3D point clouds bounding box detection and tracking (PointNet, PointNet++, LaserNet, Point Pillars and Complex Yolo) — Series 5 (Part 1) 리뷰
[원문 번역]
(직접 번역한 내용이며 부족한 배경지식으로인한 오역 등이 있을 수 있음)
자율 주행 차량과 로봇 공학에서 Point Cloud 관련 프로그램이 개발되면서 Point Cloud 학습에 대한 관심이 높아졌다.
LiDar(Light Detection and Ranging) 장비가 활용되며 도로 환경에 대한 3D Point Cloud 데이터셋들을 생겨났다.
자율 주행에서 가장 많이 활용되는 오픈소스 데이터셋은 아래와 같다.
- Kitti Dataset (http://www.cvlibs.net/datasets/kitti/)
- NuScenes Dataset (https://www.nuscenes.org/)
- Lyft Level 5 dataset (https://self-driving.lyft.com/level5/)
Deep Learning for 3D Point Clouds: A Survey
해당 논문(Deep Learning for 3D Point Clouds: A Survey)에서는 3D Point Cloud가 사용된 3가지 프로그램(3D Shape Classification, 3D Object Detection and Tracking, 3D Point Cloud Segmentation)을 소개하고 있다. 이 중 3D Object Detection에서 사용된 기술들은 자율 주행 연구에서도 널리 쓰이는 방식이다. 이것이 바로 이번 기사에서 다루고자 하는 것이다.
이미지 출처: Deep learning for 3D point clouds, Yulan Guo et. al.
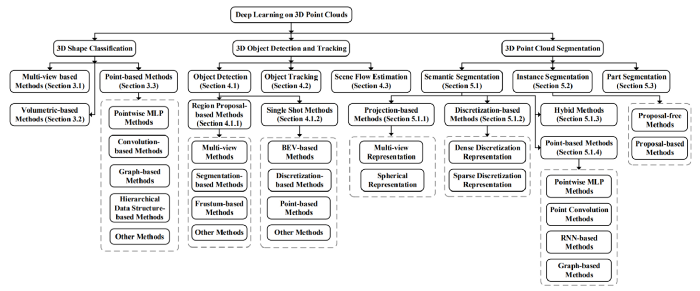
Region Proposal based methods: 이런 방식은 포인트 클라우드 내 여러 구역을 우선 나누고 구역마다 라벨링을 위한 특징을 추출한다. 이를 다시 아래와 같이 4가지 유형으로 나뉜다.
- Multi-View based methods
- 전면 카메라, 후면 카메라, LiDAR 장비 등등에서 추출한 여러 시각 정보를 녹여내는 방식.
- 굉장히 높은 정확도가 장점이지만 연산 속도가 느리다는 단점이 있다.
- Segmentation based methods
- 보다 신속한 물체 인식을 위해 기존 이미 분류 방식으로 배경에 속하는 점들부터 삭제하는 방식.
- Multi-view based 방식에 비해 높은 물체 인식률을 보이며 많은 물체들이 뒤섞여 가려지기도 하는 복잡한 상황에 더욱 적합한 방식.
- Frustum based methods
- 우선 2D Object detection 방식으로 물체에 해당하는 구역을 나누고 각 구역을 3D 포인트 클라우드 분할 방식으로 분석하는 방식.
