File Organization
- Database는 file들의 collection으로 저장되어 있다.
- 각 file들은 records의 sequence이다.
- 하나의 record는 field의 sequence이다.
- record를 tuple, field를 attribute이라고 생각하면 쉽다
- One approach
- Assume record size is fixed
- Each file has records of one particular type only
- Different files are used for different relations
- 위의 경우는 구현하기가 쉽다. (will consider variable length records)
- DB의 검색 성능을 얘기할 때, disk I/O가 적을수록 좋다고 한다.
- disk I/O의 기본 단위는 disk block이고, 이는 여러 개의 tuple들을 저장하고 있다.
- 여러 tuple들을 가져오더라도 모두 하나의 disk block에 있는 튜플들이면, disk I/O = 1
Fixed-Length Records
i번째 record를 n * (i-1) byte부터 시작하도록 저장한다.
(n : size of record)
- record access는 쉽지만, records may cross disk blocks
- disk block size가 140이고, 이미 50짜리 record 두개가 차있으면,
여기에 40만큼 들어가고 다음 block에 10 들어가야 한다 (cross
- disk block size가 140이고, 이미 50짜리 record 두개가 차있으면,
- 이러면 같은 block에 접근할 때 disk I/O가 2가 되므로,
이전 40만큼 공간은 그냥 버리고, 다음 block에 50을 전부 넣는다.
(Do not allow records to cross block boundaries)
- Disk block : a logical unit for storage allocation and retreieval
- Deletion of record i (i번째 record 삭제) - 3가지 방식
- i+1, ..., n번째 record를 i, ..., n-1로 다 내린다.
- 너무 비효율적. disk I/O too much
- n번째 record를 i번째로 옮긴다
- record를 옮기지 말고, free record들을 free list(linked list)로 관리한다
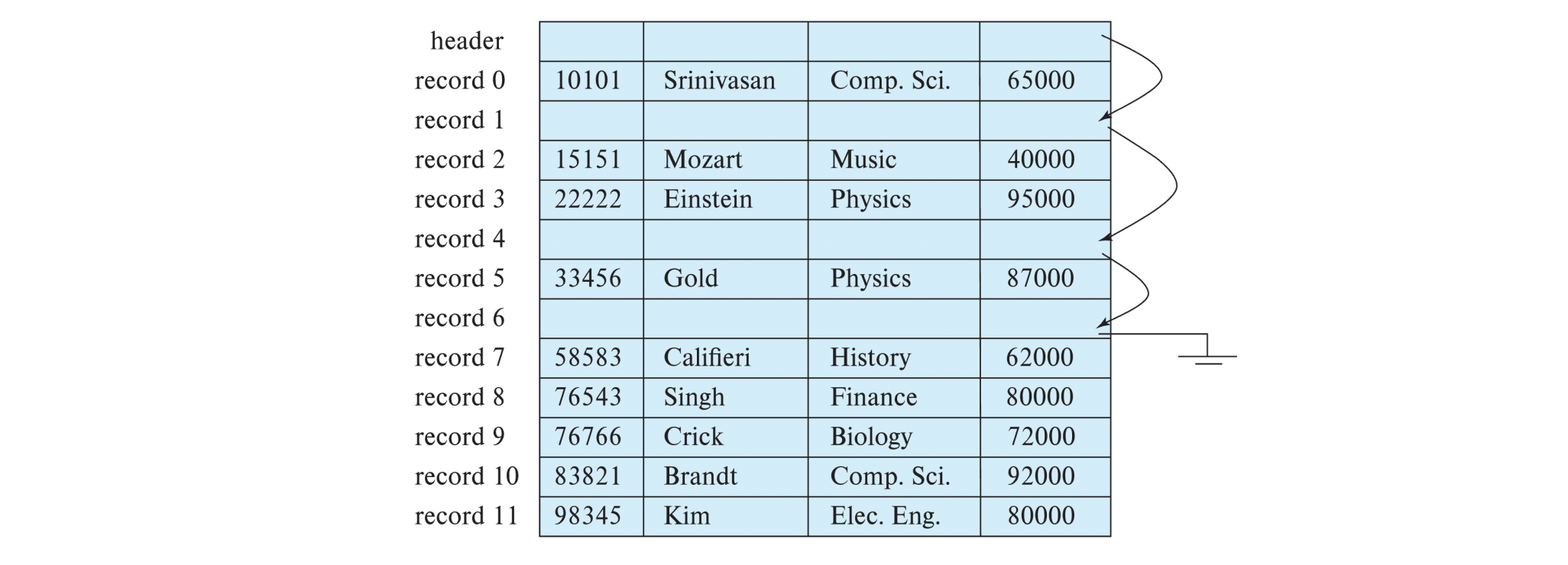
- i+1, ..., n번째 record를 i, ..., n-1로 다 내린다.
Variable-Length Records
- Variable-length record는 db에서 여러 방식으로 나타날 수 있다.
- 한 file에 여러 type의 record 저장
- varchar와 같이 variable length를 지원하는 record type
- Attributes는 순서대로 저장된다. (in order)
- Variable-length attribute는 fixed size(offset, length)와 actual data로 표현된다.
