BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding (NAACL 2019)
Paper Review

BERT
개요
Transformer에서 Encoder만을 사용하는데 Bidirectional Representation을 학습하는 모델
Masked Langauge model과 Next sentence prediction의 두가지 task를 지님
MLM은 ELMO는 forward와 backward를 따로 학습, GPT는 Transformer의 디코더 부분, 즉 후반부를 masking 해서 학습한 반면 BERT는 방향 상관없이 masking하여 사용하겠다는 것
NSP는 특정 두 쌍의 sentence가 input 되었을 때 해당 다음 corpus가 contextual하게 등장하는지 아닌지를 학습하는 것
이렇게 Pre-training 한 후 SQuAD, NER, MNLI 등의 Layer 하나만 추가함으로써 논문을 발표한 당시 SOTA를 달성
Model Architecture
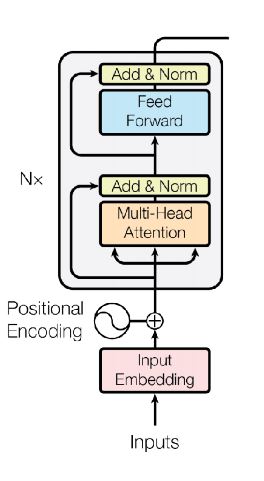
다음과 같이 Transformer의 Encoder 구조만 사용
하이퍼 파라미터는 다음과 같음
L: Number of layers (Transformer block)
H: hidden size
A: number of self attention heads (multi-head attention)
Input Representation
여러가지 down-stream Task를 수행하기 위해 Input representation을 single sentence, pair of sentence(question, answer)로 받을 수 있음
-
Sentence
넓은 범위에서 연속적인 단어의 나열
언어학적인 문장이 아니어도 상관 없음 -
Sequence
single sentence 혹은 paired sentence
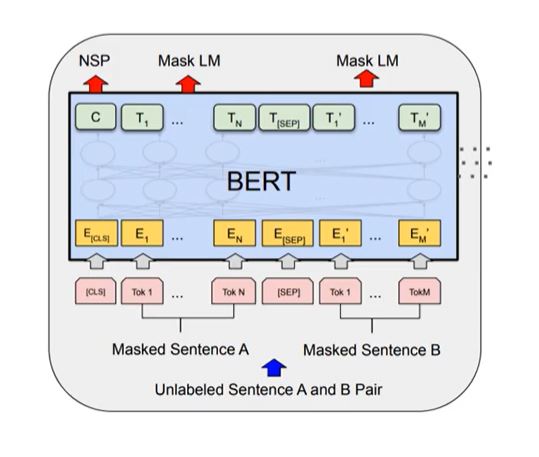
두 개의 paired Sentence를 SEP token으로 연결한 하나의 sequence를 input으로 받음
다만 각 sentence의 token을 random하게 masking하여 input으로 사용하니 unsupervised learning임
CLS token으로 sequence의 시작을 알림
이는 학습이 진행되는 과정에서 C라는 final hidden vector를 생성하는데 binary classification에서는 C vector만 사용
각각의 T vector는 N번째 Token의 final hidden vector이며, C로 NSP task를, T로 MLM task를 동시에 학습하는 것이 BERT의 목적
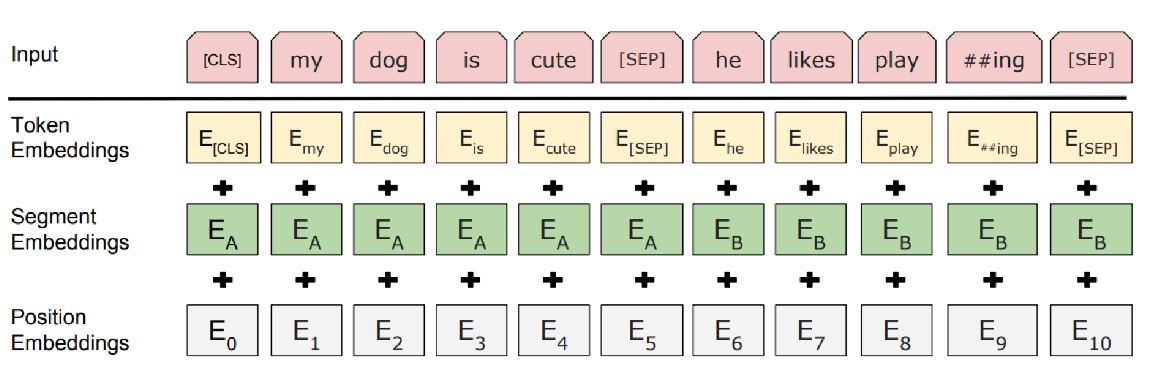
Input Representation은 Token Embedding, Segment embedding, Position embedding으로 구분 됨
-
Token embedding
30000개의 wordPiece embedding -
Segment embedding
어느 sentence에 해당하는 것인지 알려주는 정보, CLS token과 SEP 토큰은 첫 번째 문장에 속하도록 embedding 됨
Segment embedding 자체도 학습 되는 것 -
