Today do list
⦁ 경매 생성시 경매 채팅방 생성
⦁ 상세 페이지 접근시 경매 채팅방 roomId반환
⦁ 경매 채팅메시지 시간, 닉네임, 프로필이미지 반환
TIL
저장소에 관하여
채팅 시스템에서 데이터 계층을 올바르게 만드는 데는 노력이 필요하다. 중요한 것은 어떤 데이터베이스를 쓰느냐다. 관계형데이터베이스를 쓸것인가? 아니면 NoSQL을 사용 할 것인가이다.
이것을 선택할때 중요한 기준은 데이터의 유형과 읽기/쓰기 연산의 패턴이다.
채팅 시스템이 다루는 데이터는 보통 2가지다.
첫 번째는 사용자 프로파일, 설정, 친구 목록처럼 일반적인 데이터다. 이런 데이터는 안정성을 보장하는 관계형 데이터베이스에 보관한다. 다중화와 샤딩은 이런 데이터의 가용성과 규모의 확장성을 보증하기 위해 보편적으로 사용되는 기술이다.
두번째 유형의 데이터는 채팅 시스템에 고유한 데이터로, 바로 채팅 이력이다. 이 데이터를 어떻게 보관할지 결정하려면 읽기/쓰기 연산 패턴을 이해해야 한다.
- 채팅 이력 데이터의 양은 엄청나다. 페이스북 메신저나 왓츠앱은 매일 600억개의 메시지를 처리한다.
- 이 데이터 가운데 빈번하게 사용되는 것은 주로 최근에 주고받은 메시지다. 대부분의 사용자는 오래된 메시지는 들여다 보지 않는다.
- 사용자는 대체로 최근에 주고받은 메시지 데이터만 보게 되는 것이 사실이나, 검색 기능을 이용하거나, 특정 사용자가 언급된 메시지를 보거나, 특정 메시지로 점프하거나 하여 무작위적인 데이터 접근을 하게 되는 일도 있다. 데이터 계층은 이런 기능도 지원해야 한다.
- 1:1 채팅 앱의 경우 일기:쓰기 비율은 대략 1:1 정도이다.
이 모두를 지원할 데이터베이스를 고르는 것은 아주 중요한 일이다. 키-값 저장소를 추천할 것인데, 그 이유는 다음과 같다.
- 키-값 저장소는 수평적 규모확장이 쉽다.
- 키-값 저장소는 데이터 접근 지연시간이 낮다.
- 관계형 데이터베이스는 데이터 가운데 롱 테일에 해당하는 부분을 잘 처리하지 못하는 경향이 있다. 인덱스가 커지면 데이터에 대한 무작위적 접근을 처리하는 비용이 늘어난다.
- 이미 많은 안정적인 채팅 시스템이 키-값 저장소를 채택하고 있다. 페이스북 메신저나 디스코드가 그 사례다. 페이스북 메신저는 HBase를 사용하고 있고 디스코는 카산드라를 이용하고 있다.
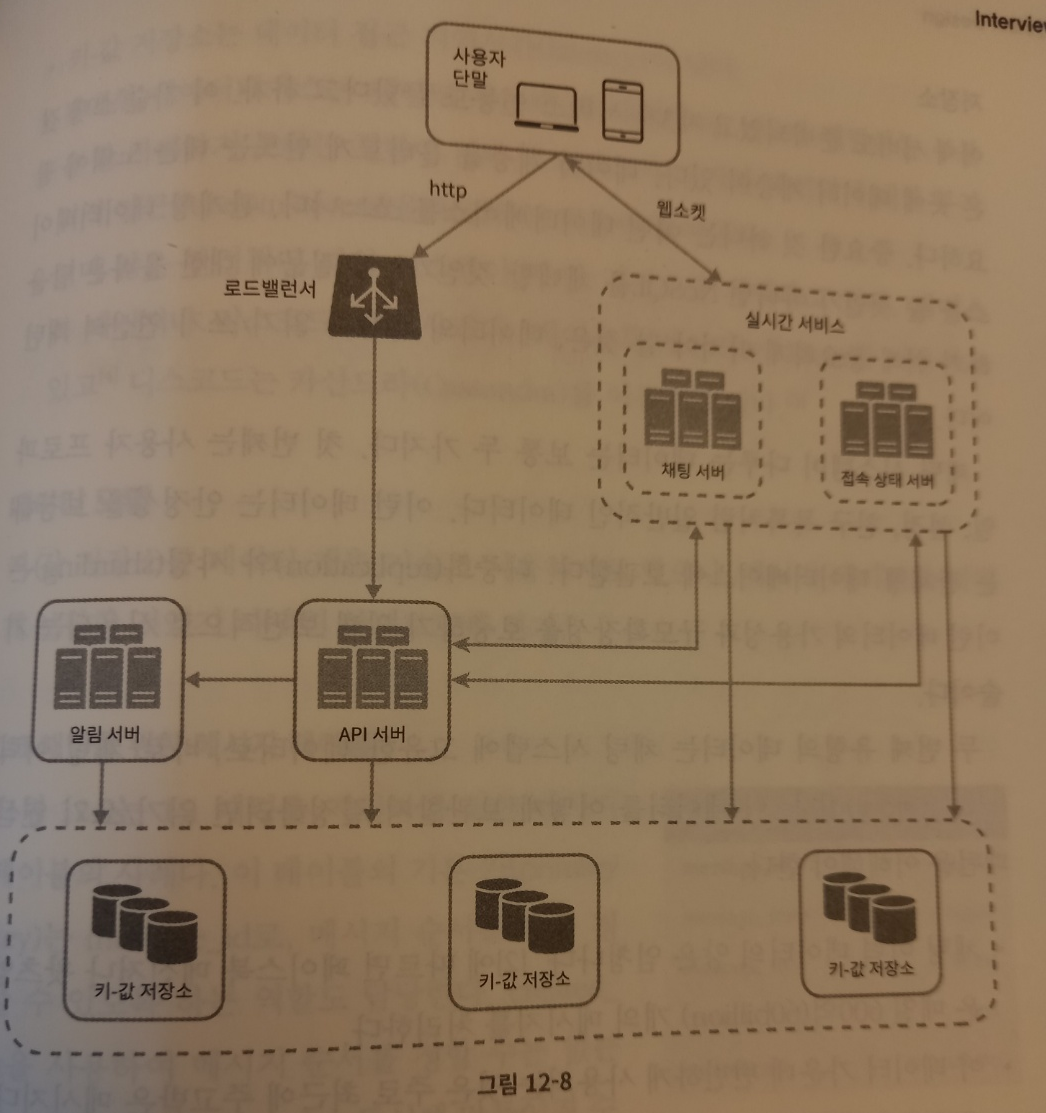
가상면접 사례로 배우는 대규모 시스템 설계 기초 P.208
Retrospection
낙찰 후 1:1 채팅 로직
-
경매 남은 시간이 0이 된다.
-
클라이언트에서 자동으로 낙찰자 조회 api를 호출한다.(request: auctionId)