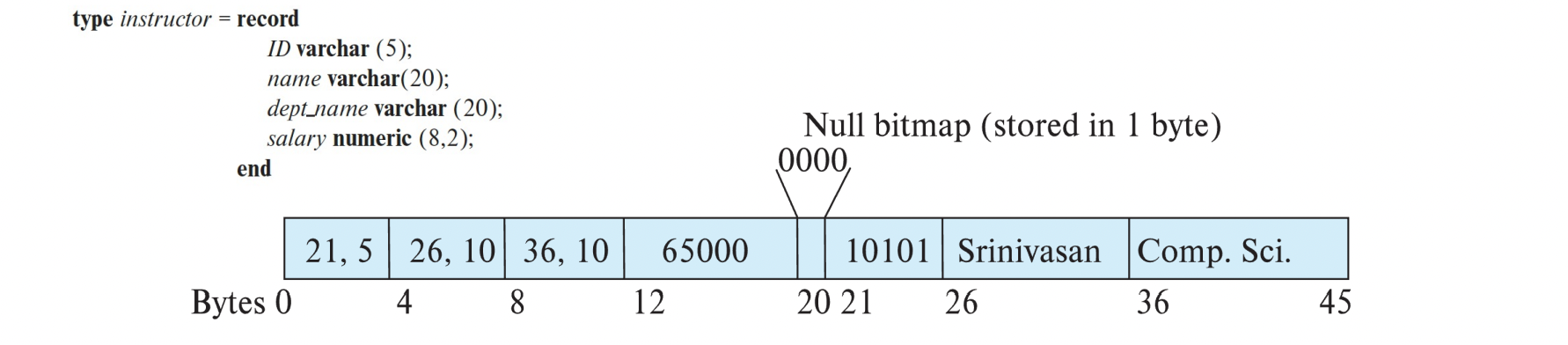
- (21, 5) : 21 위치로 가서 5만큼 읽어라
(26, 10) : 26 위치로 가서 10만큼 읽어라 - (21, 5) (26, 5) (26, 10) 저장하는 4 byte는 고정이다.
- numeric(8, 2)는 fixed size이므로, 실제 값만 저장한다.
- Null bitmap은 각각이 null인지를 알려준다 (0 : not null, 1 : null)
- 지금은 attribute이 4개라서 1 byte ( = 8 bits) 사용했지만,
개수가 늘어나면 그 이상으로 필요할 수 있다. (10개 -> 2 byte)
- 지금은 attribute이 4개라서 1 byte ( = 8 bits) 사용했지만,
- (21, 5) : 21 위치로 가서 5만큼 읽어라
Slotted Page Structure
page == block 이라고 이해하자
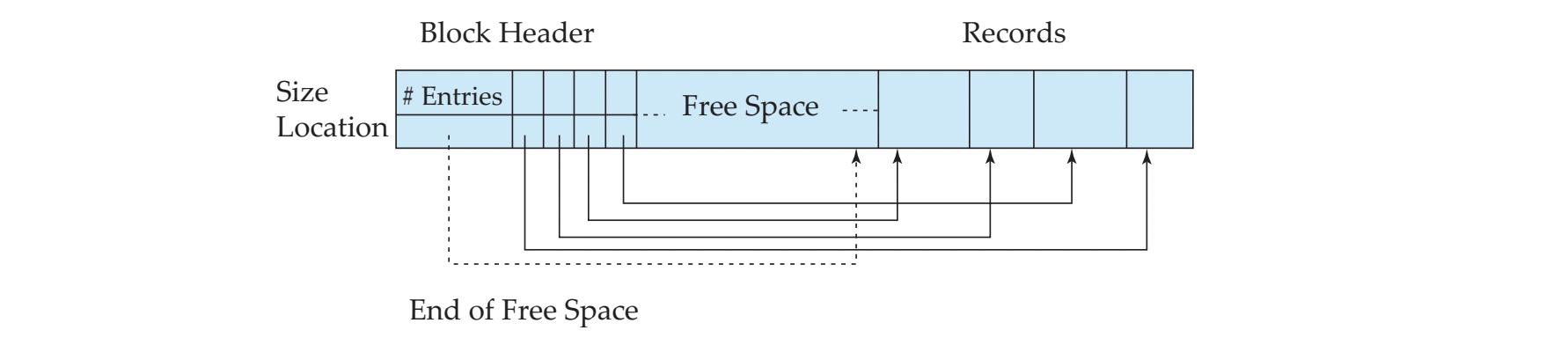
- block header와 record 사이에 free space를 두고, record는 맨 끝에서부터 저장된다.
- Slotted page (i.e., block) header contains :
- number of record entries
- end of free space in the block
- location and size of each record
- 만약 record가 삭제되면, 그걸 나타내는 entry도 삭제되어야 한다.
- 또한, record들 사이에 빈 공간이 없게끔 오른쪽으로 밀어준다.
(entry in header must be updated)
- 어떤 응용 프로그램이 record의 주소를 direct하게 pointing하지 못한다
반드시 header에 있는 그 record의 entry를 pointing하고 넘어가야 한다- 만약 direct하게 연결되어 있으면?
삭제할 때마다 주소가 바뀌기 때문에 invalid access가 될 수가 있다.
- 만약 direct하게 연결되어 있으면?
Storing Large Object
e.g.) blob/clob types (binary large objects / character large objects)
- record는 page보다 작아야 하기 때문에, 3가지 방법이 있다.