Postion embedding
transformer의 positional embedding과 동일
Masked Language Model (MLM)
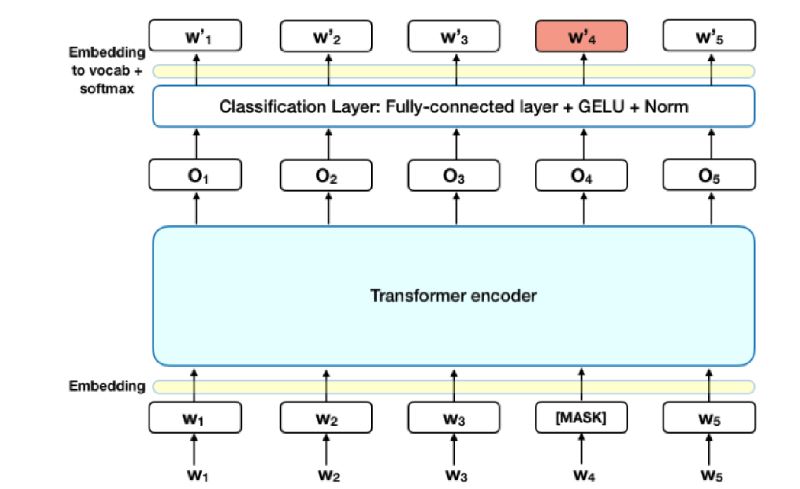
먼저 각 Sequence에 15%가 Mask Token으로 replace
이후 encoder를 통과한 Vector에 classification layer를 통과한 W'이 실제 W가 되도록 학습을 시켜주는 것이 MLM
ELMO는 단방향으로써 masking token을 예측할 때 순차적 선형 결합사용한 것과 달리 BERT는 순서 상관없이 예측하는 것
MLM의 문제점
masking은 pre-training 단계에만 발생하는 것으로, fine-tuning시에는 일어나지 않음
즉 이전 masking과의 충돌이 발생할 수 있음
이를 해결하기 위해 pre-training시 masking할 때, 80%는 실제 masking token, 10%는 전혀 상관 없는 token, 10%는 masking을 하지 않음
이를 통해 mismatch를 방지할 수 있다고 저자들은 말함
Next Sentence Prediction (NSP)
QA, NLI 등의 task는 문장 간의 관계를 학습할 수 있어야 좋은 성능을 낼 수 있는데, 문장 단위 학습의 Language model은 두 관계를 잘 이해할 수 없음 (ELMO와 GPT 등)
BERT의 NSP task는 이를 효과적으로 대처
한 corpus에서 50%의 sequence는 실제로 이어지는 pair의 sentence를, 50%의 sequence는 무관한 sentence로 설정하여 self-supervised learning을 진행

매우 단순한 아이디어이지만 성능 향상에 유의미한 차이가 존재
다른 모델과의 비교
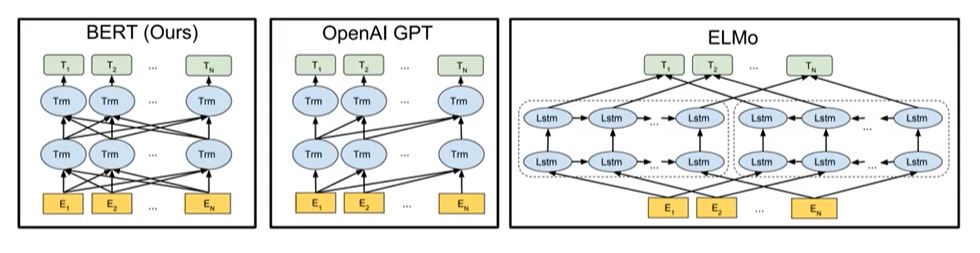
처음 등장한 엘모는 sequence들에 대해서 정방향의 forward lstm, 역방향의 backward lstm을 통해 해당하는 hidden state를 선형 결합으로 token을 만드는 것
GPT는 decoder block을 사용해 masking이 뒤쪽에만 적용 되는 것
BERT는 무작위 masking이 적용 되는 것
Fine-tuning
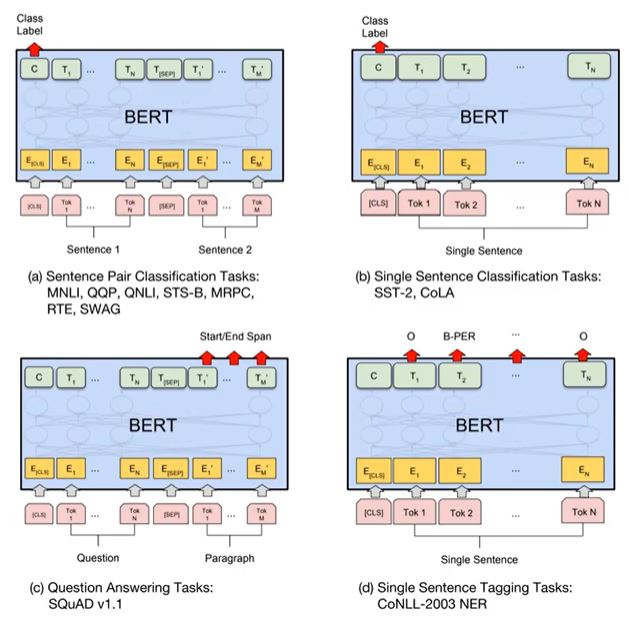
-
(a)
sentence pair를 입력으로 받아 Classification -
(b)
single sentence를 받아 Classification -
(c)
question과 paragraph가 들어왔을 때 paragraph를 생성해주는 task (생성 모델) -
(d)
single sentence를 받아 각 token 마다 답을 구하는 task (형태소 분석 등)
BERT의 Fine Tuning은 단순히 상단에 하나의 레이어를 쌓는 것 만으로 가능하다
실험
-
BERT가 등장했을 시기에 ELMO, GPT를 유의미하게 좋은 성능을 보임
-
NSP를 사용하는 Pre-training task가 효과가 있음
-
BERT-base에서 BERT-large로 갈수록 성능이 상승
Feature-based approach
Fine tuning을 하지 않은 상태에서의 성능
Weighted sum 하거나 마지막 layer 4개를 concat 하였을 때 fine tuning 한 것과 성능 차이가 거의 없음
