시간이 없어서.......
안 풀었던 문제부터 풀겠습니다
죄송합니다ㅜ
11404 플로이드
📌문제 링크
https://www.acmicpc.net/problem/11404
💡 문제 풀이
최단 경로 문제
처음에 출력결과 보고 이게 뭔소리야... 했는데 좀만 더 생각해보니 최단거리 nxn 표를 만들라는 거였다
모든 경우의 수를 계산해야 하는데, 다익스트라는 한 노드에서 각 노드로 가는 최단 경로 리스트를 갱신하니 다익스트라를 n번 하면 된다고 생각했다
다익스트라 코드는 책을 참고했다.....
언제쯤 완전히 이해하고 안 보고 칠 수 있을까
📋코드
# 11404 플로이드
import sys
import heapq
INF = int(1e9)
n = int(input()) # 도시의 개수
m = int(input()) # 버스의 개수
graph = [[] for _ in range(n + 1)]
# 버스 정보 입력
for i in range(m):
# 시작 도시 a, 도착 도시 b, 한 번 타는 데 필요한 비용 c
a, b, c = map(int, sys.stdin.readline().split())
graph[a].append([b, c])
def dijkstra(start):
distance = [INF] * (n + 1) # 초기화
q = []
heapq.heappush(q, (0, start))
distance[start] = 0
while q: # 큐가 비어있지 않다면
# 가장 최단 거리가 짧은 노드 pop
dist, now = heapq.heappop(q)
# 이미 처리한 노드라면 무시
if distance[now] < dist:
continue
for node in graph[now]:
cost = dist + node[1]
if cost < distance[node[0]]:
distance[node[0]] = cost
heapq.heappush(q, [cost, node[0]])
for j in range(1, n + 1):
if distance[j] == INF:
print(0, end=" ")
else:
print(distance[j], end=" ")
print()
for i in range(1, n + 1):
dijkstra(i)
생각해보니까 이름부터 플로이드인데 플로이드-워셜 안 쓰고 냅다 다익스트라 썼네....
다음에 플로이드-워셜 알고리즘으로 다시 풀어봐야겠다
42891 무지의 먹방 라이브
프로그래머스도 이렇게 고유번호 있는 게 맞나요???ㅎㅎ
나 진짜 알못이네
📌문제 링크
https://programmers.co.kr/learn/courses/30/lessons/42891
💡 문제 풀이
그리디 문제
처음에 보고 입력을... 어떻게 받으라는 거지???? 라고 생각했는데 입력을 받을 필요가 없었다. 함수만 작성하면 되는거였다..... ㄱ-
처음에 생각한 방법들
1. 진짜 단순하게 for문 돌려가며 1씩 뺀다 -> 효율성 극악일 것 같아서 일단 패스
2. int(k % len(food_times))번째 음식이 결과 아닌가? 잠깐 생각했다가 그 전에 다 먹은 음식 있을 수 있으니 기각
그러다 뭔가 2번을 응용해서 효율적으로 풀 수 있을 것 같다는 생각이 들었다
- k초동안 회전판을 최대 몇 바퀴 돌 수 있는지를 구한다
turn = int(k / len(food_times)- 최소 한 음식을 다 먹을 때 까지 몇 바퀴 돌 수 있는지 구한다
n = min(min(food_times), turn)- food_times의 모든 원소에서 n만큼 빼고, 0이 아닌 원소들만 [남은 시간, 인덱스 번호] 배열을 만들어 deque에 넣는다.
- 다 돌고 남은 시간 동안, deq를 rotate시키면서 1씩 빼고 남은 시간이 0이면 pop시킨다.
- 남은 음식이 있다면 답은 deq[0][1]이고, 남은 음식이 없다면 답은 -1이다.
