Rethinking the Evaluation for Conversational Recommendation in the Era of Large Language Models (EMNLP 2023)
0
Paper Review
목록 보기
44/51

Introduction
- CRS는 Natural language conversation을 기반으로 high quality의 recommendation을 제공
- ChatGPT는 다양한 natural language task에서 잘 작동하는 것으로 흔히 알려짐
- 그러나 CRS에서 standard evaluation protocol을 사용할 때, SOTA CRS model을 dominate하지 못함 (직관에 반대)
- 우리는 CRS 데이터셋이 chit-chat way로 제작되었기에, 모호한 preference가 존재하고, 이 것이 GT item을 match하는데 어려움이 있음을 발견
- 또한 current evaluation은 fixed conversation에 기반 되어있기에, interactive한 결과를 이끌어 낼 수 없음 (이는 CRS의 자연적인 설계와 반대)
- 자연적인 CRS의 evaluation은 human에 의해 수행되는 것이 옳지만, 이는 time consuming 하며 사실상 불가능
- Surrogate하게 user simulator는 이를 수행할 수 있음
- 우리는 interactive Evaluation approach based on LLMs, iEvalLM을 구현
- 이는 LLM이 role-play를 수행하여 정교한 instruction을 통해 LLM이 user와 잘 상호작용할 수 있도록 함
- 우리의 evaluation approach는 CRS가 human-written conversation에서 해방되어, 보다 real-user에 가까운 방식으로 상호작용 할 수 있도록 함
- 또한 이러한 evaluation 방식에서는 GPT가 더 월등함과 동시에 설명력을 보여줌을 실험을 통해 반증함
Background and Experimental Setup
Task Description
- CRS는 multi-turn interaction 기반으로 item을 recommendation하며, 이는 QA와 Chit-chat base로 나뉨
- 우리는 후자에 초점
- Conversation은 user가 item에 대해 만족하거나, terminate할 때 까지 진행됨
Experimental Setup
- REDIAL과 OPENDIALKG dataset으로 실험을 진행
- REDIAL은 only movie, OPENDIALKG는 movie, books, sport, music을 모두 포함
Baselines
- KBRD
- DBpeida를 통해 semantic understanding을 강화
- KGSF