- Store as files in file system (그냥 file로 저장한다)
- Store as files managed by database (db engine이 관리하게 한다)
- Break into pieces and store in multiple tuples in separate relation (별도 relation에 여러 tuple로 저장한다)
Organization of Records in Files
Heap
- 공간(free space)만 있으면 record가 file의 어디든 위치할 수 있다
- 한 번 할당하면, record는 움직이지 않는다
- file 내에서 free space를 efficiently 찾을 수 있게 하는게 중요하다
Free-space map
- block당 1개의 entry가 있는 array
- 각 entry는 몇 bits ~ 1 byte, free한 block의 개수

- 각 block에는 3bits가 들어가고(0~ 7),
각 숫자는 block에서 free한 fraction의 개수를 의미한다. - 만약 block size가 512 bytes이고, 8 partition이 있다면,
각 partition의 size는 512/8 = 64 bytes이다. - 즉, 첫 번째 entry (4)는
64 * 4 bytes 만큼의 공간이 free하다는 것을 의미한다.
- 각 block에는 3bits가 들어가고(0~ 7),
- Second-level free-space map도 만들 수 있다.
- first-level free-space map의 4 entry 중 최댓값을 가져온다

- first-level free-space map의 4 entry 중 최댓값을 가져온다
- Free space map written to disk periodically,
OK to have wrong (old) values for some entries.
(금방 deteced and fixed)
Sequential File Organization
- 전체 file(entire file)을 sequential하게 processing해야 하는 작업에 적합하다.
- record들은 file 내에서 search key에 대해 정렬되어 있다.
- 이때, search key가 반드시 primary key일 필요는 없다.
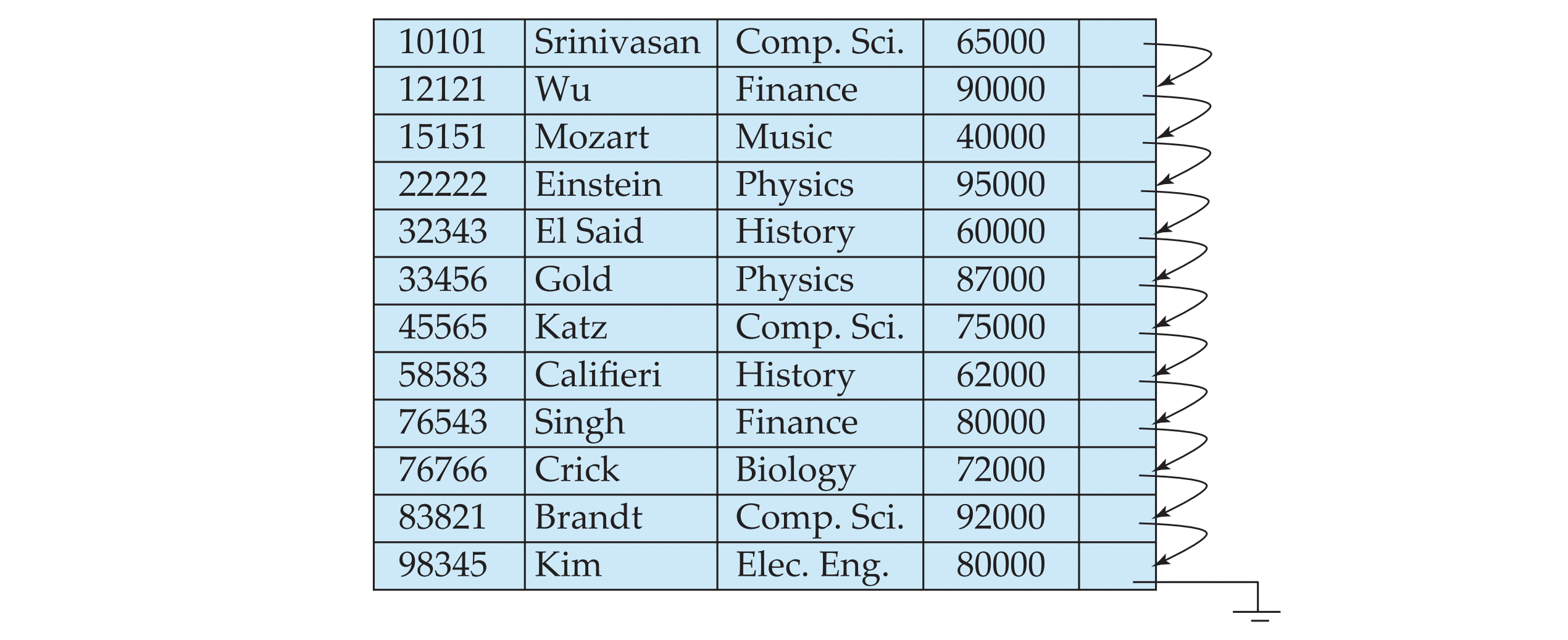
- 이때, search key가 반드시 primary key일 필요는 없다.
Deletion
- use pointer chains
Insertion
- 먼저, 삽입해야 하는 위치를 확인한다
- free space가 있으면, insert there
- free space가 없으면, overflow block을 insert한다.
- 두 case 모두, pointer chain이 update되어야 한다.