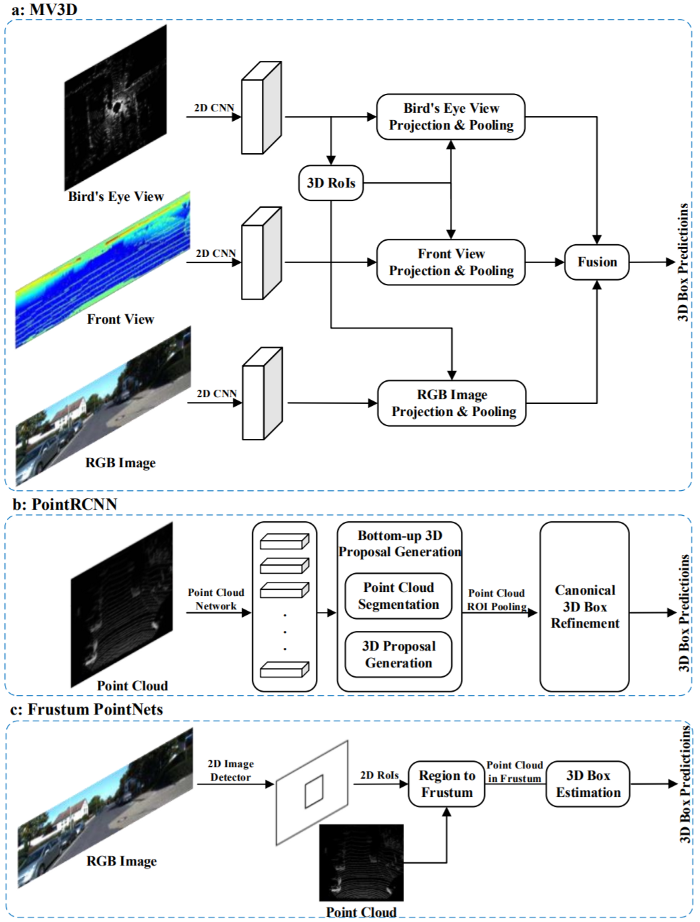
Single Shot Methods: single-stage network을 이용해 곧바로 물체 가능성을 예측해내는 방식. 이는 아래와 같이 다시 3가지 방식으로 나뉜다.
- BEV (Bird’s Eye View) based methods
- 위에서 내려다보는 2D 이미지인 BEV (Bird’s Eye View)와 완전한 복잡형 인공신경망(Fully Convolutional Networks)을 활용하여 bounding box를 예측하는 방식.
- Discretization based methods
- 우선 포인트 클라우드에 이산 변환을 적용한 후 완전한 복잡형 인공신경망(FCN)으로 bounding box를 예측하는 방식.
- 이 방식이 가장 유명한 방식이며 후속 기사에서 상세히 다룰 예정이다.
- The point-based methods 과 기타 방식은 크게 중요하지 않으므로 자세한 내용은 논문을 참고.
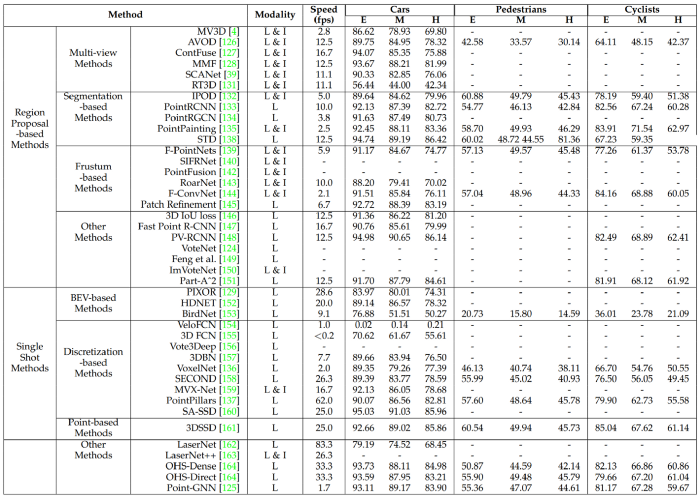
Average Precision of Various methods on the Kitti Dataset
Multi-View based methods가 느리다고 소개되어 있는데 Kitti Dataset에서의 성능표를 보면 함께 소개된 다른 methods에 비해 그다지 느리지 않을 것으로 나온다. 다만, 해당 표의 하단을 보면 이 글에서 소개되지 않은 다른 방식이 훨씬 빠른 속도를 보여준다는 것을 고려할 때, Multi-View based methods뿐 아니라 이 글에서 소개된 Region Proposal based methods 전부가 느리다는 것을 말하려던 것을 아닐까 추측해본다.
자율 주행과 같은 목적으로 사용하기에는 약 10 fps 이하의 속도는 실용성이 현저히 떨어지는 것 같다.