- 두 knowledge graph와 mutual information maximization을 통해 semantic을 aling해 성능 향상
- CRFR
- flexible fragment reasoning을 통해 성능 향상
- BARCOR
- BART를 통해 unified 된 CRS를 구현
- 하나의 모델로 conversation과 recommendation을 모두 진행
- MESE
- recommendation을 candidate selection과 ranking의 두 stage로 formulate하고 meta-information을 사용해 item을 encoding
- UniCRS
- prompt를 KG로 desing하여 DialoGPT가 두 task를 unify하게 접근하도록 함
- text-embedding-ada-002
- input NL을 embedding으로 변환하여 recommendation으로 사용하도록 함
- unsupervised method
Evaluation Metrics
- Recall@K
Model details
- temperature를 0으로 설정한 GPT3.5-turbo 사용
ChatGPT for Conversational Recommendation
Methodology
- GPT는 dialogue에 optimize 되었기에, ability를 stimulate하기 위해 두 접근법 사용
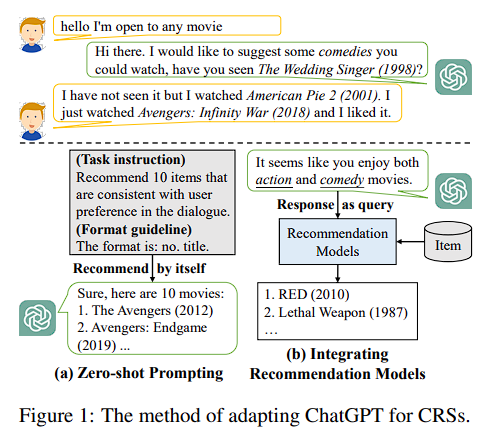
Zero-shot Prompting
- Prompt는 두 가지 측면으로 구성됨
- task instruction
- format guideline
Intergrating Recommendation Models
- GPT가 out-of-distribution item을 제공하는 것을 방지하기 위해 CRS model과 병합 (MESE, text-embedding-ada-002)
Evaluation Results
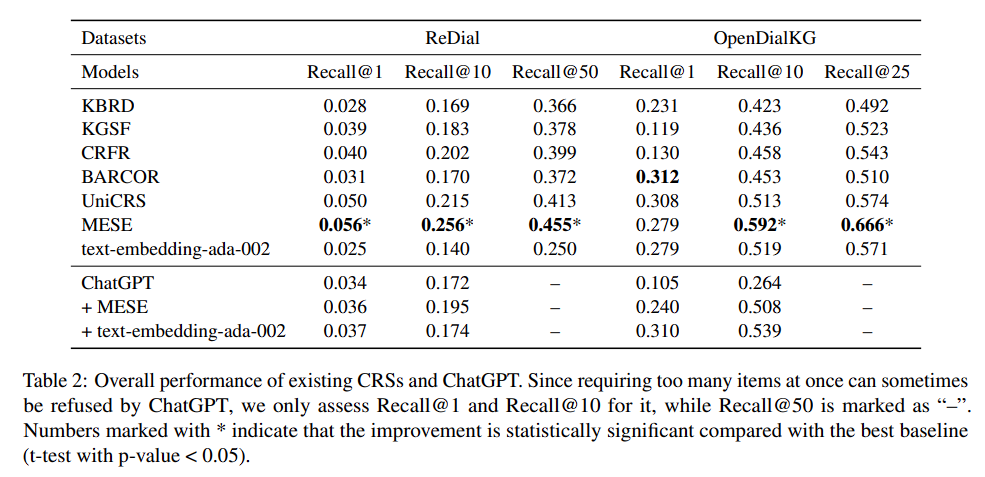
Acuuracy
- ChatGPT가 예상보다 잘 작동하지 않음
- CRS 모델과 병합하였을 경우, 성능이 오르지만 SOTA 모델에는 부족
Explainability

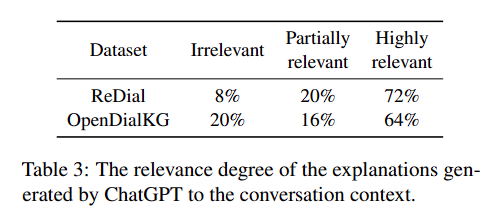
- GPT로 하여금 recommendation의 explain을 생성하도록 함
- annotator를 통해 실패한 sample의 추천 및 설명의 연관성을 파악하도록 함
- table과 같이 0.77로 추천과 설명이 유의미함
- Explanation example을 보면 GPT가 user의 preference를 이해하고, reasonable한 설명을 생성하는 것을 알 수 있음
- 그러나 성능이 낮다는 것은 이에 대한 반박임
- 이 실험 결과가 failure의 이유를 investigate 하게 한 motivation
Why does ChatGPT Fail?
