Large Language Models as Zero-Shot Conversational
Recommenders (CIKM 2023)

INTRODUCTION
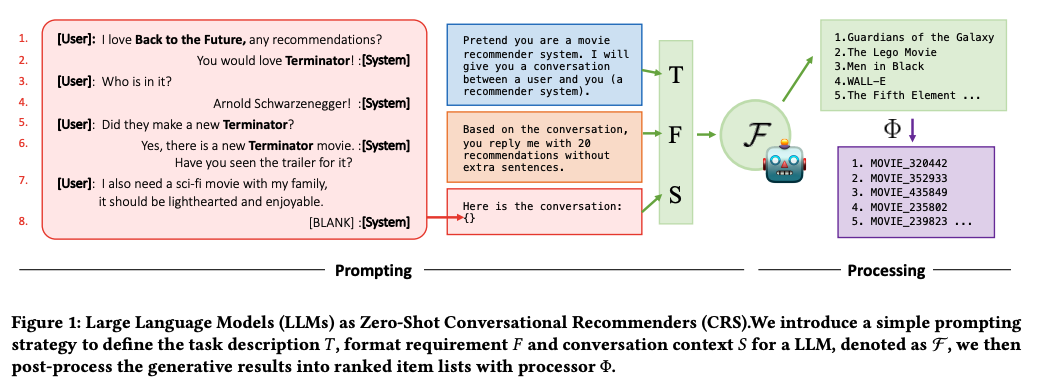
- 이전 추천 시스템과 달리 Conversational Recommender System (CRS)는 유저의 기록 뿐만 아니라 NL input을 고려할 수 있음
- 다양한 목적의 선호를 고려할 수 있고, 추천의 correction이 가능함
- 기존 CRS 모델은 text generator와 recommender의 two component
- 현재 까지의 연구는, text보다 user-item interaction에만 집중
- 우리는 LLM을 zero-shot conversational recommender로 사용
- 우리는 추가적으로 3 가지 key aspect를 제안 - data, evaluation, analysis
Data
- Reddit의 실제 대화를 바탕으로 Reddit-Movie 제안
- 기존 ReDIAL의 50배 이며, 현존 가장 큰 CRS dataset
Evaluation
- 단순히 이전에 상호작용한 item을 추천하면 대부분의 CRS를 압도하는 repetition bias가 생김
- 이 반복을 제거하여, fine-tuning 없이도 기존 모델을 능가함을 보임
Analysis
- 왜 LLM이 zero-shot CRS model의 역할을 수행할 수 있는지 knowledge based 추론
- 결론적으로 LLM은 collaborative knowledge보다 content/context 정보에 의존
- popularity bias와 geographical region에 민감한 limitation을 제시
LLMS AS ZERO-SHOT CRS
- (ut,st,It)
- ranked item list를 최대한 gt item list와 유사하게 하는 것이 task의 목적
Framework
Prompting
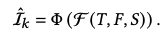
- LLM을 zero-shot conversational recommender로 만드는 것이 목적
- prompt의 example은 figure 1에 존재
Models
- deterministic result를 위해 temperature를 0으로 설정
- GPT-3.5-turbo, GPT-4, BAIZE, Vicuna를 사용
Processing
- NL output을 recommendation list로 변환하기 위해 fuzzy matching 등의 후처리 사용
DATASET
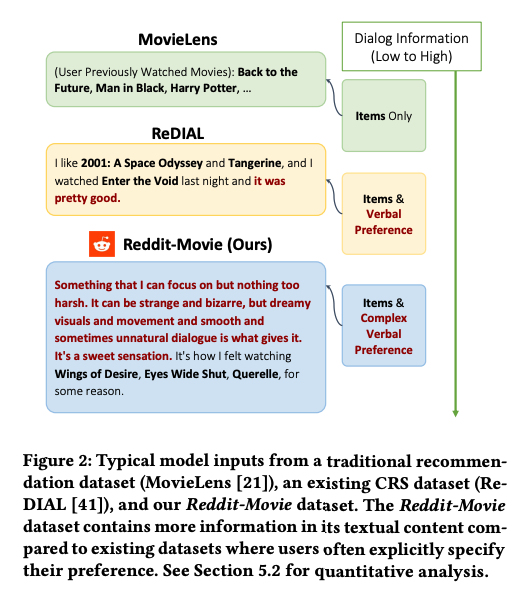
- real-world의 대화와 large-scale의 diverse interaction이 존재해야 이상적
- 그러나 대부분의 데이터 셋은 crowd-sourced로, '어떤 영화든 좋아' 등 모호한 답변이 다수 존재
- crowd worker는 특정한 취향 없이 labeling 했을 가능성이 높음
- 그러나 figure와 같이 real-world의 user는 특정 취향이 존재할 가능성이 높음
- 우리의 reddit-movie dataset은 large-scale real world dataset!