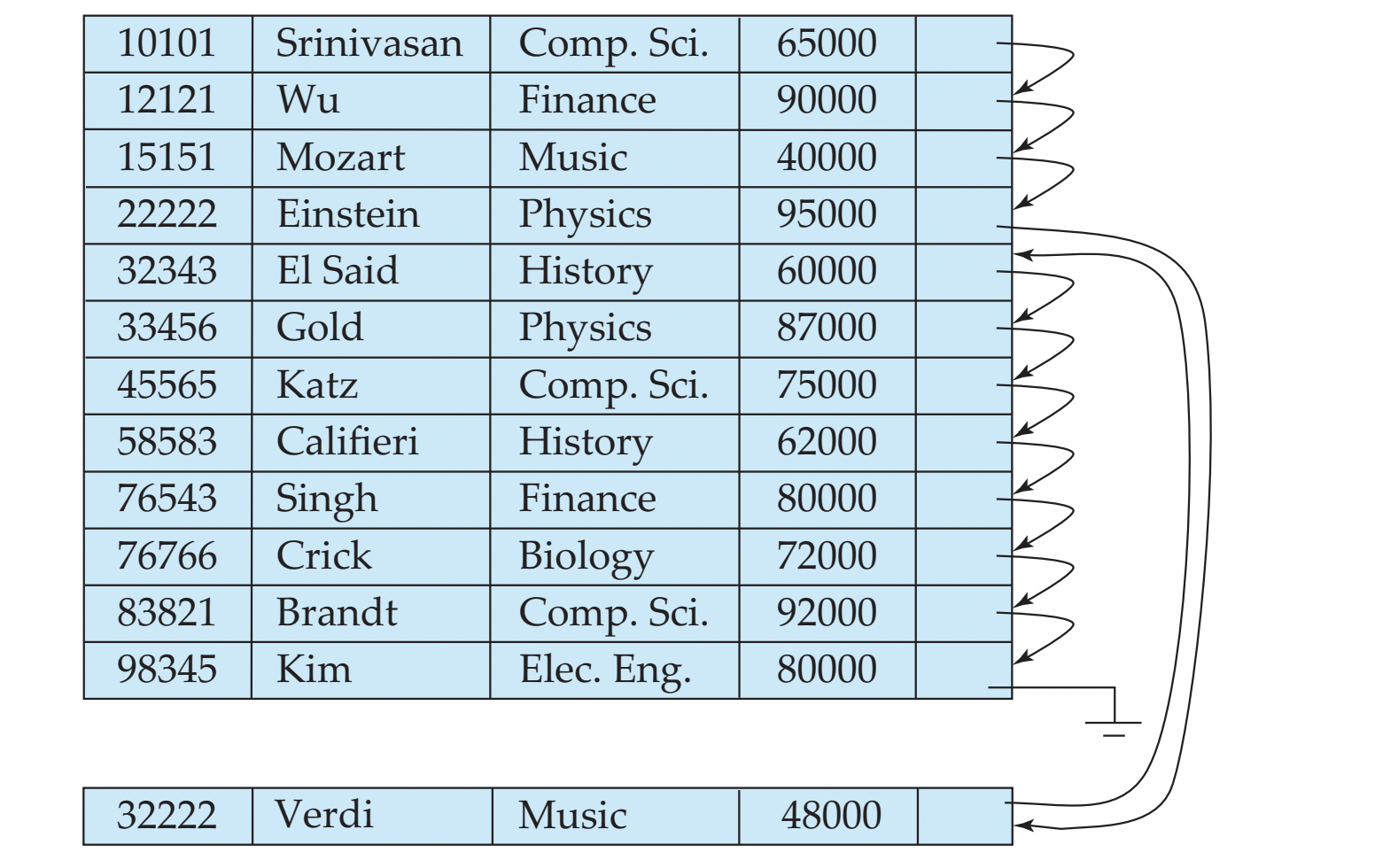
- sequential order를 맞춰주기 위해, 주기적으로 file을 reorganize해줘야 한다.
Multitable Clustering File Organization
- multitable clustering file organization을 이용해서
여러 relation을 하나의 file에 저장한다 - 원래 두 개의 file에 저장하면 되지만,
만약 두 개를 같이 부르는 query가 빈번하게 발생한다면
매번 disk I/O를 두 번씩이나 쓰는 건 낭비이다. - multitable clustering을 쓰면
block을 하나만 가져오면 되기 때문에 disk I/O = 1이 된다.
