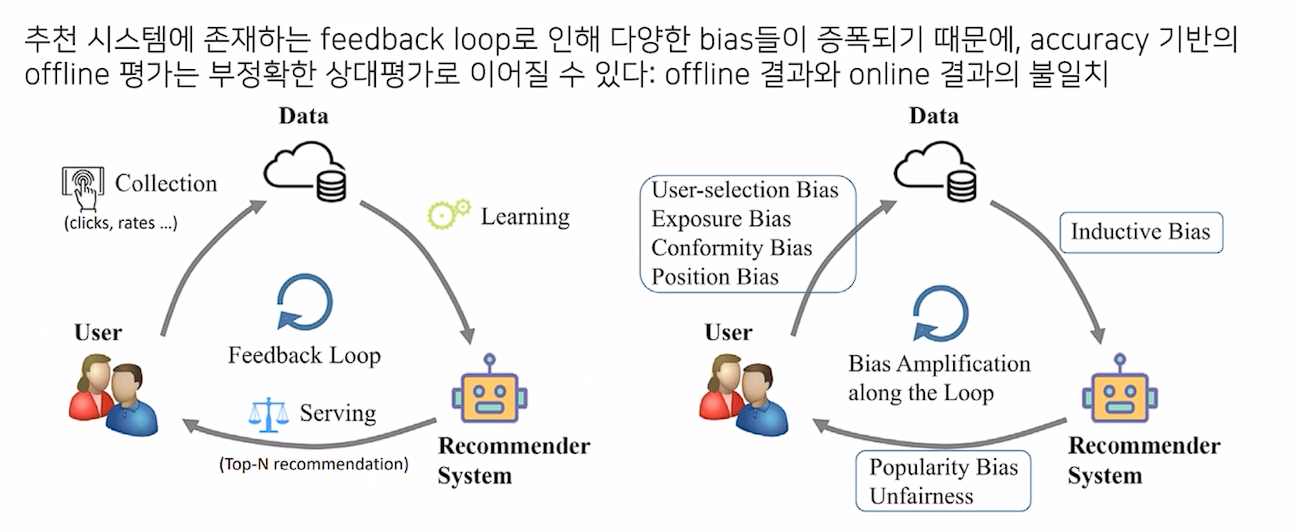
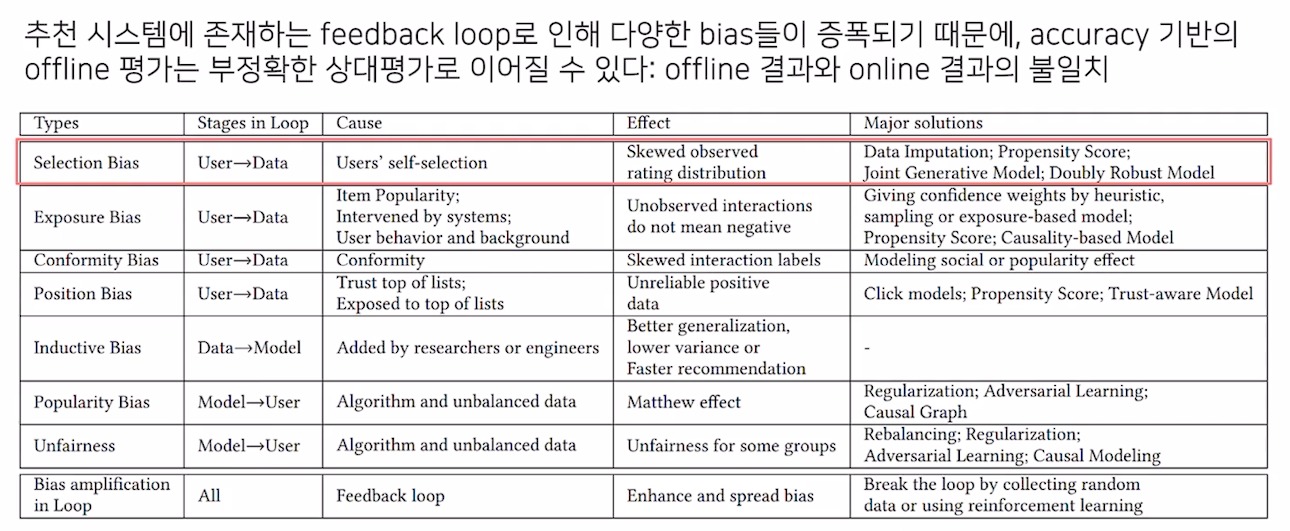
- 이렇게 다양한 bias가 존재
Data Bias
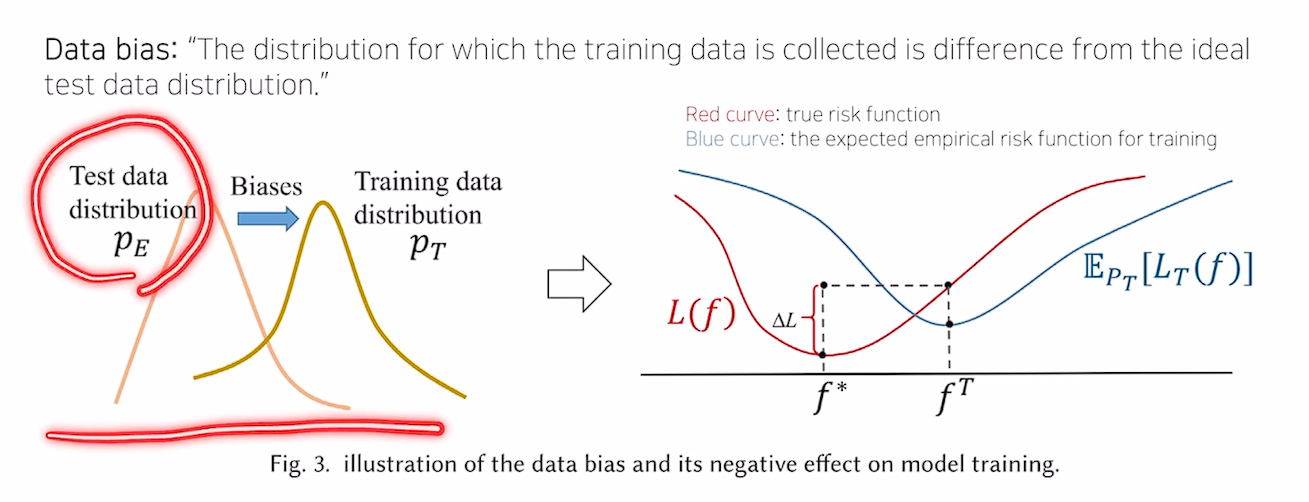
- train data와 test data의 분포가 다름
Selection Bias
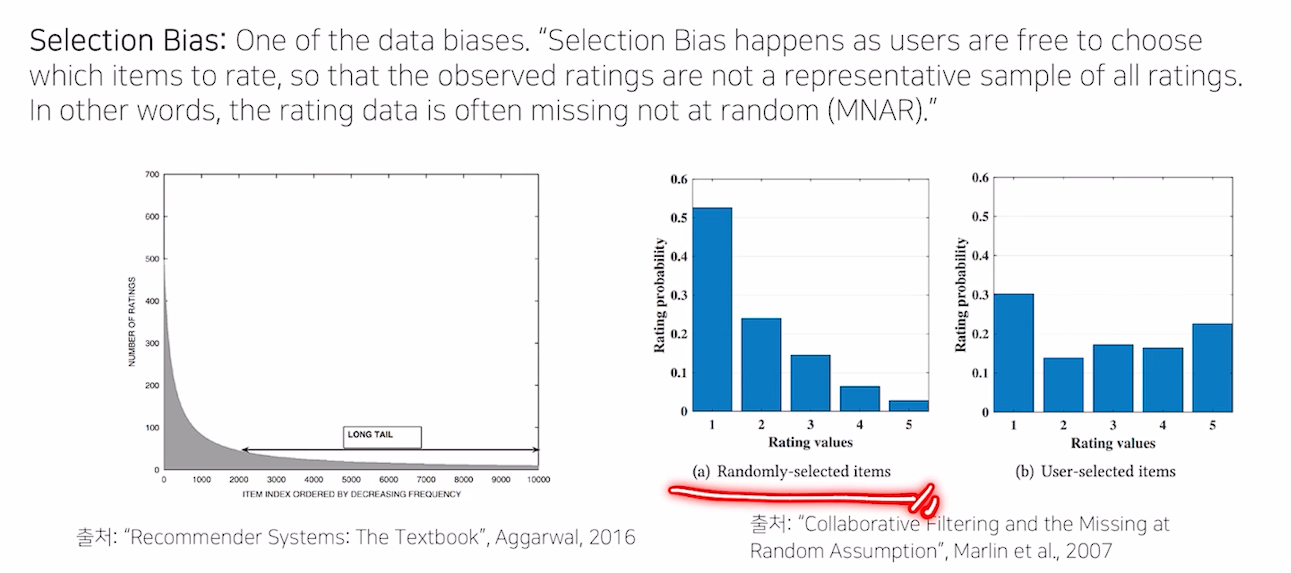
- 유저들이 실제로 택한 아이템과, random으로 추천해준 아이템의 rating 분포는 상이함
Solution for Unbiased Evaluation

- Implicit Feedback을 사용해라
- Selection Bias를 완화할 수 있음
- Temporal Global Split을 데이터 분할 전략으로 사용해라
- Data Leakage를 해소해 실제와 비슷한 환경에서 평가할 수 있음
- Online metric을 적절히 조합해라