- ReDIAL, INSPIRED와 같은 crowd-sourced dataset에서도 실험 함
Dataset Construction
- 2012년 1월부터 2022년 12월 까지의 모든 reddit 게시물을 dataset으로 사용
- 5개의 영화 관련 subreddit
- 2022년 12월 이후 9000개의 대화를 test set으로 활용
- GPT-3.5-Turbo의 출시이후 dialogue로 data leakage에서 해방
Discussion
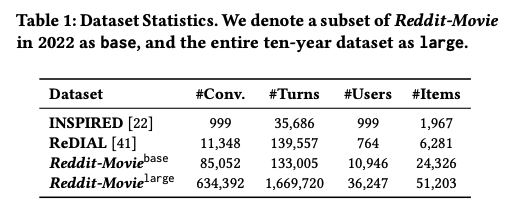
- 다음 통계를 보아, reddit-movie가 largest conversational recommendation dataset임을 확인할 수 있음
EVALUATION
- crowd sourced dataset과 ours 에서 LLM이 얼마나 잘 작동하는지 확인
Evaluation Setup
Repeated vs. New Items.
- conversation에서 GT recommended item을 구분하는 것은 challenging
- 우리는 conversation에 등장한 item을 repeated item과 new item으로 구분 (conversation 중 등장 했는지 아닌지)
Evaluation Protocol
Compared CRS Models
- ReDIAL, KBRD, KGSF, UniCRS 사용
- 각각 AE, semantic knowledge, knowledge graph to enhance MI maximization, PLMs based recommender
Repeated Items Can Be Shortcuts
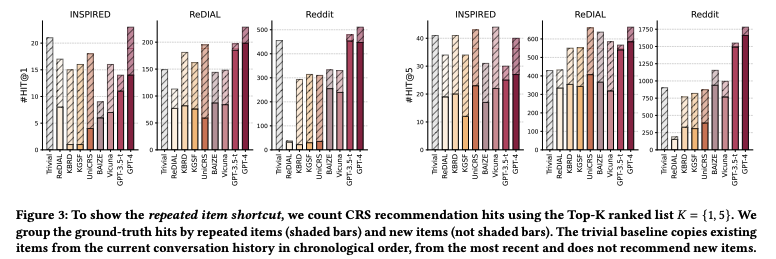
- 현존하는 CRS evalutaion은 repeated item과 new item의 구분을 두지 않음
- 이러한 지표는 모델이 repeated item을 반복함으로써 최적화하려는 현상을 유도
- figure를 보면 단순히 repeat하는 baseline이 이전 evaluation metric에서 높은 성능을 보임을 알 수 있음
- 이 현상은 shortcut learning으로 decision rule이 benchmark와 evaluation에서 우수하지만, design한 의도를 따라가지 못하는 현상
- 첫 figure와 같이, 반복된 item은 추천이라기 보다 discussion을 위한 매개체일 확률이 높음
- 따라서 반복된 Item을 제거하고, new-item만을 evaluation에 사용하는 것이 recommendation ability를 check 하는데 유용할 것
Findings 1
- LLM은 zero-shot setting에서 기존 CRS 모델을 outperform
Findings 2
