
잡플래닛 리뷰 데이터를 전처리하는 과정 정리
특수문자 제거

위 사진과 같이 줄 바꿈, 오타, 특수문자 등이 혼재되어 있음
def no_special(text):
text = text.replace('\n','')
text = re.sub('[^가-힣a-zA-Z]', ' ', text)
return text다음과 같은 함수를 통해 줄 바꿈 기호 제거 및 오타와 특수문자 제거

결과
맞춤법 교정
Raw 데이터이기에 띄어쓰기 오류와 오타 등이 여전히 존재하여 모델링 시 여러 문제를 일으킬 것이라 예상
py-hanspell 패키지를 이용하여 맞춤법 검사 및 교정
설치
pip install py-hanspell다음과 같은 코드로 쉽게 설치할 수 있으나, pip에서 오류가 발생해 다른 방법을 통해 설치
상기 모듈의 깃허브에서 folk한 후 clone or zip 파일을 받은 후 압축 해제
python setup.py install 해당 폴더로 이동 후 설치하여 모듈 설치
교정

| 내용 | 설명 |
|---|---|
| result | 문장 내에 오류 유무 T/F 값 return |
| original | 원 문장 return |
| checked | 검사 후 문장 return |
| errors | 검사 후 문장 return |
| words | 검사 후 문장 split 및 오류 종류 dict return |
| time | 총 요청 시간 |
오류 타입
| Int | Error |
|---|---|
| 0 | 문제 없음 |
| 1 | 맞춤법 의심 |
| 2 | 띄어쓰기 의심 |
| 3 | 표준어 의심 |
| 4 | 통계적 교정에 따른 단어 혹은 구절 |
결과

전
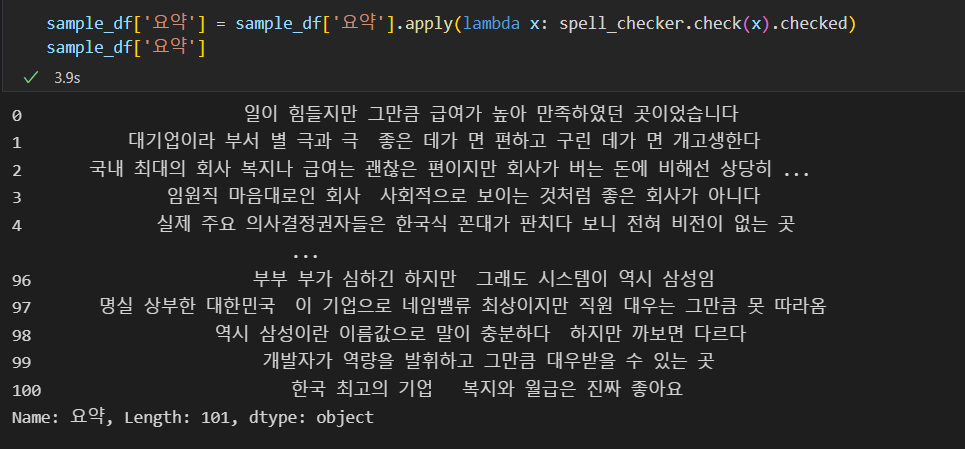
후
야무지게 교정 완료
불용어처리
이후 불용어처리를 위해 konlpy의 mecab을 활용하려 하였으나 Local에서 오류 발생하여 colab에서 진행
%%bash
apt-get update
apt-get install g++ openjdk-8-jdk python-dev python3-dev
pip3 install JPype1
pip3 install konlpy%env JAVA_HOME "/usr/lib/jvm/java-8-openjdk-amd64%%bash
bash <(curl -s https://raw.githubusercontent.com/konlpy/konlpy/master/scripts/mecab.sh)
pip3 install /tmp/mecab-python-0.996import konlpy
from konlpy.tag import Kkma, Komoran, Hannanum, Okt
from konlpy.utils import pprint
from konlpy.tag import Mecab차례대로 실행하여 환경 구성 완료
def stopword_preprocessing(text):
stop = stopwords
text = str(text)
tokens = mecab.morphs(text)
tokens = [token for token in tokens if token not in stop]
text = " ".join(tokens)
return text 다음 함수를 통해 불용어처리 완료
