
JOIN
- 여러 테이블에서 가져온 레코드를 조합하여 하나의 테이블이나 결과 집합으로 표현
- 크게는 INNER JOIN, OUTER JOIN으로 구분
INNER JOIN
- 두 테이블 사이에 지정된 조건에 맞는 레코드만을 반환. 양쪽 테이블에 모두 해당 조건에 맞는 값이 있어야 결과에 포함
ex) author와 post를 inner 조인하면 글을 작성한 적이 있는 author와 해당 author가 작성한 post정보를 결합하여 조회
- 가장 일반적인 형태
- table의 ID와 table의 a_id가 일치하는 ON 조건을 만족하는 데이터만 JOIN
- SELECT * FROM tableA INNER JOIN tableB ON tableA.ID = tableB.A_ID
- SELECT * FROM tableA AS a INNER JOIN tableB AS b on a.ID = b.a_id;
- 출력 결과
-
TableA의 모든컬럼 + TableB의 모든 컬럼
-
그 중에 ON조건을 만족하는 row만 출력
SELECT FROM tableA INNER JOIN tableB ON tableA.ID = tableB.A_ID
SELECT FROM tableA AS a INNER JOIN tableB AS b on a.ID = b.a_id;
- 출력결과
- TableA의 모든컬럼 + TableB의 모든컬럼
- 그 중에 ON조건을 만족하는 row만 출력
OUTER JOIN
- 하나의 테이블을 기준으로 모든 레코드와 그에 JOIN된 다른 테이블의 일치하는 레코드를 반환
- 왼쪽 테이블이 기준이면 LEFT(OUTER) JOIN, 오른쪽 기준이면 RIGHT(OUTER) JOIN
- LEFT JOIN이 더 일반적으로 많이 사용되는 JOIN
ex) author의 테이블은 일단 다 조회하고 author가 작성한 글정보를 조회하고 싶다면, author테이블에 post테이블을 left join
- LEFT OUTER JOIN
- 문법
SELECT * FROM tableA a LEFT JOIN tableB b ON a.id = b.a_id
- 문법

- 출력결과
- TableA의 모든컬럼 + TableB의 모든컬럼
- A테이블 데이터는 row는 모두 출력 B데이터는 ON 조건에 맞는 데이터만 출력
- ON조건에 맞지 않는 B데이터는 null로 출력
- A테이블의 데이터를 기준으로 B테이블의 데이터를 정렬
JOIN 특이사항
- JOIN된 데이터에 WHERE조건
- where조건을 걸게 되면, ON 조건을 만족하는 데이터중에서도 WHERE문을 만족하는 데이터만 출력
SELECT * FROM tableA AS a INNER JOIN tableB AS b on a.ID = b.a_id where a.name like ‘kim%’;
- where조건을 걸게 되면, ON 조건을 만족하는 데이터중에서도 WHERE문을 만족하는 데이터만 출력
- RIGHT JOIN의 경우 LEFT JOIN과 동일
- 다만, 기준이 되는 테이블이 왼쪽 테이블에서 오른쪽으로 변경
UNION
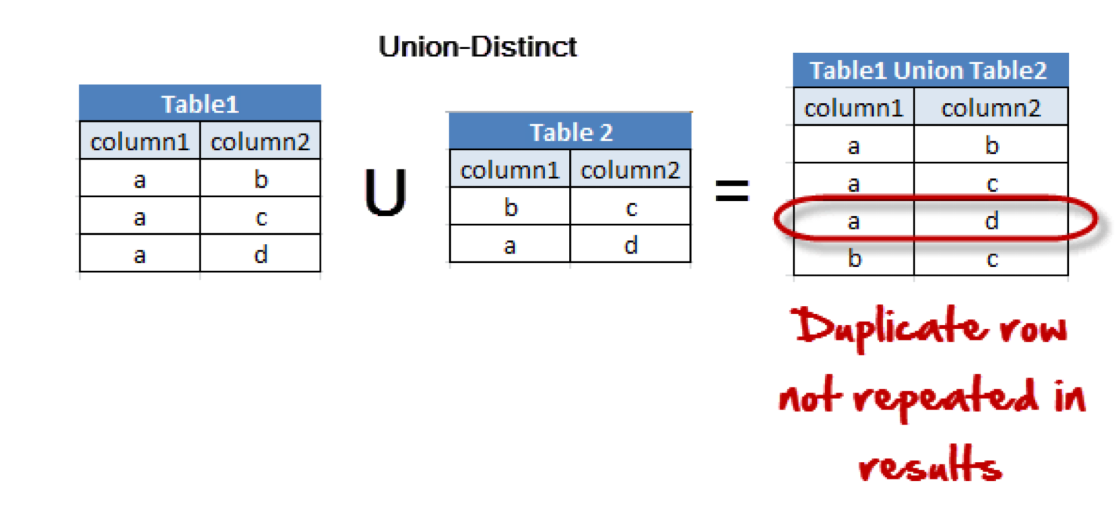
-
여러 개의 SELECT문의 결과를 하나의 테이블이나 결과 집합으로 표현
-
각각의 SELECT 문으로 선택된 필드의 개수와 타입은 모두 일치해야함
-
UNION은 DISTINCT 키워드를 따로 명시하지 않아도 중복되는 레코드를 제거
- 중복되는 레코드까지 모두 출력하고 싶다면 UNION ALL
SELECT 컬럼1, 컬럼2 FROM TABLE1 UNION SELECT 컬럼1, 컬럼2 FROM TABLE2;
