Deep Neural Networks for YouTube Recommendations (Recsys 2016)

INTRODUCTION
- 유튜브의 추천 시스템을 살펴보고자 함
- 총 3가지의 어려움이 존재
- Scale: 방대한 유저와 비디오 (효율적인 서빙 요구됨)
- Freshness: 매우 역동적인 비디오들이 수 초단위로 업로드 됨, 인기 있는 비디오와 새로운 비디오를 적절히 조절해야 하며 실시간성이 요구됨 (exploration/exploitation)
- Noise: 유저의 행동 정보는 본질적으로 Noisy함 (Implicit feedback siganl을 활용해야 함)
- 딥 러닝은 추천 시스템의 새로운 패러다임을 제시함
SYSTEM OVERVIEW
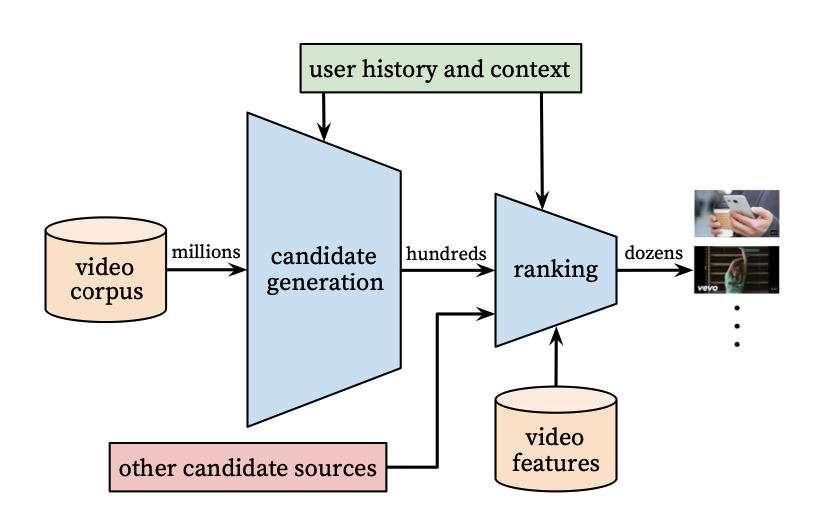
- candidate generation, ranking으로 이루어진 two-stage 모델
- 유저의 행동 이력을 기반으로 small subset을 추출하는 (약 100개) candidate generation
- few 'best' recommendation을 찾는 ranking (어떤 score를 부여해 계산)
- 이러한 two-stage 아키텍쳐는 수백만의 video corpus에서 개인화된 추천을 제공할 수 있음
- 모델링 과정에서는 precision, recall, ranking loss등 오프라인 지표를 이용하나, 최종적으로는 CTR, 체류 시간 등을 A/B test하여 결정
CANDIDATE GENERATION
- 수백만개의 비디오 -> 유저가 좋아할만한 100개의 비디오
Recommendation as Classification
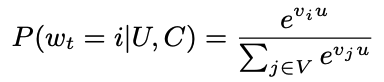