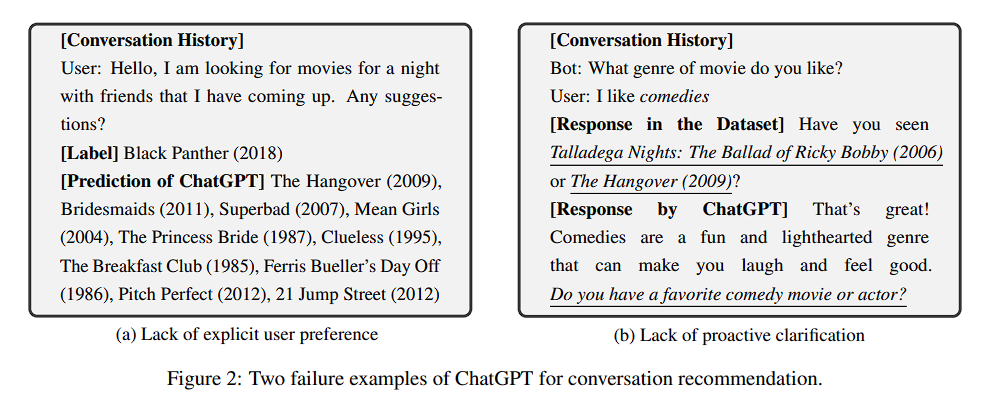
Lack of Explicit User Preference
- example은 매우 짧은 turn으로 구성
- 또한 conversation은 chit-chat으로 구성되어 있어, 모호함
- annotator를 통해 failure case의 모호성을 계산한 결과, Cohen's Kappa 계수가 신뢰도 있음
- 이는 ChatGPT가 dialogue context를 기반으로 추천하는 것에 fine-tuning 되어 있지 않았기에 다른 CRS 모델에 비해 더 serious할 수 있음
Lack of Proactive Clarification
- Major limitation은 evaluation이 엄격하게 conversation flow를 따라가야만 한다는 것
- Real world에서는 CRS가 proactive clarification 제안할 수 있는데, 기존 evaluation에서는 알 수 없음
* 실패 case를 보면 GPT는 user preference를 더 원하였으나, conversation이 terminate 된 경우가 다수
- Real world에서는 CRS가 proactive clarification 제안할 수 있는데, 기존 evaluation에서는 알 수 없음
- annotator를 통해 conversation의 clarification을 측정한 결과, 36% 만이 clarification임을 발견 (kappa 계수로 정당성 입증)
- 결론적으로 현존하는 evaluation protocol은 두 가지 issue가 존재
- lack of explicit user preference
- lack of proactive clarification
A New Evaluation Approach for CRSs
- 새로운 evaluation approach인 iEvalLM을 소개
Overview
- 접근의 key idea는 conduct close-to-user simulation based on excellent role-play capacities of LLMs
- GT item과 user preference를 주고 LLM-based simulated user에게 persona를 instruction을 통해 주입
- accuracy 뿐만 아니라, explainability를 동시에 평가
Interaction Forms
- Comprehensive evaluation을 통해 두 가지 타입의 interaction을 정의
- attributed-based QA
- free-form chit-chat
- 전자는 최초 conversation에서 restricted된 k개의 attribute에 대해 질문 후, turn이 증가할 때 마다 k+1 option에 대해 대답
- 후자는 어떠한 restriction과 interaction 제약이 없음
User Simulation
- User simulator는 3 가지 대답을 할 수 있음
- Talking about preference: System이 clarification, elicination을 원한다면 simulator는 target item에 대한 정보를 말할 수 있음
- Providing feedback: System이 item list를 추천하면, simulator는 item을 check하여 target item이 있으면 pos feedback, 없으면 neg feedback을 생성