- cluster key : the attribute that defines which records are stored together
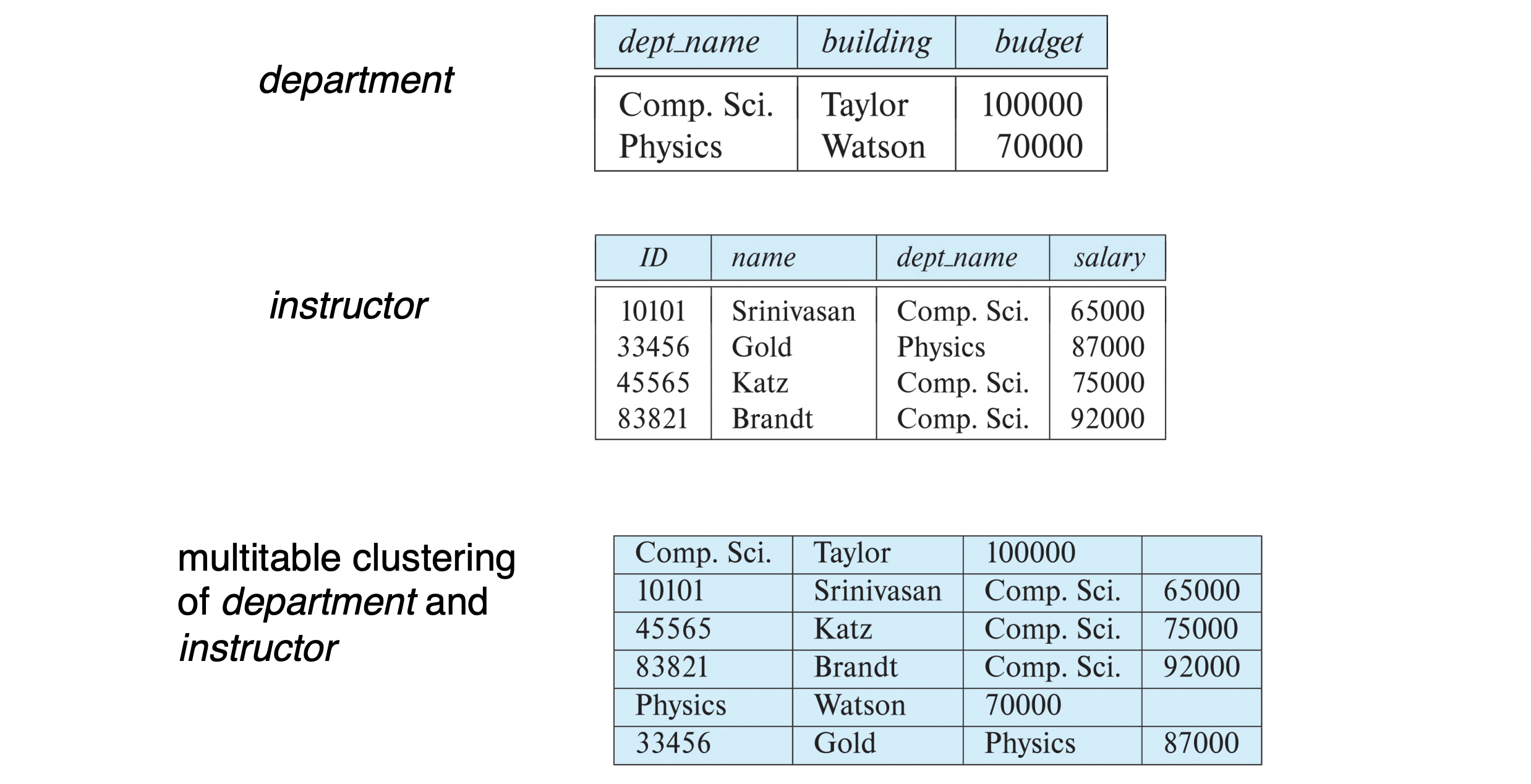
- cluster key is dept_name
Partitioning
Table partitioning
- relation의 record들을 작은 relation으로 분할해서 각자 저장한다
- ex). trasaction relation을 다음과 같이 분할한다 :
transaction_2018, transaction_2019, transaction_2020, ...
- 사용자에게는 transaction 하나로만 보이지만, 실제 디비에는 이런 방식으로 저장된다.
- 만약 query에서 year = 2019로 selection하면, 하나의 partition만 필요하다.
장점
- free space management와 같은 operation의 비용이 줄어든다
- 다른 partition들이 서로 다른 device에 저장될 수 있다.
- 최근 transaction -> SSD, 예전 transaction -> Magnetic disk
Data Dictionary Storage
- metadata를 저장한다. that is, data about data
- Information about relation
- relation 이름
- 각 relation의 속성의 이름, type, 길이
- view의 이름, 정의
- integrity contraints
- password를 포함한 유저 및 계정 정보
- statistical and descriptive data
- 각 relation의 tuple 개수
- physical file organization information
- relation이 어떻게 저장되어 있는지 (Sequential, Hash, ...)