📋코드
from collections import deque
def solution(food_times, k):
length = len(food_times)
deq = deque()
# 최소 몇 바퀴 돌 수 있는지
turn = int(k / length)
# 한 음식을 다 먹을 때 까지 or 최대 회전할 수 있는 만큼 먹기 (빼기)
n = min(min(food_times), turn)
for i in range(length):
# 다 먹었으면 제외시킴
if food_times[i] - n == 0:
continue
deq.append([food_times[i] - n, i + 1])
# n바퀴 순회하고 장애까지 남은 시간
remain = k - n * length
# 남은 시간 동안
while deq and remain > 0:
# 다 먹었으면 제외시킴
if deq[0][0] - 1 == 0:
deq.popleft()
remain -= 1
continue
deq[0] = [deq[0][0] - 1, deq[0][1]]
# 회전
deq.rotate(-1)
remain -= 1
if deq:
answer = deq[0][1]
else: # 더 섭취해야할 음식이 없을 때
answer = -1
return answer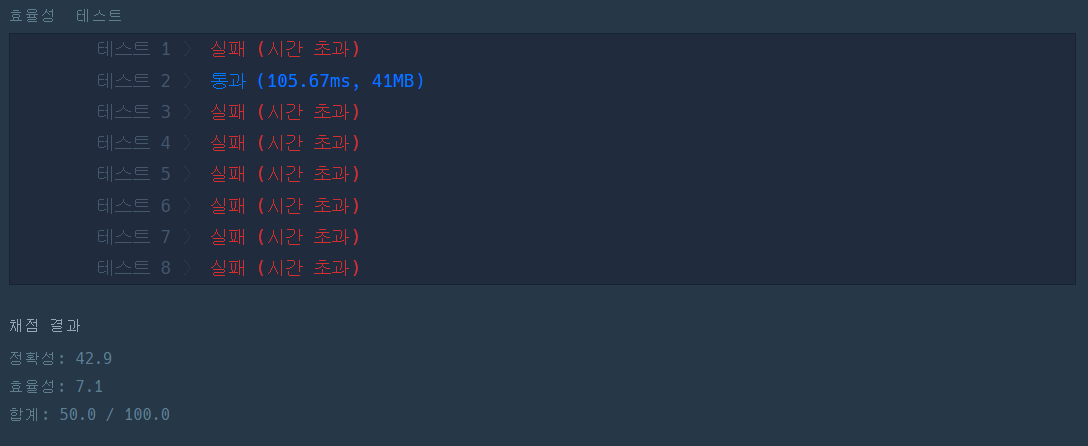
정확성 테스트는 다 통과했는데 효율성 테스트는 2번 케이스 빼고 다 실패했다.......
💡 문제 풀이2
찾아보니 heapq를 사용해서 먹는 시간이 짧은 음식부터 계산하는 방법이 있었다
코드 참고 : https://mjmjmj98.tistory.com/149
📋코드2
import heapq
def solution(food_times, k):
answer = -1
h = []
for i in range(len(food_times)):
heapq.heappush(h, (food_times[i], i + 1))
food_num = len(food_times) # 남은 음식 개수
previous = 0 # 이전에 제거한 음식을 다 먹는 데 걸리는 시간
while h:
# 현재 음식을 다 먹는 데 걸리는 시간 :
# (현재 음식의 food_time - previous) * 남은 음식의 개수
# 다시 말해서, 현재 음식의 남은 food_time 번 만큼 회전하는 데 걸리는 시간
t = (h[0][0] - previous) * food_num
# 시간이 남을 경우 현재 음식 다 먹기
if k >= t:
k -= t
previous = heapq.heappop(h)[0]
food_num -= 1
# 현재 음식을 다 먹을 시간이 없을 경우
else:
# 시간이 가장 짧게 걸리는 음식도 다 못 먹으니
# 최대로 회전할 수 있을 만큼 회전시켜도 food_num은 그대로임
# 따라서 k % food_num 번째 음식이 정답
idx = k % food_num
# 인덱스를 기준으로 힙 정렬
h.sort(key=lambda x: x[1])
answer = h[idx][1]
break
return answer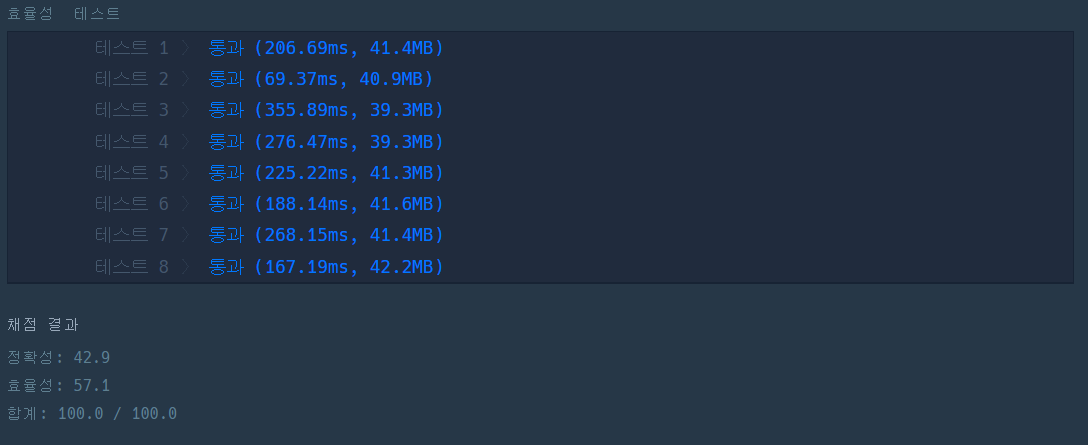
효율성 테스트까지 만점 통과
60060 가사 검색
📌문제 링크
https://programmers.co.kr/learn/courses/30/lessons/60060
💡 문제 풀이
열심히 그리디 풀고 나니까 이것도 그리디로 풀면 되나?ㅋㅋ 라고 생각했는데 이진탐색 문제였다...