- Completing the conversation: target item이 추천되거나, 특정 round 이상의 conversation이 진행될 경우 terminate
- Talking about preference: System이 clarification, elicination을 원한다면 simulator는 target item에 대한 정보를 말할 수 있음
- Text-davinci-003을 simulator로 사용
- instruction에 GT item과 manual template, 대화 이력을 추가함으로써 평가
Performance Measurement
- Subjective, Objective metric을 사용
- 각각 Recall, Persuasivness를 사용
- Persuasivness는 마지막 recommendation의 explanation을 통해 납득 가능한 수준을 0~2 사이로 평가
- LLM을 scorer로 사용
- Persuasivness는 마지막 recommendation의 explanation을 통해 납득 가능한 수준을 0~2 사이로 평가
- 각각 Recall, Persuasivness를 사용
Evaluation Results
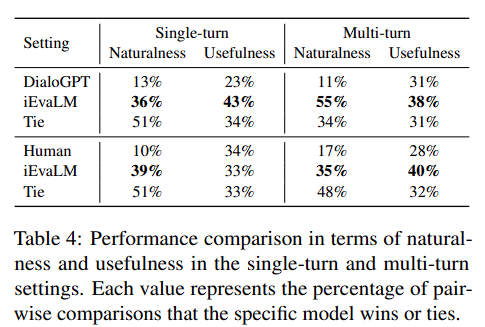
The Quality of User simulator
- Direct하게 user simulator의 quality를 측정하는 것은 어려움
- Existing Dataset의 첫 번째 conversation을 사용해 GT conversation과 user simulator를 비교
- 타 논문의 metric인 naturalness와 usefulness를 사용
- naturalness는 human generated conversation과 얼마나 유사한지이며, usefulness는 utterance가 user preference와 얼마나 consistent한 지를 의미
- 우리는 우리의 user simulator를 fine-tuning된 DialoGPT와 비교
- annotator로 하여금 두 model 중 어떤 대답이 better, otherwise, tie 인지를 비교
- Table을 통해 우리의 것이 더 효과적임을 알 수 있음
The Performance of CRS
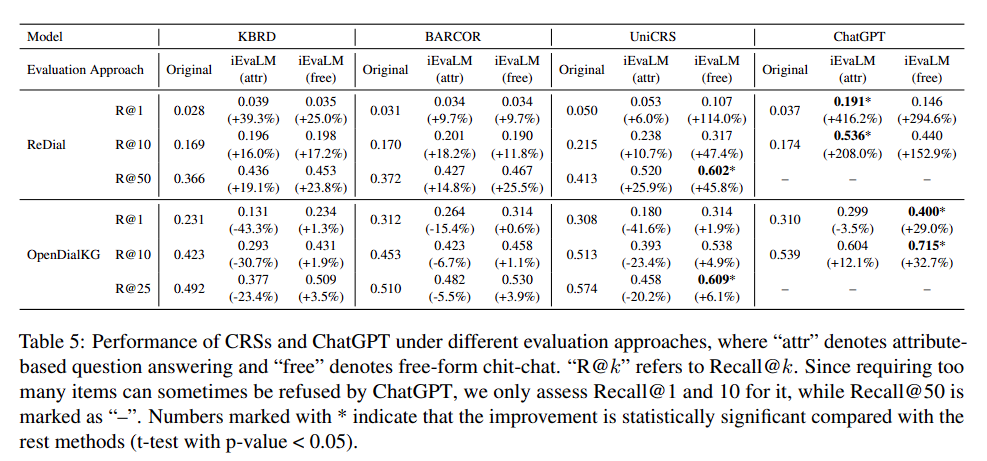

Main Results
- ChatGPT가 great potential을 보임
- 기존 CRS는 attribute-based QA의 OPENDIALKG에서 성능 하락을 보임
- 이는 기존 CRS가 NL conversation 기반으로 학습 되었기 때문에, inconsistent한 환경에서 잘 작동하지 않은 것으로 보이며 기존 evaluation protocol에서는 확인할 수 없는 부분
The Reliability of Evaluation
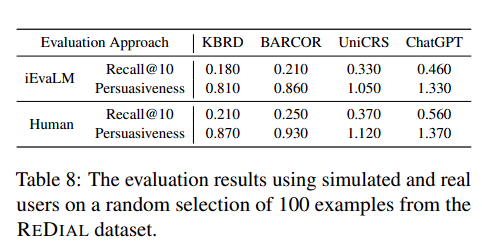
- Persuasivness 및 real user와의 비교를 통해 우리의 evaluator가 reliable함을 판명
- 먼저 five user에게 동일한 persona를 주입시킨 뒤, Conversation을 진행하도록 함
- 결과가 user simulator와 유사
- 우리의 persuasivness scorer가 human의 alternative가 될 수 있음을 table을 통해 증명