- relation이 실제 어디에 저장되어 있는지 (physical location of relation)
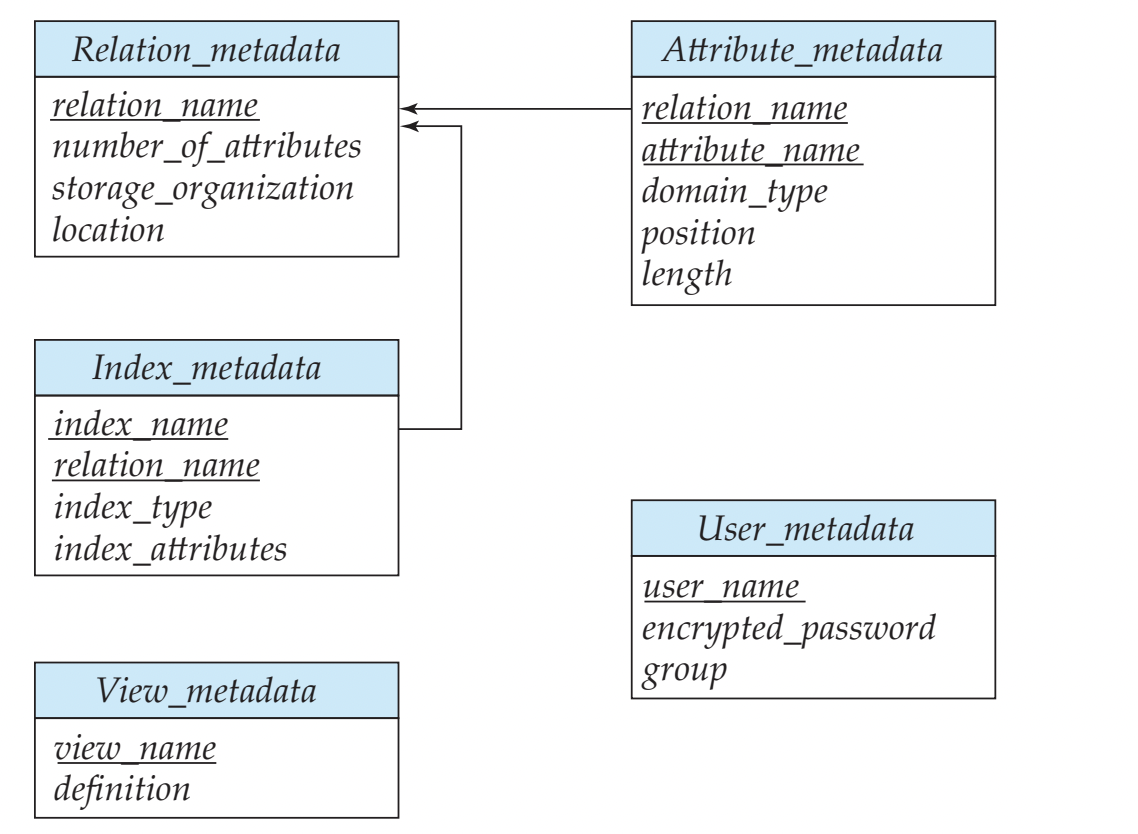
Storage Access
- Blocks are units of both storage allocation and data transfer
- DB는 disk와 memory 사이의 number of block transfer를 최소화하려고 한다.
Main memory에 최대한 block을 많이 저장하면, number of disk accesses를 줄일 수 있다.
-
Buffer : portion of main memeory
available to store copies of disk blocks -
Buffer manager : subsystem responsible for
allocating buffer space in main memory
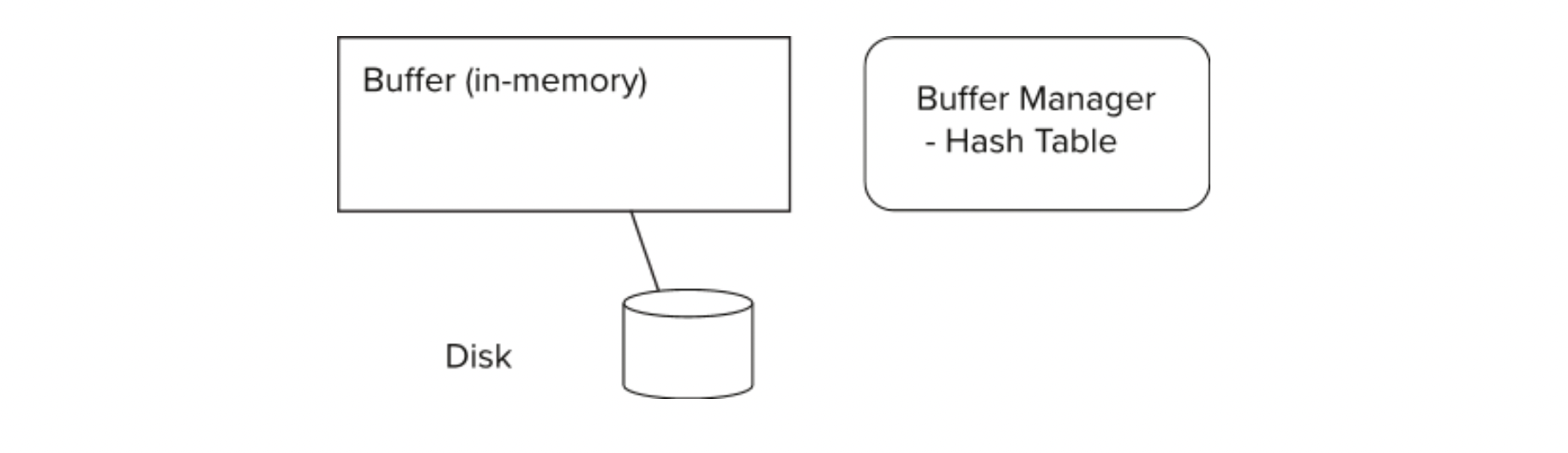
Buffer Manager
- 프로그램은 disk의 block이 필요할 때, buffer manager를 부른다.