UNION - WITH RECURSIVE
-
WITH RECURSIVE 키워드는 sql에서 재귀문으로서 자기 자신을 참조하여 반복적으로 데이터를 생성하거나 변형하면서 하나의 테이블을 만드는 용도로 사용
-
UNION과 함께 사용되며 데이터행을 더해나가는 방식
-
WITH RECURSIVE 재귀문에서 WHERE 절은 재귀적으로 생성되는 각각의 행에 대해 평가되며, 조건이 거짓이 되는 순간 더 이상 새로운 행을 생성하지 않고, 전체 재귀문이 STOP
예시)
0~10까지 출력
WITH RECURSIVE cte(cnt) AS (
SELECT 0
UNION ALL
SELECT cnt + 1 FROM cte WHERE cnt < 10
)
SELECT cnt FROM cte;- 예시)피보나치 수열
WITH RECURSIVE Fibonacci (n, fib1, fib2) AS (
SELECT 1, 0, 1 -- 초기 값 설정
UNION ALL
SELECT n + 1, fib2, fib1 + fib2 FROM Fibonacci WHERE n < 10 -- 재귀 단계
)
SELECT n, fib1 FROM Fibonacci;
- 예시)피보나치 수열
서브쿼리
- 서브쿼리(subquery)란 다른 쿼리 내부에 포함되어 있는 SELECT문을 의미
- JOIN대신 서브쿼리를 써보자
- SELECT a.* FROM author a INNER JOIN post p ON a.id = p.author_id;
- SELECT a.* FROM author a WHERE a.ID IN (SELECT p.author_id FROM post p);
- IN과 NOT IN을 많이 사용
- SELECT * FROM tableA WHERE id IN (SELECT a_id FROM tableB);
- 서브쿼리는 반드시 괄호(())로 감싸져 있어야 한다
- 대부분의 서브쿼리는 join으로 대체가능하고 join을 쓰는것이 성능이 더 좋음
- 단, 매우 복잡한 쿼리는 join으로 대체하는 것이 불가능
GROUP BY
- 선택된 레코드의 집합을 특정 값으로 그룹화한 결과 집합
SELECT 컬럼명 FROM 테이블명 GROUP BY 컬럼명
- 사용목적
- 데이터의 값을 집계하기 위해
- 주로 집계 함수와 같이 사용(total sum, average 등)
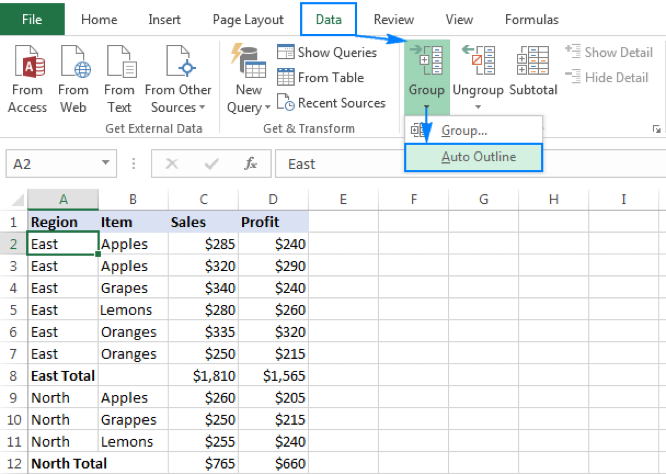
- 아래 excel의 경우 Region을 group화 시켜 통계값 산출
집계함수
- COUNT() : 행의 개수를 세어줌
- AVG() : 행 안에 있는 값의 평균을 내어줌
- MIN() : 행 안에 있는 값의 최솟값을 반환해줌
- MAX() : 행 안에 있는 값의 최댓값을 반환해줌
- SUM() : 행 안에 있는 값의 합을 내어줌
예시)
SELECT author_id, COUNT(*) FROM post GROUP BY author_id
- author_id로 그룹화한 데이터의 갯수구하는 집계 SQL
만약 post마다 원고료가 있었다면
SELECT author_id, SUM(price), AVG(price) FROM post GROUP BY author_id
WITH - RECURSIVE
- WITH RECURSIVE
WITH RECUTSIVE number_sequence(HOUR) AS (
SELECT 0
UNION ALL
SELECT HOUR + 1 FROM number_sequence WHERE HOUR < 23
)
WHERE 문의 재귀함수의 종료조건을 쓴다.
