
DKT
DKT 이해
- Deep Knowledge Tracing
- 딥 러닝을 이용해 학습 상태 추정
- 지식 상태는 공부하며 계속 변화
- 시험지의 문제 풀이 정도를 가지고 지식 상태를 추정
- 문제를 풀어가며 지식 상태를 Update
- 데이터가 많아질 수록 예측은 정확해지고, 적을수록 오버피팅 현상은 쉽게 일어남
- 문제 추천, 학업도를 파악하는데 쓰일 수 있음
- Sequence가 주어지고 마지막 문제를 풀 수 있는지 없는지를 예측하는 Binary Classification
Metric
- Binary Classification
- 모델의 예측은 0 또는 1
- Accuracy와 AUROC 등이 존재
AUROC
Confusion Matrix
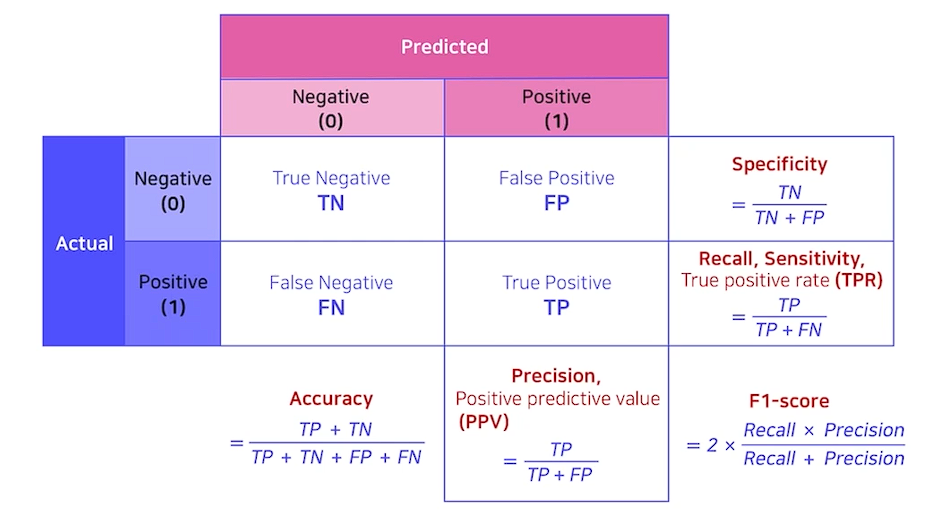
- Actual이 실제 Predicted가 모델
- 0과 1을 나누는건 Threshold
- AUC는 Area Under The ROC Curve
- 면적이 높을수록 모형 성능이 높아짐
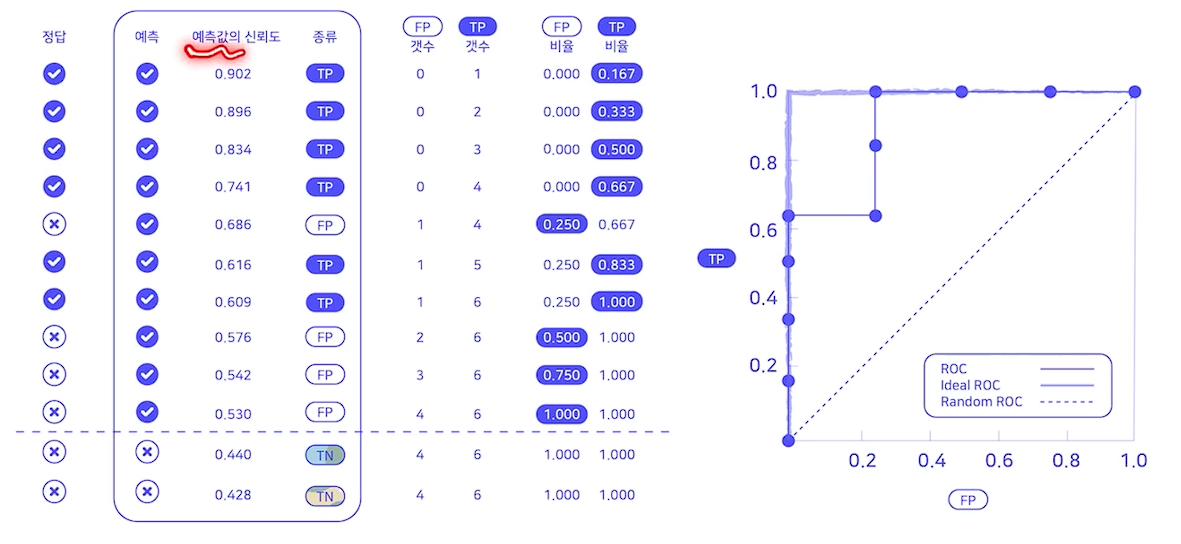