- 기본적으로 multiclass classification problem
- wt,U,C는 시간, 유저, 문맥(컨텍스트)에 해당
- 특정 시간에 유저가 i아이템을 볼 확률을 의미
- MF based로 학습이 진행되며, explicit feedback이 존재하긴 하지만 implicit feedback을 사용하여 학습함
- Implicit feedback이 훨씬 더 많기에, explicit feedback보다 long tail을 잘 catch할 수 있다는 가정
Efficient Extreme Multiclass
- 수 백만의 클래스를 다루는 모델을 학습시켜야 함
- Background 분포로부터 negative sample을 수집
- True Label과 negative sample간의 cross-entropy loss를 최소화 하는 방식으로 모델을 학습
- 모델 서빙에서는 Top N 연산을 위해 기존 유튜브 시스템의 hashing 방식을 사용하여 스코어링 시간을 sublinear하게 단축시킴
Model Architecture
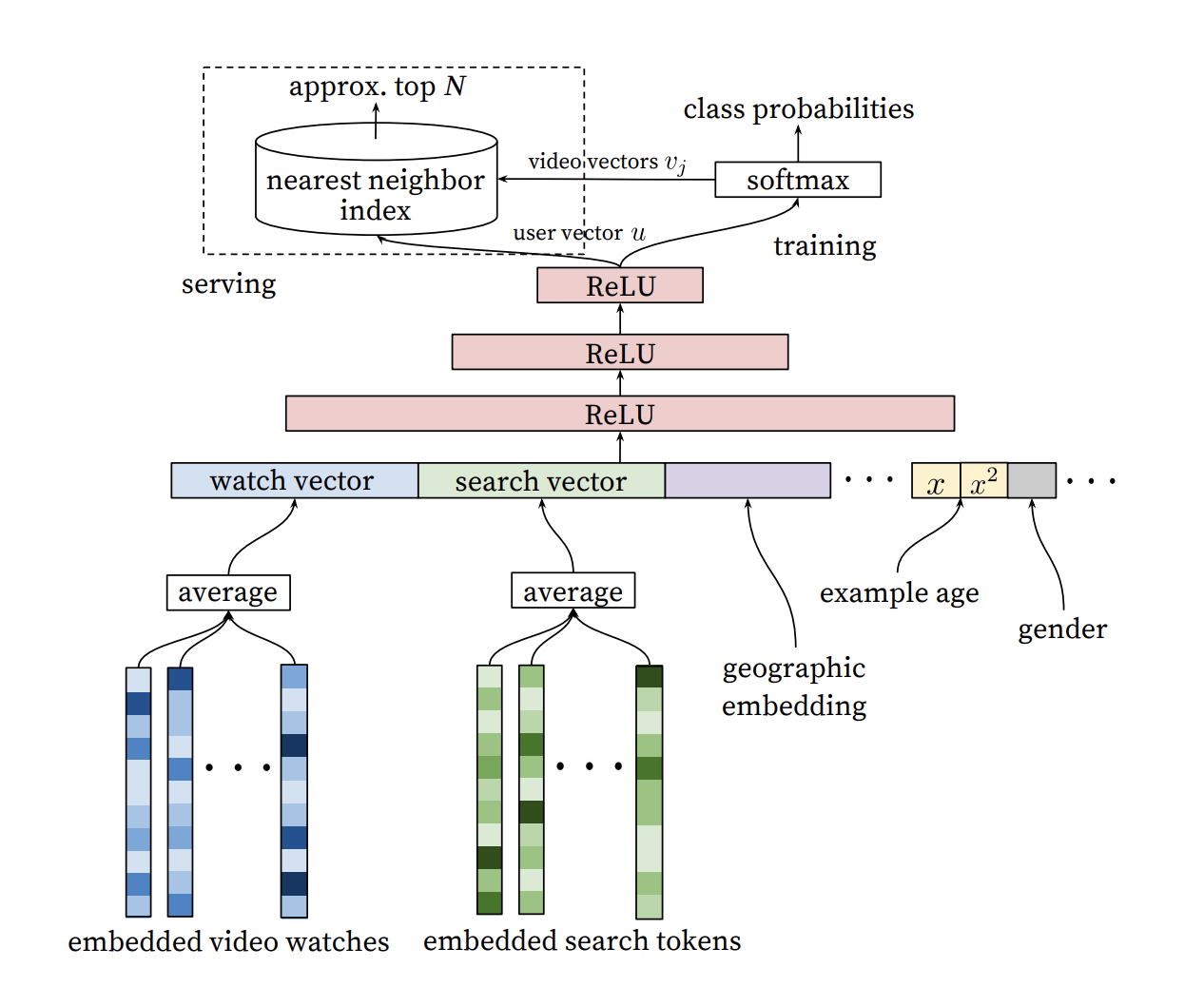
- 각 아이템별로 dense한 embedding으로 representation
- 유저의 아이템 이력 sequence를 embedding layer를 통해 representation하고 이를 average하여 dense input으로 활용
- 이외에도 user metadata를 concatenate하여 FC layer를 통과시키는 방식으로 학습
Heterogeneous Signals
- DNN을 MF의 generalization으로 사용하였을 때 이점은, continous와 categorical 변수를 조합하기 쉽다는 것에 있음
