
추천 시스템의 한계 및 연구 동향
추천 시스템 문제
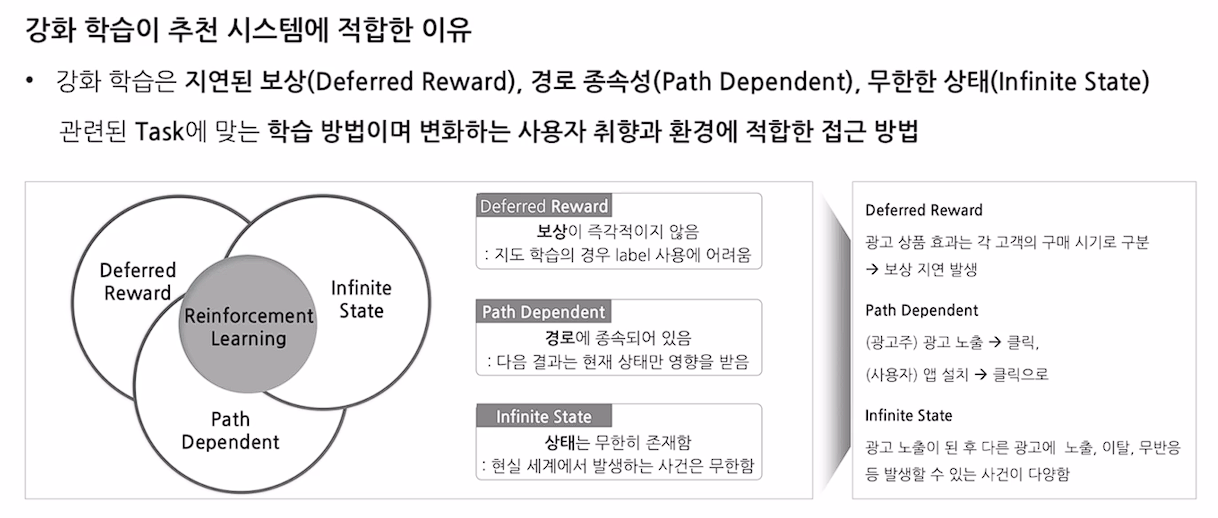
Cold Start
- 일반적인 추천 시스템은 사용자 특성 혹은 아이템 특성으로 구성 됨
- 어떤 사용자에 대한 특성 정보가 충분치 않아 적절한 상품을 추천하지 못함
- 어떤 아이템에 대한 특성 정보가 충분치 않아 추천 대상을 선정하지 못함
Dynamically Changing
- 사용자의 선호나 환경은 계속해서 변화
- 정확성과 다양성 사이에는 트레이드 오프가 존재
- 지금까지 추천 모델들은 문제점을 전부 해소하지는 못함
Real-Time Optimization
- 시간 흐름 문제를 해결하기 위해 실시간 최적화 알고리즘을 사용
- MAB는 강화학습의 대표적인 문제이며 Exploration과 Exploitation을 적절히 조절하여 보상을 극대화
MAB의 장점
- 대리 목표가 아닌 실제 목표를 통한 학습 가능
- 탐색과 활용을 고려한 장기적 보상 극대화
- 실시간으로 업데이트가 진행
- 이는 추천 시스템 설계에 적합한 알고리즘
강화학습
- 지속적인 Action을 통해 최적의 Decision Making 과정을 학습하는 방법
- 지연된 보상, 경로 종속성, 무한한 상태는 추천 시스템에서 용이한 특성
Value-aware Recommdentaion based on Reinforced Profit Maximization in E-commerce Systems
- RMSE 측면에서 예측 정확도 혹은 Top-K 추천 순위등 품질의 초점
- 온라인 광고와 미시 경제학의 기본 개념 활용
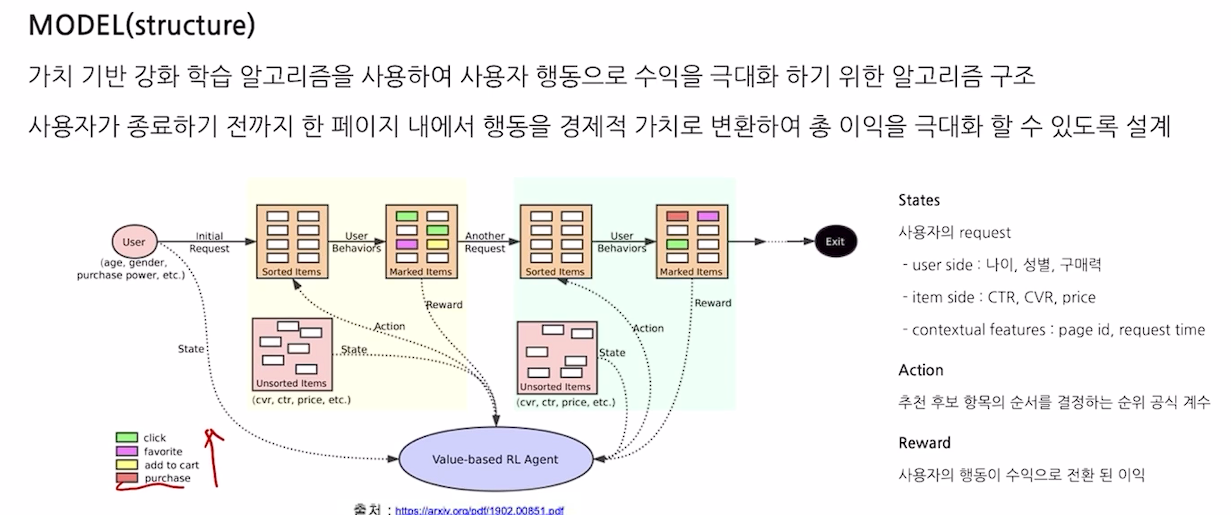
- 클릭, 카트 추가, 위시리스트 등록 등 사용자의 행동을 경제적 가치로 변환
Introduction
- 강화학습을 이용하여 개발한 추천 알고리즘은 이익을 수치화 및 최적화 할 수 있음
- 행동을 수익화 하여 가치 기반 알고리즘 개발
Model
- 가치 기반 강화학습 알고리즘을 사용
Deep Reinforcement Learning baed Recommendation with Explicit User-Item interactions Modeling
- 추천은 static process가 아님
- 유저의 선호는 변함
- DRR은 추천을 연속적인 의사결정과정으로 보고 Actor-Critic 기반의 강화학습 모델을 적용 (Policy 기반 강화학습)