- AUROC는 분포 Metric

- 잘 보정된 확률 결과가 필요한 경우가 있는데, AUC로는 이 정보를 알 수 없음
- 분류 임계값 불변이 항상 이상적이진 않음 (FP를 최소화 하고 싶을수도..)
DKT History 및 Trend
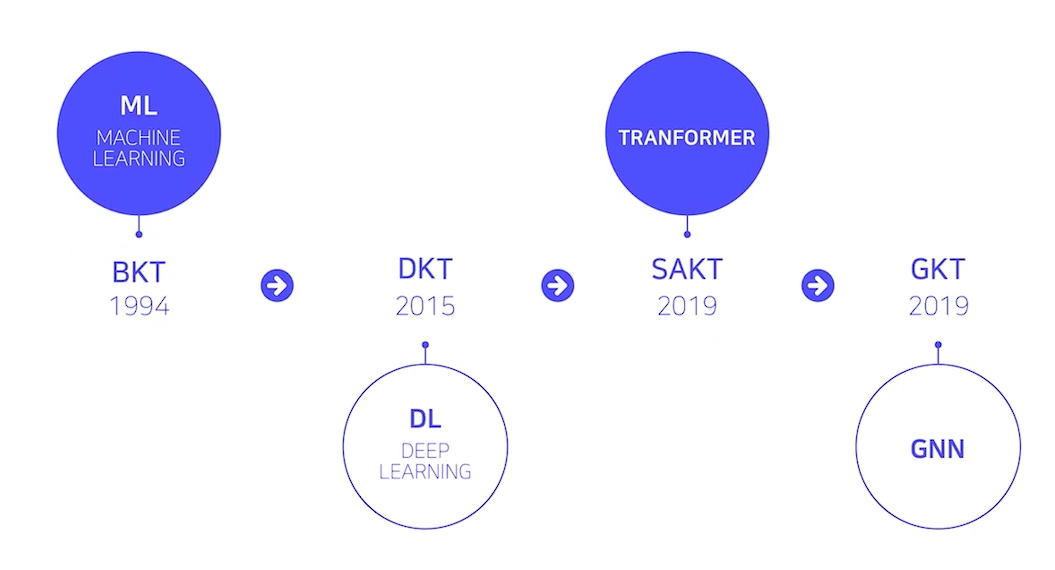
- DKT는 Sequence Data를 다루는 만큼 자연어 처리 분야의 발전에 많은 영향을 받음
Sequence Model
RNN
- 긴 문장에서 학습이 어려움
LSTM
- 장 단기 기억을 적절히 조정
- 기계 번역 등 언어모델이 아직은 힘듬
Seq2Seq
- Encoder, Decoder 모델
- Context Vector를 잘 학습시키는 모델
- 문장이 길어지면 문제가 발생
Attention
- Decoder가 Encoder의 Input까지 참조
- 여전히 Sequence의 한계
Transformer
- 위치 정보를 Positional Encoding으로 바꾸고, Attention만으로 모델을 구성