- 만약 block이 buffer에 이미 있다면,
buffer manager는 main memory의 block의 주소를 리턴한다
- 만약 block이 buffer에 없다면,
buffer manager는 block을 위한 buffer 내의 공간을 확보한다- 필요하다면 replacing(throwing out) some other block
to make space for the new block - replaced block이 만약 disk로부터 fetch된 이후에 수정되었으면, disk로 다시 written back
- 이후 disk의 block을 buffer에 읽어오고,
main memory의 block의 주소를 리턴한다
- 필요하다면 replacing(throwing out) some other block
Pinned block (찜)
- memory block that is NOT allowed to be written back to disk
- read/write data from a block 전에, Pin done
- read/write가 끝나면, Unpin done
- Multiple concurrent pin/unpin operations possible
- pin count를 계속 갖고 있어서, pin count = 0일 때만,
buffer block이 evict될 수 있다. (block replace) - pin count를 보고 현재 몇 개가 read하고 있는지 확인할 수 있다.
- pin count를 계속 갖고 있어서, pin count = 0일 때만,
Shared and exclusive locks on buffer
- 얘네가 moved/reorganized될 때는,
reading page content가 동시에 일어나는 걸 막을 필요가 있다.
이를 통해 ensure only one move/reorganize at a time - shared는 pin count ≥ 2일 때도 가능하다.
- write(update)할 때에는 exculive lock을 걸고 해야 한다 (pin count = 1)
- Locking Rules :
- Only one process can get exclusive lock at a time
- Shared lock cannot be concurrently with exclusive lock
- Multiple process may be given shared lock concurrently
Buffer-Replacement Pollicies
- 대부분의 OS에서는 LRU(least recently used) 사용
- "use past pattern of block references as a predictor of future references"
- Query는 well-defined access pattern을 갖는다. (such as sequential scans)
DB는 user의 query를 보고, future references를 예측한다.
즉, 어떤 block을 keep하고 내보내야 하는지 결정한다
- Toss-immediate strategy : frees the space occupied by a block as soon as the final tuple of that block has been processed
- MRU (Most recently used strategy) : system must pin the block currently being processed. After the final tuple of that block has been processed, the block is unpinned, and it becomes the most recently used block.
- 이중 loop이 걸려 있을 때,
(for each tuple in instructor do)
(for each tuple in department do) - 버퍼에는 [inst_block 1, dept_block 1, dept_block 2, ...] 이렇게 들어올 거다.
- LRU인 경우와 MRU인 경우를 비교해보자
- in LRU,
버퍼가 꽉 찬 경우, dept_block 1이 나가고 dept_block 4가 들어온다.
문제는, inst_block 1의 다음 tuple로 넘어가면 곧바로 dept_block 1이 필요하게 된다. - in MRU,
버퍼가 꽉 찬 경우, 가장 최근에 사용한 dept_block 3가 나간다
inst_block 1은 마지막 tuple에 대해 작업 끝냈으면 바로 없애준다.
- in LRU,
- 이중 loop이 걸려 있을 때,
Optimization of Disk Block
Log Disk
- a disk devoted to writing a sequential log of block updates
- Writing to log disk is very fast since no seeks are required
- 그니까, update할 내용을 log에 먼저 다 써두고, write를 시작한다.
disk에 쓰다가 system이 죽으면, log를 사용한다
Column-Oriented Storage
-
여태까지 공부한건 모두 row-oriented.
-
Also known as columnar representation
-
Store each attribute of a relation seperately
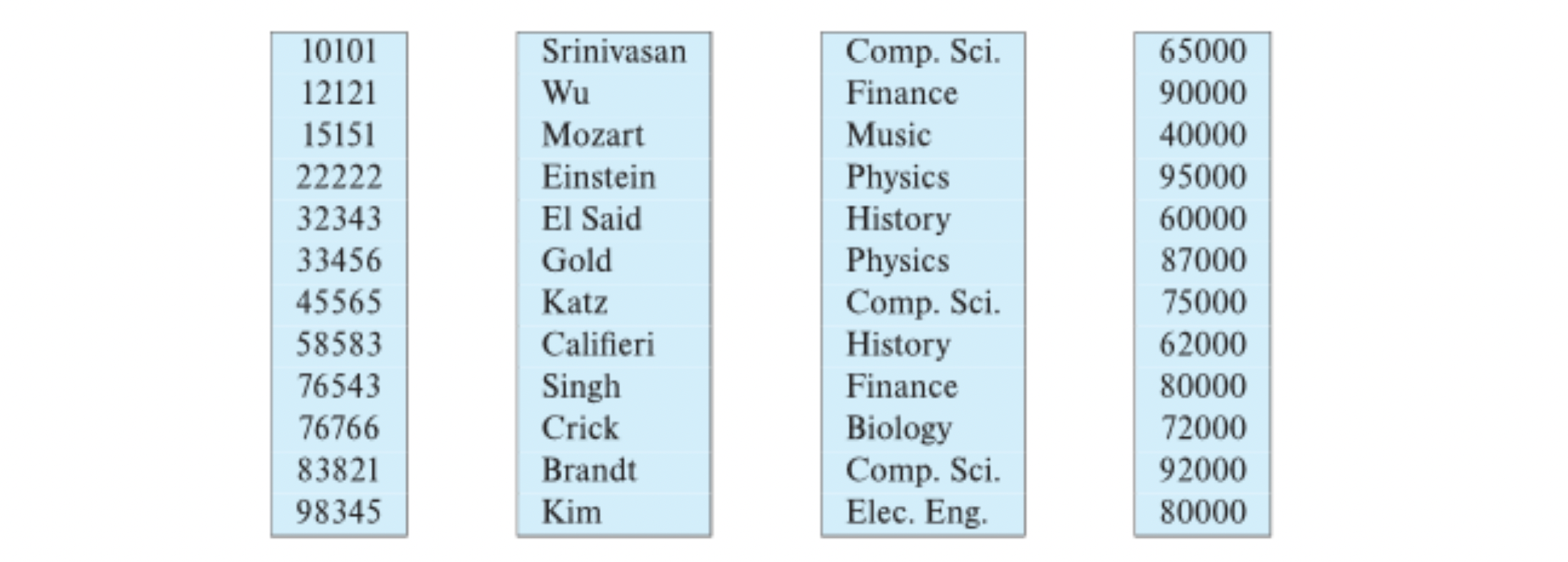
- 평균 구하기 좋겠당 (disk I/O 최소화)
-
decision support에는 columnar representation이 좋다
-
transaction processing에는 row-oriented가 좋다
장
- I/O를 줄일 수 있는 경우가 있다
- CPU cache 성능을 올려준다
- 비슷한 유형이 많기 때문에 압축률이 올라간다
- Vector processing(??) on modern CPU architectures
단
- tuple 재구성하는 cost가 세다
- tuple deletion, update에 cost가 세다
- 압축 cost도...