- 그 예시로 유저의 검색 query를 unigram, bigram 으로 tokenizing하여 embedding을 생성한 뒤, 이를 평균낸 dense vector를 input으로 활용 가능
- 인구통계학적인 정보 또한 0,1로 normalized되어 network에 추가할 수 있음
"Example Age" Feature
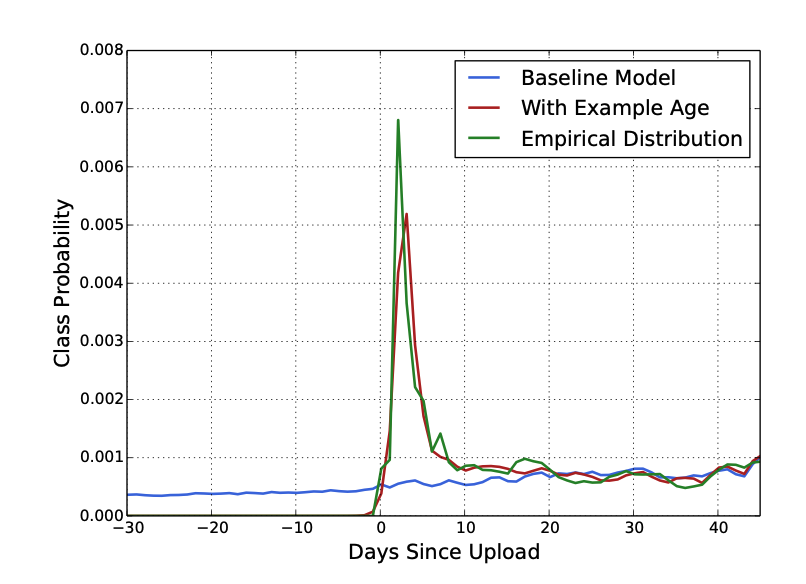
- 유저들은 fresh한 영상을 선호하는 경향이 있음
- ML 모델은 기존 패턴을 바탕으로 추천하기에, 과거의 아이템에 편향된 결과를 제공
- 비디오의 인기도 분포는 non-stationary하지만 추천 시스템에 의해 생성된 아이템의 다항분포는 몇 주간의 watch likelihood를 반영함
- 저자는 영상의 age를 feature로 추가하여 이를 해결해주고자 함
- 그래프를 통해 영상의 age를 추가하여 성능이 많이 개선됨을 알 수 있음
Label and Context Selection
- 추천 모델은 어떤 대리의 목표를 만족시킴으로써, 추천 결과를 향상시킴
- rating을 accurate하게 예측함으로써 더 효과적으로 영화를 추천함
- 오프라인 지표로 이를 측정하는 것은 어려운 문제
- 학습 데이터로는 우리의 추천 결과 뿐만이 아닌, 외부 사이트를 포함한 모든 데이터를 이용해야 함
- Exploitataion 문제가 발생할 수 있음
- 만약 우리의 추천이 아닌 다른 방식으로 영상을 탐색한다면, 바로 모델에 반영시켜주어야 함
- 또한 시청이 많은 유저에게 편향되지 않게 유저별로 데이터의 길이를 조정해야 함
- 또한 직관에 반대될 수 있지만, 추천 결과를 바로 서빙에 반영하지 않음
- 유저가 테일러 스위프트를 검색한 경우에 바로 다음에 이를 반영할 시 오히려 성능이 낮아짐을 empirical하게 발견
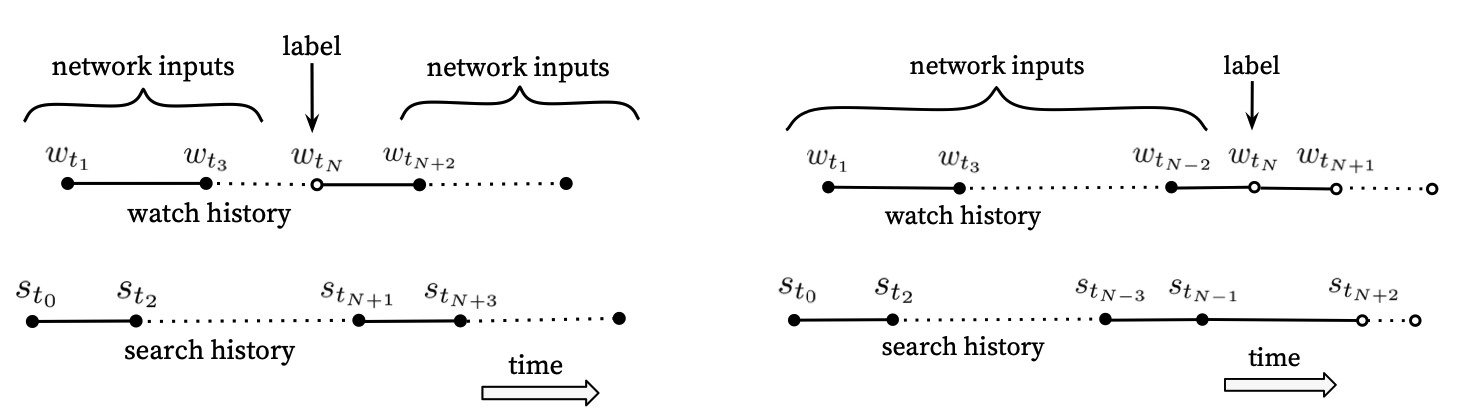
