MatCha: Enhancing Visual Language Pretraining with Math Reasoning and Chart Derendering (ACL 2023)
Paper Review
목록 보기
24/51

MatCha = Math reasoning + Chart derendering pretraining
Introduction
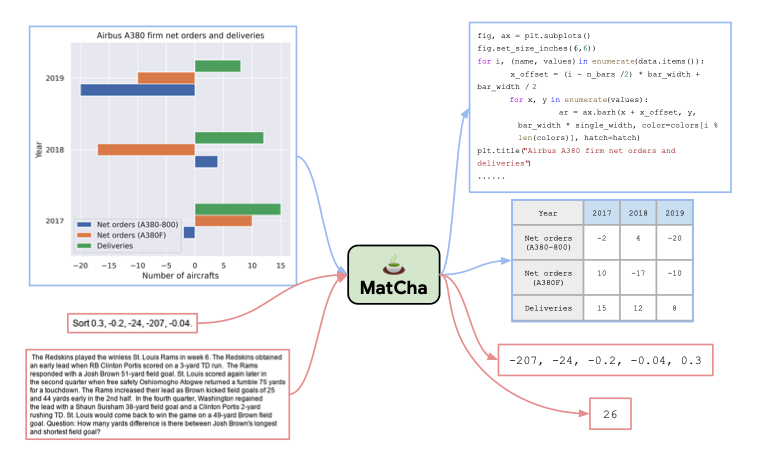
- Visual language는 강하게 textual, visual element를 결합하는 것
- text를 제외한 line, shape, scale .. 등 때문에 visual language는 복잡
- ChartQA, PlotQA, Pix2Struct 등 visually-situated language 모델이 제안 됨
- 우리는 Pix2Struct를 base model로 사용하고 chart derendering과 math reasoning을 통해 pretraining 할 것
- Visual language understanding은 2가지 키워드
- layout understanding: discover underlying patterns of image and organize elements
- mathematical reasoning: operate elements and derive meaningful information
- 이러한 관점에서 우리는 두 가지 pretraining task를 제시
- Math reasoning과 Chart derendering
- Chart derendering은 element를 적절한 table, code로 재구성하는 것
- Math reasoning은 image를 통해 답변을 생성하는 것
- SOTA at Chart-to-Text
- 대부분 domain에서 Pix2Struct를 능가
- Summary
- visual language learning에 유용한 pretraining task 제안
- 여러 Task에서의 SOTA 입증
- Chart domain 뿐만 아니라, textbook VQA, widget captioning 등에서도 SOTA 달성
- 심층 분석을 통해 어떤 pretraining component가 downstream performance에 효과를 주는 지 밝힘
Related Work
Vision-language research and a lack of attention on visual language
- 기존 연구는 대부분 natural image기반
- Chart, Plot 대비 매우 simple
- real-world visual language dataset에서 잘 작동하지 않음
OCR-based & end-to-end methods for visually-situated language
- LayoutLM, ChartBERT 등 OCR에 relies 할 경우, cost가 높음
- 또한 visual language system 중 text와 무관한 element에는 잘 작동하지 않음
- 우리의 최근 연구인 DEPLOT은 Chart-to-Text translation module에 LLM을 결합함
- Donut, Dessurt, Pix2Struct는 end-to-end pretrained model
- 우리의 베이스 또한 Pix2Struct
Learning to reason by designing novel pretrained tasks
- MatCha는 better training objective를 찾는 모델 (naive language modeling으로는 성능 향상을 기대하기 힘듬)
- 우리는 image-to-text model에게 chart를 data, code로 decoding하는 것과 math reasoning을 가르치려 함
Method
- key is layout understanding and math operation capabilities
- We inject - chart derendering, math reasoning
Chart Derendering
- Plot과 Chart는 data인 table과 layout인 code로 구성
- Chart를 이해하려면 image의 visual pattern을 밝히고, parse한 뒤, key information으로 group 및 extract해야 함
- Chart, table, code를 동시에 얻는 것은 challenging
- 우리는 독립적으로 (chart, code), (chart, table) 데이터를 수집
- (chart, code)에 경우 Github의 적절한 주피터 노트북 코드 및 figure를 크롤링
- (chart, table)의 경우 manual하게 생성
- Wikipedia table을 matplotlib, seaborn을 사용해 plotting
- PlotQA의 chart-table pair를 corpus 증대를 위해 사용
- 이외에도 크롤링 가능한 chart-table pair를 사용
- Wikipedia table을 matplotlib, seaborn을 사용해 plotting
Math Reasoning
- Visual Language는 layout, mathematical operation 둘 다 가능해야 함
- Chart Derendering은 layout에 특화
- textual math dataset을 사용해 mathematical operation을 해결하고자 함
- Dataset으로는 MATH와 DROP을 사용
- MATH는 type 별로 two million가지의 training example
- DROP의 문제를 해결하려면 paragraph를 읽고, relevant number을 추출한 뒤, numerical computation을 수행할 수 있어야 함
- 우리는 두 데이터셋이 효과적임을 찾아냄
- MATH 데이터셋은 많은 양의 corpus로 math operation을 identify하는데 도움을 줌
- DROP의 reading-comprehension format은 typical QA format과 유사
- 최 상단 figure의 red box가 두 format의 예시 (Image를 Input으로 answer를 생성)
- catastrophic forgetting을 방지하기 위해 screenshot parsing을 동일하게 진행 (mixture weight)
Experiment
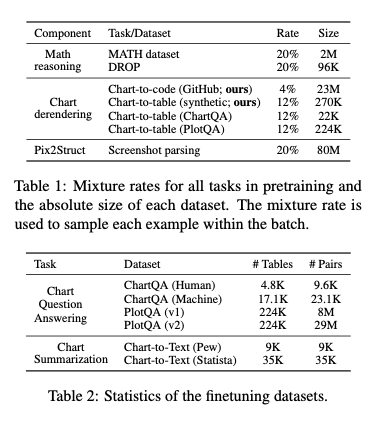
- 40% chart derendering, 40% math reasoning, 20% screenshot parsing
- Chart-to-code가 매우 noisy하기에 rate를 적게 줌
- 이외에도 여러 결과들이 존재 (논문 참조)
Analyses and Discussions
Ablation Study
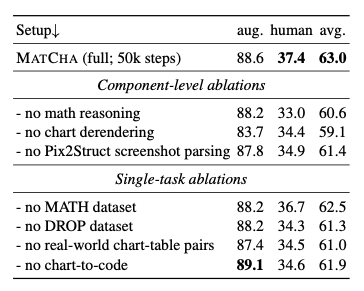
- removing major component는 performance drop을 일으킴
- 가장 drop이 큰 component는 chart derendering
- learning to reasoning dataset은 DROP이 MATH보다 중요한 것으로 보임
- DROP이 downstream task QA와 더 유사한 format이라 이러한 결과가 나온것으로 예상
Conclusion
- MatCha for visual language tasks
- SOTA on 5 out of 6 setups
- Improve Pix2Struct
Limitations
- Error 분석 결과 complex reasoning이 더 필요함
- weight space에서 math calculation을 하는 것이 most promising path인지 아직 의논의 여지가 있음
- image-text pretraining with rich semantics의 부족이 여전히 존재
- Cost가 충분하다면 더 많은 ablation study가 가능