- GPT-based model이 open-sourced LLMs보다 superior
- 이전 연구가 증명하듯, larger model > smaller model
Findings 3

- LLM은 out-of-dataset item title을 많이 generate하지만, hallucination은 아님
recommendation이 존재
- 이러한 item을 제거하지 않아도, 기존 모델보다 superior하지만 이를 제거할 경우 더욱 높은 성능
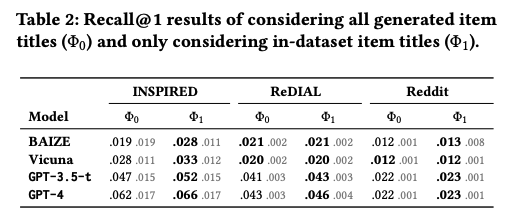
- 그러나 generate된 item이 IMDB에 존재하는 퍼센테이지는 gpt-4의 경우 95%로 할루시네이션은 아님을 알 수 있음
DETAILED ANALYSIS
- LLM이 왜 잘 작동하는지 and 어떤 한계가 존재하는지
Knowledge in LLMs
Experimental Setup
- 이전 연구와 유사하게, LLM이 사용하는 knowledge를 두 가지로 분리
- Collaborative
- Content/context
- 이 knowledge를 잘 사용하는지 보기 위해, S0,S1,S2,S3 original, interaction only, content only, random (eliminate sentence grammar structure)로 4가지 케이스를 실험
Findings 4
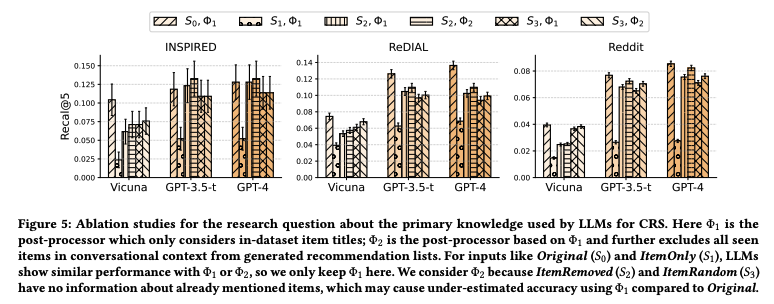
- LLM은 대부분 content/context 정보에 의존
- S0가 아닐 때 (모든 정보를 다 사용하지 않을 때) 공통적으로 performance drop이 있지만, context가 사라졌을때 60% 성능이 하락한 것과 달리 interaction이 사라지거나 random하게 replaced된 경우 단 10%의 성능 저하만이 존재
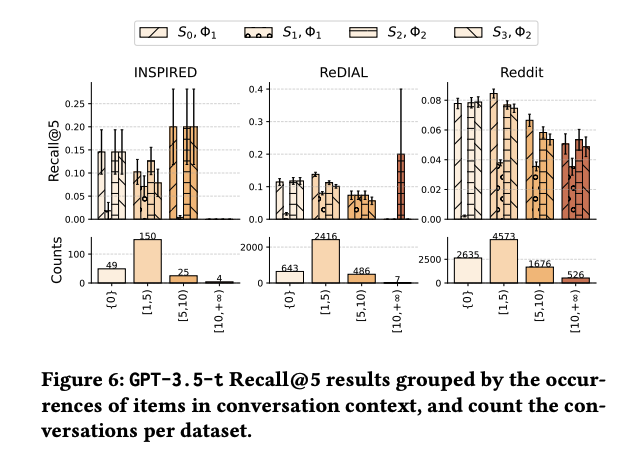
- 더 정교한 성능 비교를 위해 후처리 Processor를 구현한 뒤, 비교를 해보았음에도 robust하게 context의 영향이 큰 것을 알 수 있음
- 이는 기존 CF, Sequential recommendation과 다각화 되는 흥미로운 결과
Findings 5
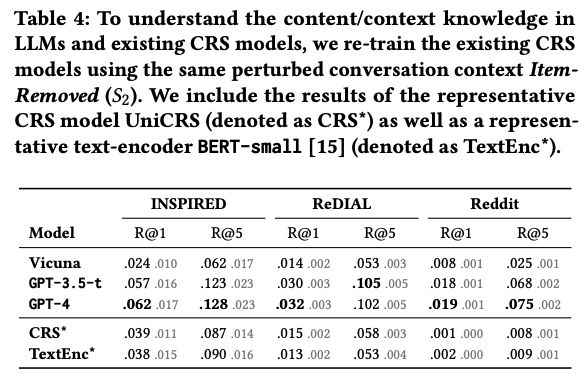
- GPT-based LLM이 existing CRS보다 더 좋은 context 정보를 소유함
- context only setting에서 GPT-based가 다른 모델을 압도
Findings 6
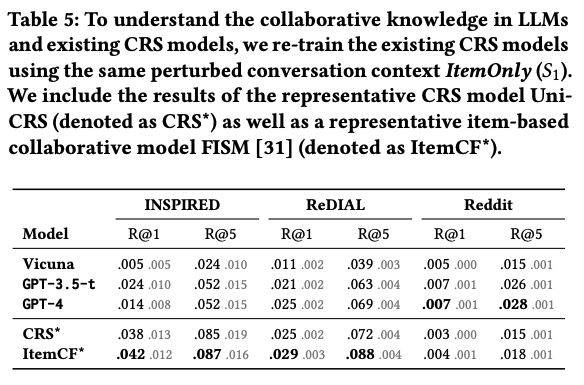
- LLM은 existing CRS보다 낮은 collaborative knowledge를 소유
- INSPIRED, ReDIAL에서 interaction only setting에서 다른 모델이 LLM-based보다 높은 성능