HAVING 절
- HAVING 절은 GROUP BY를 사용하여 그룹화된 후의 데이터에 대한 조건을 설정
- WHERE 절은 데이터를 그룹화하기 전의 개별 레코드에 대한 조건을 설정
- HAVING 절은 주로 집계 함수(COUNT(), SUM(), AVG() 등)와 함께 특정 조건을 만족하는 그룹만을 필터링하고 싶을 때 사용
SELECT author_id, COUNT(*) AS count FROM post GROUP BY author_id HAVING count > 3;
INDEX
- 인덱스(index)란?
- 인덱스는 색인과 목차처럼 데이터 검색 속도를 향상시키는데 사용
- DB는 해당 인덱스를 활용하여 테이블의 전체 레코드를 스캔하지 않고도 필요한 데이터를 빠르게 찾는다.
- 기본적으로 DB는 데이터를 검색할 때 테이블 전체를 탐색해야 한다.
- 인덱스를 사용하면 테이블의 특정 컬럼 값과 그 레코드의 위치 정보를 보유하고 있어, 테이블 전체를 읽지 않아도 돼 성능 향상
- 일반적으로 인덱스는 B-tree의 자료구조를 가지고, 이는 이진 트리를 확장한 형태로,
한 노드가 두 개 이상의 자식을 가질 수 있는 자료구조- 이진트리는 최대 2개의 자식 노드를 가지는 구조.
- 모두 2개의 자식노드만을 가진 이진트리를 완전이진트리라 부른다.
-
결론은, 테이블의 특정 컬럼의 INDEX 정보를 만들어 검색의 속도를 높이기 위해서 사용
예시)
특정컬럼에 index가 없이 테이블 전체를 읽어야 하는 case
id=897 번째의 데이터를 조회하기 위해서는 897번의 check가 필요
예시)
id 컬럼에 대해 index가 만들어져 있어, 성능이 향상되는 case

- root페이지는 100개당 1개씩 branch를 갖는 구조
- branch는 10개당 1개씩 leaf를 갖는 구조
- id=897 번째의 데이터를 조회한다면 root에서8번, 그 다음 branch에서 9번, 그 다음 leaf에서 7번, 24번만에 검색완료
- 특정 테이블에 생성된 index 조회
show index from 테이블명;
인덱스 생성 방법
- pk, fk, unique 제약조건 추가시에 해당컬럼에 대해 index 자동생성
- 단일 컬럼 index
CREATE INDEX index_name ON 테이블명(컬럼명);
-
복합(다중 컬럼) 인덱스 생성
CREATE INDEX index_name ON 테이블명(컬럼1, 컬럼2);
- 다중컬럼으로 인덱스를 생성할 때, 컬럼의 순서에 따라 인덱스 테이블이 정렬되니 생성할 때, 충분히 고려하고 생성해야한다.
- 보통 Cardinality(카디널리티)가 높은걸 먼저 두는 것이 좋다.
인덱스의 사용
- 인덱스 정보를 활용하여 검색이 되려면, 조회 where 조건에 index 컬럼을 조건으로 걸어줘야 index페이지를 활용하여 검색이 이루어짐
select * from author where id = 1;
select * from author where id = 1 and name = ‘abc’;
- 이경우, name에 index가 없다면 id인덱스 페이지를 참조
- name에도 별도로 Index가 있다면, MariaDB엔진에서 최적의 알고리즘 실행
- id, name에 동시에 index가 걸려있다면 해당 index 참조하여 검색