처음에 생각한 것
- fro??? 같이 접두사를 찾을 경우 words를 정렬한 다음 이진탐색으로 "fro"로 시작하는 upper bound와 lower bound를 찾고 그 사이를 순차 탐색해서 뒤에 3글자만 있는 단어들을 찾는다
- 접미사를 찾을 땐.... 어떻게해야되지???
이걸 내 머리로 생각해 낼 시간도 없고 자신도 없어서 구글링했다..
문자열 검색 알고리즘인 Trie를 사용하는 거라고 한다
원래 Trie는 말 그대로 문자열을 '검색'하는 거라 문자열의 끝을 표시하는 flag를 쓰는데, 여기서는 접두사만 검색하니 flag 대신 해당 접두사를 가지는 단어의 수 count를 쓴다.
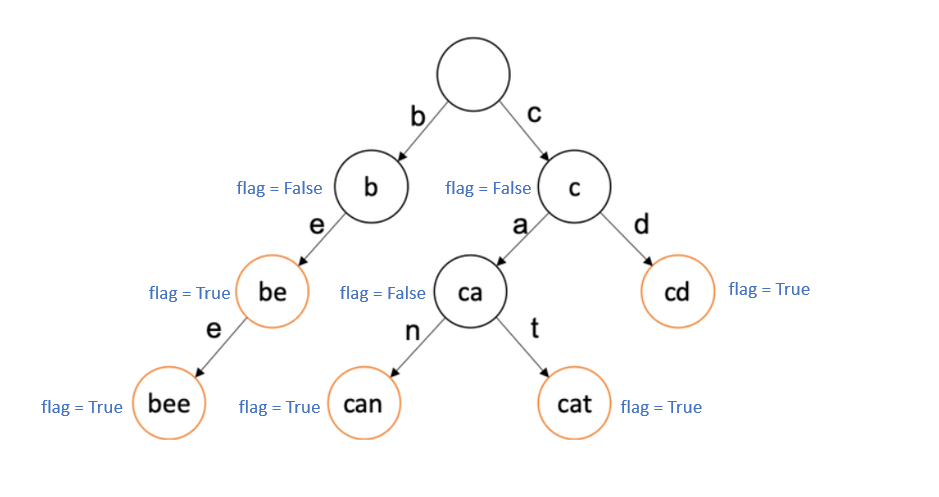
노란색 원 안에 있는 단어가 완전한 단어라고 했을 때,
원래 Trie가 문자열을 이렇게 사용한다면
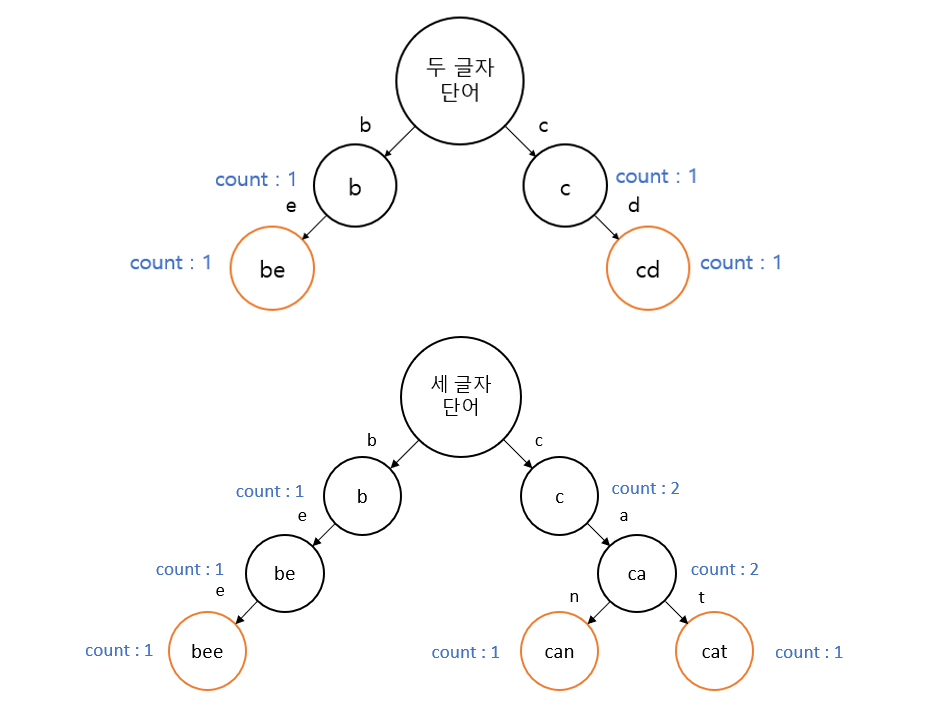
이 문제에서는 Trie를 이렇게 사용했다
Trie 설명 참고
https://twpower.github.io/187-trie-concept-and-basic-problem
defaultdict 설명 참고
https://dongdongfather.tistory.com/69
코드 참고
https://bladejun.tistory.com/139
https://hkim-data.tistory.com/m/174
구글링하면 코드는 많이 나와있는데, 주석과 그림으로 같이 설명해주는 코드는 잘 없어서 이해하는 데 꽤 걸렸다....
📋코드
from collections import defaultdict
class Trie():
def __init__(self):
# 자식 노드
self.child = {}
# 현재 노드 (알파벳) 까지의 단어 개수
self.count = 0
# 문자열 삽입
def insert(self, str):
# cursor 설정 (head 부터 시작)
cur = self
# 현재 노드 count 1 증가
cur.count += 1
# 한 문자씩
for s in str:
# 자식 노드 중 해당 문자가 없다면
if s not in cur.child:
# 새로운 Trie를 구성한다
cur.child[s] = Trie()