ORC (Optimized Row Columnar)
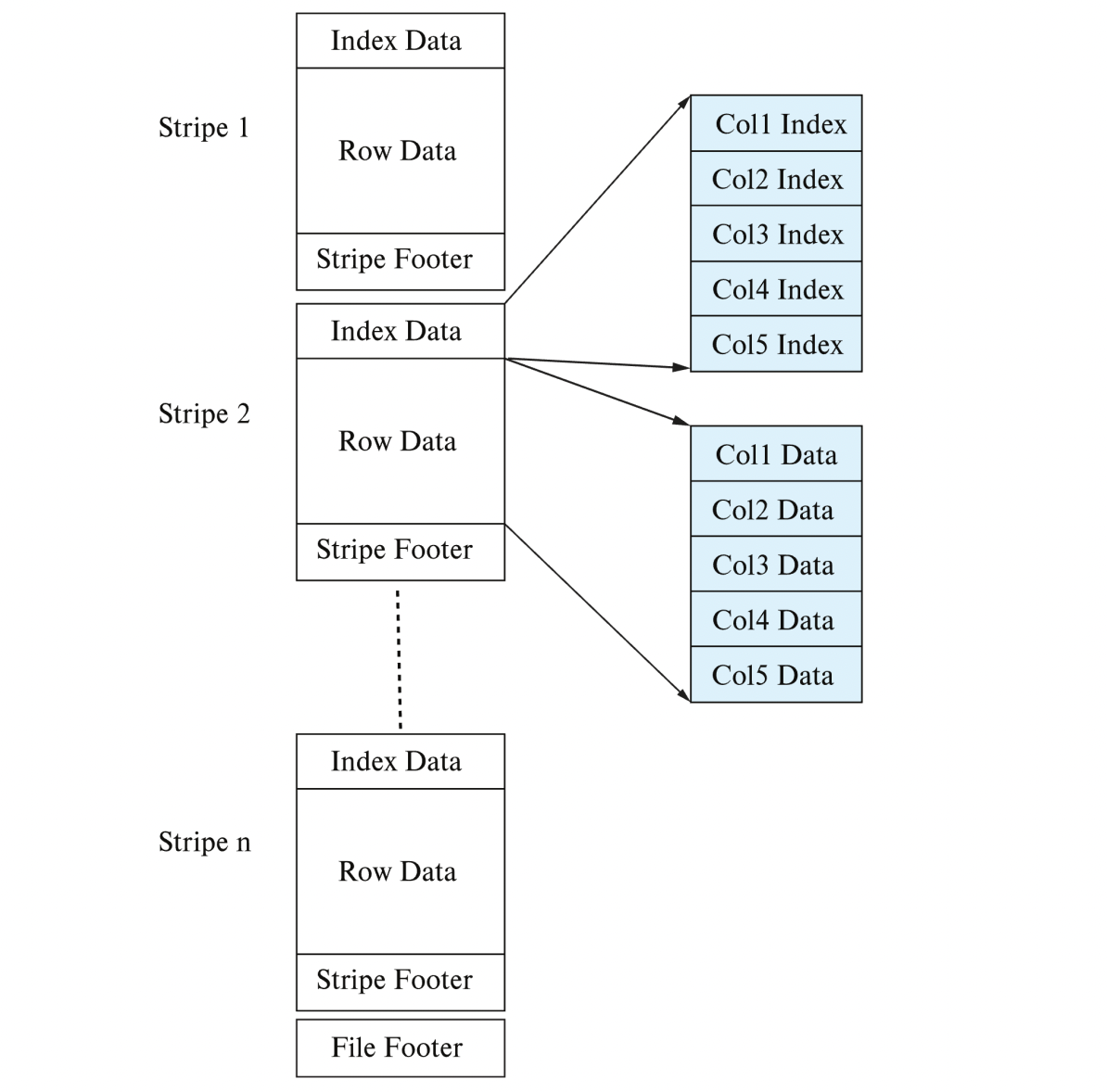
- data의 위치(시작, 끝)을 index에 저장한다.
- 각 stripe는 특정 tuple의 group을 의미한다.