- 보통 모델은 이전과 이후의 기록을 통해 사이 label을 예측
- 이는 비대칭적인 영상 시적 패턴을 무시 (시계열적)
- 따라서 우측과 같이 해당 시점 이전의 기록만을 input으로 받게 하였음
Experiments with Features and Depth
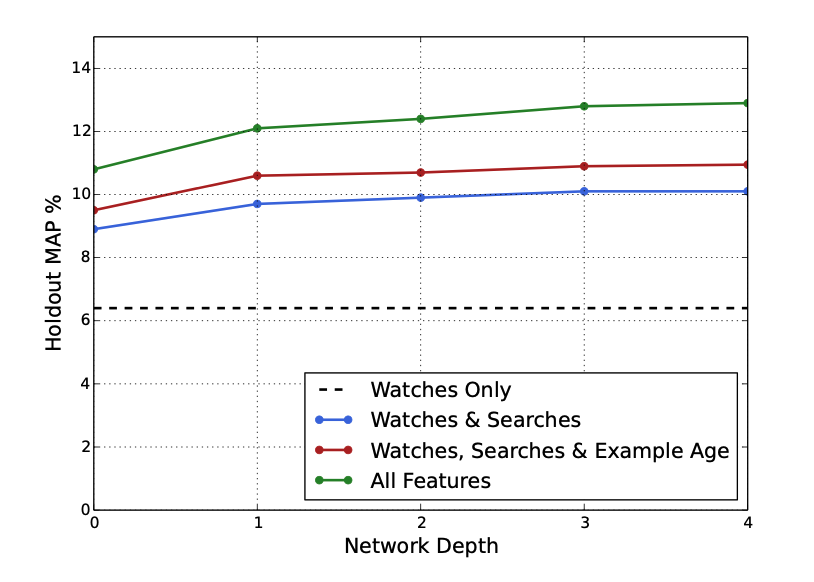
- feature와 network의 depth가 상승할수록 precision 또한 상승함
RANKING
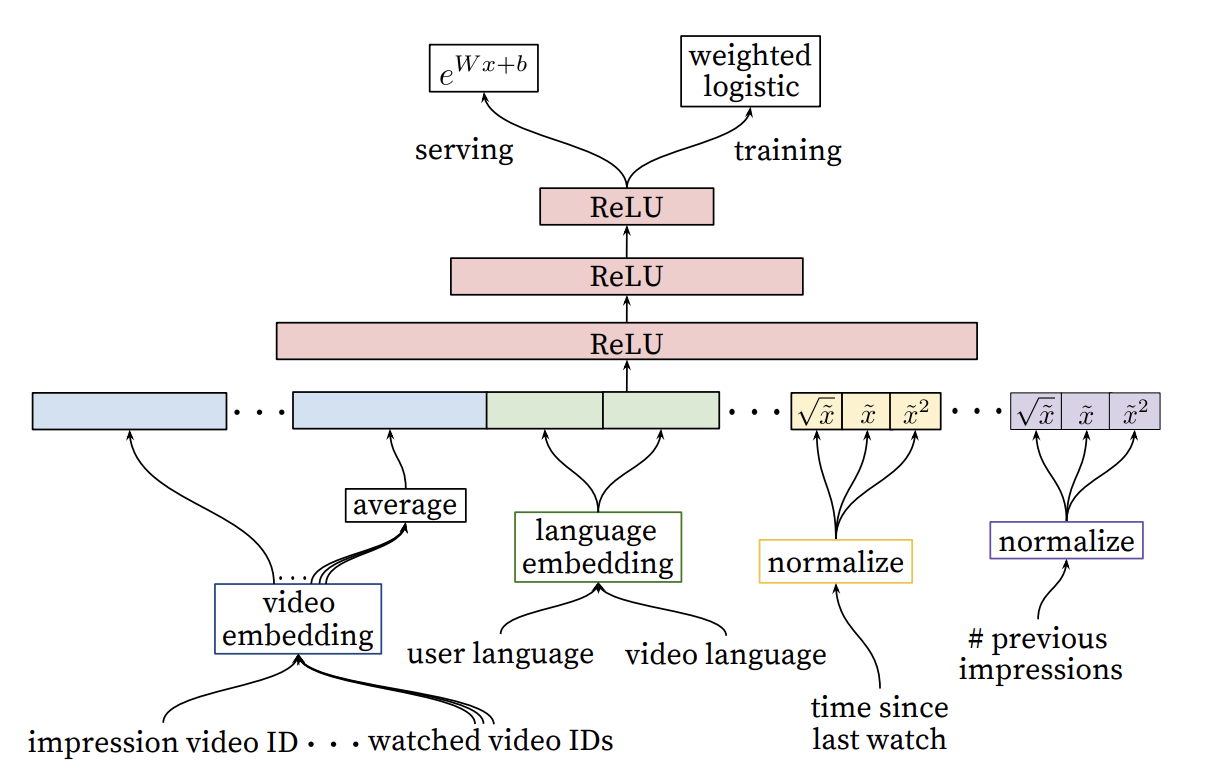
- Candidate에 정량적인 scoring
- Candidate와 유사하게 DNN과 Logistic Regression으로 구성
- A/B 테스트를 통해 모델을 최종 선정
- CTR은 'clickbait'와 같은 deceptive video에서 불완전할 수 있기 때문에, 시청 시간을 주 A/B테스트 방법론으로 설정
Feature Representation
- 굉장히 다양한 feature가 존재 (순서형, bianry, contious, list 등..)
- 크게 유저/context에 관한 query feature와 item에 관한 impression feature로 분리할 수 있음
- query feature는 한 번만 계산되며, impression feature는 매 아이템 마다 계산 됨
Feature Engineering
- 크게 continous, categorical로 분류 가능
- deep learning이 feature engineering을 필요로 하지 않는다 하더라도, raw feature을 feedforward하기 위해서는 어느정도 engineering 해야 함
- Main challenge는 현재 시점의 유저의 액션과 이를 impresseion score에 어떻게 반영할 것인가