- 다양한 이유가 존재하는 것으로 보임
- training corpus가 LLM이 item similarity를 학습할 만큼 충분하지 않은 것
- collaborative knowledge가 존재하여도, item similarity는 dataset-platform dependent하기에 align하기 쉽지 않음
- 다만 Reddit Dataset에서는 LLM이 outperform 하는데, 데이터 셋 내부의 상호작용이 거의 없는 item이 많아 발생한 것으로 보임
- Reddit 데이터 셋 내에서는 12,982 아이템 중 3번 이상 답변된 것은 없음
- LLM은 그나마 title을 이해하는 능력이 높기 때문에 cold-start 환경에서 잘 대처한 것으로 보이며, 이는 cold-start problem을 LLM을 통해 해소하려는 기존 연구들과도 일맥 상통함
Experimental Setup for FInding 7.
- context/context information은 item title을 제외하더라도, conversation에 다수 포함되어 있음
- entropy-based evaluation을 통해 각 text에 포함된 정보의 량을 각 CRS dataset에 대해서 비교하려 함
- 다만 각 데이터셋의 size는 천차만별이며, 데이터셋의 size가 커질수록 entropy는 증가하므로 공정한 비교를 위해 점차적으로 커지는 dataset을 반복적으로 추출해 각 집합의 entropy를 추출하여 비교함
Finding 7
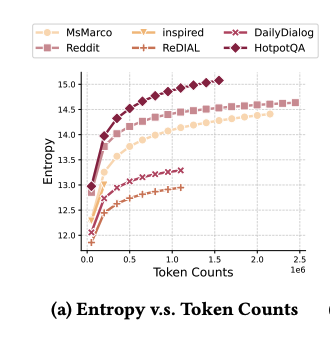
- Reddit dataset이 나머지 CRS dataset에 비해 더 많은 정보를 함유함
- 이는 LLM의 좋은 성능과 연결되며, 더 많은 데이터를 보유할 수록 성능이 더 좋아짐을 반증함
- 특히 Reddit dataset은 conversational search, question answering 수준의 entropy 보유량을 보여 다른 CRS 데이터셋에 비해 우위에 있음을 반증
Finding 8
- 현재 모델을 고려할 때, collaborative filtering으로 충분한 추천을 제공하기에는 역부족
- table을 보면 existing collaborative information model의 성능이 좋지 않음을 볼 수 있음 (content based recommendation이 더 좋은 성능)
- 우리는 두 가지 추측을 할 수 있음
- CRS dataset의 collaborative information을 반영하기 위해서는 더 발전된 모델, 학습 방법론이 필요함
- CRS dataset의 collaborative information은 충분한 추천을 하기에 부족하거나 제한적임
Experimental Setup for Finding 9.