# cursor를 다음 문자 노드로 옮겨준다
cur = cur.child[s]
cur.count += 1
# 문자열 검색
def search(self, str):
# cursor 설정 (head 부터 시작)
cur = self
for s in str:
# ? 문자를 만났으면 해당 query 문자를 다 찾은 것
if s == '?':
return cur.count
# 해당하는 문자가 없을 때 0 리턴
if s not in cur.child:
return 0
# 다음 자식 노드로 이동
else:
cur = cur.child[s]
# 끝까지 다 찾았을 경우 현재 노드의 count 리턴
return cur.count
def solution(words, queries):
answer = []
# 접두사 Trie
prefix_trie = defaultdict(Trie)
# 접미사 Trie
suffix_trie = defaultdict(Trie)
# defaultdict를 사용하면 해당 키에 대한 디폴트 값을 지정할 수 있다
# 딕셔너리에 키가 없으면 그 키를 만들어주고 초깃값을 0으로 세팅해 준다
# 따라서, 키가 존재하지 않을 때 키를 추가하는 조건문을 쓰지 않아도 됨!
# 단어를 trie에 추가해준다
# trie[단어길이].insert(단어)
for word in words:
prefix_trie[len(word)-1].insert(word)
# 접미사를 찾기 위해 반전시킨 단어로 trie를 만든다
suffix_trie[len(word)-1].insert(word[::-1])
# query에 맞는 단어를 찾는다
# trie[단어길이].search(단어)
for query in queries:
if query[0] != '?':
answer.append(prefix_trie[len(query)-1].search(query))
else:
answer.append(suffix_trie[len(query)-1].search(query[::-1]))
return answer
정확성과 효율성 모두 만점 받았다
이번 주 스터디 후기 :
실전 코테 문제는 다르구나............
Trie를 새롭게 알게 됐는데 다양한 자료구조를 알고 있어야겠다는 생각이 들었다
