📌K-fold 교차 검증 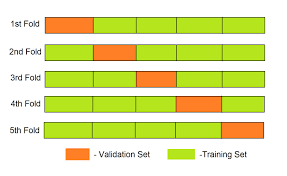
K-Fold 교차 검증은 데이터를 무작위로 k 개의 fold로 나누어, 각각의 fold를 한 번씩 Validation Set, 나머지 fold를 Training Set으로 추출하여 K번 검증하는 방법이다. 이 방법은 모델의 알반화 성능을 평가하기 위해 사용된다.
그러나 다중 클래스 분류 문제에서 클래스 비율이 불균형한 경우에서 각 폴드가 대표적인 샘플들로 이루어져 있지 않고 편향될 가능성이 있다. 만약 전체 데이터 셋의 90%가 양성 레이블을 가지고 있다면 일반적인 K-Fold 교차 검증에서는 각 fold에서 레이블의 분포가 90%, 10%로 나누어지기 때문에 학습셋과 검증셋 모두 음성 레이블이 거의 포함되지 않아 양성 레이블에 편향되게 학습될 가능성이 있다.
해당 코드는 sklearn에서 K-Fold 교차 검증을 구현한 클래스인 KFold 를 사용하여 각 fold에서 학습용, 검증용 데이터의 레이블 분포를 출력한다.
from sklearn.model_selection import KFold
#iris 데이터셋을 데이터 프레임 형태로 변환한다.
kfold_df = pd.DataFrame(data=kfold_iris_data.data, columns = kfold_iris_data.feature_names)
#kfold 객체를 생성하고 n_splits 파라미터를 3개로 지정한다.
kfold_iris = KFold(n_splits = 3)
cnt_iter = 0
#split()함수를 사용해 train_idx, test_idx
for train_idx, test_idx in kfold_iris.split(kfold_df):
cnt_iter += 1
#학습용, 검증용 데이터를 각기 다른 인덱스에 나누어서 저장한다.
label_train = kfold_df['target'].iloc[train_idx]
label_test = kfold_df['target'].iloc[test_idx]
print('교차검증 :{}'.format(cnt_iter))
print('학습 레이블데이터 분포\n', label_train.value_counts())
print('검증 레이블데이터 분포\n', label_test.value_counts())결과는 아래와 같다. 각 교차 검증에서 어떤 레이블은 학습 데이터에 포함되지 않고 검증 데이터에만 포함되므로 학습 데이터와 검증 데이터의 레이블 분포가 크게 다르다고 할 수 있다. 이러한 경우에는 모델의 예측 성능이 실제보다 낙관적으로 평가될 가능성이 있다.
교차검증 :1
학습 레이블데이터 분포
1 50
2 50
Name: target, dtype: int64
검증 레이블데이터 분포
0 50
Name: target, dtype: int64
교차검증 :2
학습 레이블데이터 분포
0 50
2 50
Name: target, dtype: int64
검증 레이블데이터 분포
1 50
Name: target, dtype: int64
교차검증 :3
학습 레이블데이터 분포
0 50
1 50
Name: target, dtype: int64
검증 레이블데이터 분포
2 50
Name: target, dtype: int64📌Stratified kfold
K-Fold와 달리, Stratified k-fold 교차 검증은 각 fold에서 양성, 음성 레이블의 비율이 전체 데이터셋의 비율과 유사하게 유지되므로, 각 폴드가 대표적인 샘플로 이루어지며, 모델이 레이블의 편향을 학습하는 것을 방지할 수 있다.
해당 코드는 sklearn에서 K-StratifiedKFold 교차 검증을 구현한 클래스인 StratifiedKFold 를 사용하여 각 fold에서 학습용, 검증용 데이터의 레이블 분포를 출력한다.
데이터프레임 kfold_df와 kfold_df['target']을 인자로 넣어줌으로써, 클래스 분포를 고려한 StratifiedKFold 를 사용할 수 있다.
from sklearn.model_selection import StratifiedKFold
#stratifiedkfold 객체 생성
skf_iris = StratifiedKFold(n_splits = 3)
cnt_iter = 0
#인자로 데이터프레임 kfold_df와 kfold_df['target']를 넣어준다.
for train_idx, test_idx in skf_iris.split(kfold_df, kfold_df['target']):
cnt_iter += 1
label_train = kfold_df['target'].iloc[train_idx]
label_test = kfold_df['target'].iloc[test_idx]
print('교차검증 :{}'.format(cnt_iter))
print('학습 레이블데이터 분포\n', label_train.value_counts())
print('검증 레이블데이터 분포\n', label_test.value_counts())
결과는 아래와 같다. K-Fold 교차 검증의 결과와 달리 각 교차 검증에서 학습 레이블과 검증 레이블의 분포가 각 클래스별로 모두 비슷한 비율로 구성되어 있다. 이는 StratifiedKFold 교차 검증이 각 클래스의 비율을 고려하여 데이터를 분할했기 때문이라고 볼 수 있다. 따라서 해당 결과에서 데이터는 편향되지 않았다고 볼 수 있다.
교차검증 :1
학습 레이블데이터 분포
2 34
0 33
1 33
Name: target, dtype: int64
검증 레이블데이터 분포
0 17
1 17
2 16
Name: target, dtype: int64
교차검증 :2
학습 레이블데이터 분포
1 34
0 33
2 33
Name: target, dtype: int64
검증 레이블데이터 분포
0 17
2 17
1 16
Name: target, dtype: int64
교차검증 :3
학습 레이블데이터 분포
0 34
1 33
2 33
Name: target, dtype: int64
검증 레이블데이터 분포
1 17
2 17
0 16
Name: target, dtype: int64