- 순수한 Collaborative 데이터셋과 CRS 데이터셋의 collaborative information의 일치도를 찾아보기 위해 ML-25M, Reddit을 순서를 다르게 하여 fine-tuning 및 둘 다 fine-tuning하여 실험
Finding 9
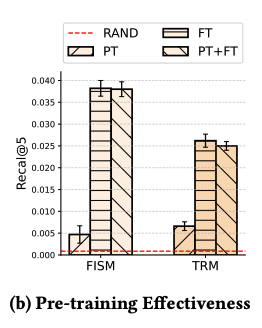
- Collaborative information은 dataset-platform dependent함
Limitations of LLMs as Zero-shot CRS
Finding 10
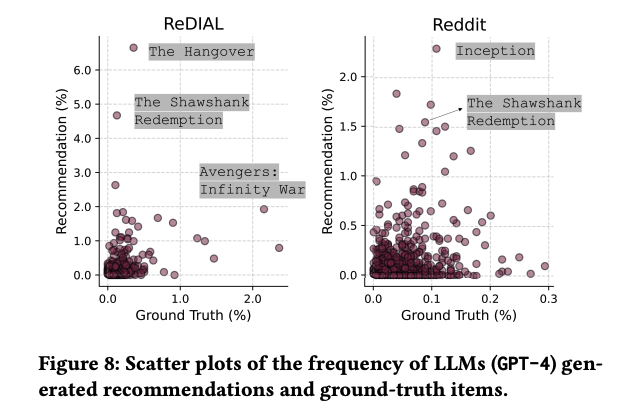
- LLM recommendation은 popularity bias가 존재함
- 다만 이는 실제로 가장 popular한 item이 아닌, LLM이 generate 하는 과정에서 Popular한 item이 생긴다는 것
- 이는 bias amplification loop (초기 편향이 다른 편향을 증폭시키는 현상) 등이 발생할 가능성을 내포
- 또한 이러한 item은 다른 데이터셋의 아이템과 유사한 것으로 보아, pre-training corpus에 의한 편향임을 알 수 있음
Finding 11
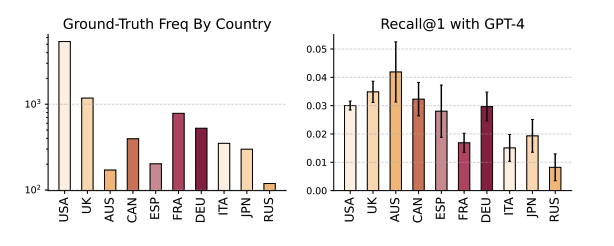
- LLM Recommendation 성능은 geographical region에 민감
- 좋은 성능에도 불구하고, various culture, region에 좋은 recommender임은 unclear
- LLM의 강력한 open domain performancesms 대규모 데이터의 fine tuning으로 가능하지만, 이는 데이터 분포에 민감하게 된다는 것을 의미
- figure로 볼 수 있듯, 영미권에서의 추천 성능이 높음 (학습 데이터의 bias로 보임)