- 가장 중요한 signal은 item과 유저의 과거 interaction이 얼마나 유사한지
- 이전 candidate generation에서 어떤 source가 이 아이템을 nominate하는지 또한 중요한 signal
- 특정 카테고리에서 이탈(연속적으로 보다가 시청하지 않음)하는 것도 중요한 signal
Embedding Categorical Features
- Candidate generation과 동일하게 sparse 데이터를 dense하게 embedding
- Top-N 개의 embedding만 생성하며, out of range의 경우 영벡터로 계산
- multivalent categorical feature는 속한 embedding을 average함으로써 계산
- 비디오 아이디는 다양한 곳에서 쓰이지만 (추천에 계산될 비디오, 이전에 시청한 비디오) 임베딩은 공유 됨 (concat 할 때 다른 위치로 옮겨지기에 여러 정보를 받을 수 있음)
Normalizing Continuous Features
- neural networks는 scail과 distribution에 민감 (cf; decision trees)
- (0,1)의 누적 확률 분포로 변환
- super, sublinear한 feature의 설명력을 높이기 위해 x2, 루트x를 사용함
Modeling Expected Watch Time
- 추천된 영상의 기대 시청 시간을 예측하기 위해서, weight logistic regression을 이용 (시청 시간을 weight로)
- Negative일 때는 시청 시간이 0이기에 unit weight를 부여
Experiments with Hidden Layers

- 성능과 inference time은 trade-off

정리가 잘 된 글이네요. 도움이 됐습니다.