- 서버에서 판매자와 낙찰자를 조회한다.
- 판매자의 채팅방을 생성한다.
- 경매 상세페이지 정보, 판매자 memberId, 낙찰자 memberId, roomId를 response
-
클라이언트는 로그인한 유저의 토큰값과 response받은 낙찰자를 비교하여
(프론트에서 가능한가요? 아니라면 api를 하나 더 만들면 됩니다.
만약 api를 만든다면 낙찰자가 맞다면 true, 낙찰자가 아니라면 false를 반환 해드릴 계획입니다.)
낙찰자가 맞다면 낙찰하기? 채팅방이동? 버튼을 보여준다.
아니라면 "이미 낙찰된 경매입니다."식으로 다른 사용자에게 알려준다. -
사용자가 버튼을 클릭하면 낙찰하기? 채팅방입장? api(/chat/room/enter/{roomId})가 호출되고
해당 채팅방으로 이동한다.
-
Stomp로 만든 기본예제를 공부하고 실제적으로 위와 같이 채팅 로직을 우리 나름대로 작성해보고 우리 프로젝트에 적용하려고 하니 실제적으로 채팅방 목록과 채팅방별 메시지 목록을 db에 기본적으로 저장이 필요하다는 결론이 났다.
-
그런데 만약 데이터가 쌓여서 엄청나게 많은 컬럼이 저장된다면 이것을 일일이 찾아서 꺼내오는 것도 문제이지만 이 테이블이 사용자마다 조회된다면 서버에 부담이 많이 갈것이라는 것을 생각했다.
-
이것에 대해서 고민하던중 redis라는 것을 알게 되었는데 in-memory기반의 캐싱 시스템이었다. 다만 이것을 스프링에서도 지원을 해주는데 embeded redis라는 것으로 해당 컴퓨터의 메모리를 사용하는 것이다.
또한 AWS에서도 제공하는 ElasticCaChe를 사용하는 AWS Redis라는 것도 있는데 이것은 AWS에서 제공해주는 말그대로 AWS redis서버라고 할 수있다. -
팀원들과 embeded냐 AWS냐로 생각을 나누던중, scale-up, scale-out이 나오게 되었다. 즉 수평적 확장과 수직적 확장으로 논의가 넓혀졌다.
-
결국 AWS Redis쪽으로 기울어졌고 자연스레 scale-out적인 방향이 되었다.
-
이번 채팅 시스템을 개발하면서 기술 설계와 좀더 정확하고 효율적인 테이블 구조 및 쿼리 사용 캐시시스템을 활용한 것 까지 정말로 여러가지로 생각할 것이 많았다.
-
나와 팀원분들도 개발과 동시에 많은 이론공부를 하고 토론하고 프로젝트의 방향과 개발의 효율성등을 이때껏 들어보지 못한 단어와 용어들을 서로 말하고 공부하고 토론하게 될줄은 정말 몰랐다.
Tommorrow do list
- 중간 발표 준비및 코드정리.
ps. 회고 작성후 또 개발해야 된다. 중간발표가 얼마 남지 않았다. 이번주 토요일이다! 잠온다......
