
DISCLAIMER
이번 게시글은 개인사정으로 인해 금주 중 전면 재개편될 예정입니다. 게시글의 개선은 아래와 같이 이루어질 예정입니다.
- DDD를 통한 파이썬 웹 애플리케이션 설계 및 구현 연재글 배포
- 1을 쿠버네티스 클러스터에서 GitOps 플로우를 통해 배포하는 게시글을 3주차 내용과 함께 보강
- PLG 스택을 사용한 상기 클러스터 모니터링 내용 업데이트 (본문내용 업데이트 포함)
들어가며
이 내용은 CloudNet@ 에서 진행하는 쿠버네티스 실무 실습 스터디에 대한 연재글입니다.
스터디에서 사용하는 교재는 24단계 실습으로 정복하는 쿠버네티스 입니다.
본 3주차에는 교재의 제 3부 내용을 살펴보고 있습니다. 전체 컨텍스트를 이해하시려면 교재를 참고하시기를 추천드립니다.
Prerequisites
쿠버네티스를 클라우드 환경에서 사용하고자 하는 것 자체가 이미 하기 사항들에 대한 기본적인 이해와 준비사항을 요합니다.
이번 연재글에서는 개념에 대한 상세한 추가설명은 가급적 없이 작성하려 합니다. 다만 제가 공부하며 기본적으로 알아야겠다 싶은 연재글에 대해 대신 소개드립니다.
들어가며
사전 준비사항 (1)
- AWS Free Tier 계정(비용문제로 인해 필요합니다!)
- IAM User 생성 후 권한 부여
- 학습을 위해 자신의 작업환경 IP에서만 접근할 수 있도록 하고, 관리자 권한을 주는 식으로 해결해도 좋습니다.
- Route 53 퍼블릭 호스팅 영역
- 혹은 도메인 구매사이트에서 도메인 구매 후, Route 53 설정 지정하기
사전 준비사항 (2)
주의! 비용이 많이 발생할 수 있으니, 빠르게 실습 후 종료하시기를 권장드립니다.
- 마스터노드
c5a.2xlarge - 워커노드
c5a.2xlarge - kOps 커맨드를 수행할 인스턴스
t3.small
아래 커맨드를 통해 배포하여 주십시오.
설치과정
# YAML 파일 다운로드
curl -O https://s3.ap-northeast-2.amazonaws.com/cloudformation.cloudneta.net/K8S/kops-oneclick-f1.yaml
# CloudFormation 스택 배포 : 노드 인스턴스 타입 변경 - MasterNodeInstanceType=t3.medium WorkerNodeInstanceType=c5a.2xlarge
aws cloudformation deploy \
--template-file kops-oneclick-f1.yaml \
--stack-name mykops \
--parameter-overrides \
KeyName=kp-gasida \
SgIngressSshCidr=$(curl -s ipinfo.io/ip)/32 \
MyIamUserAccessKeyID=AKIA5... \
MyIamUserSecretAccessKey='CVNa2...' \
ClusterBaseName='gasida.link' \
S3StateStore='gasida-k8s-s3' \
MasterNodeInstanceType=c5a.2xlarge \
WorkerNodeInstanceType=c5a.2xlarge \
--region ap-northeast-2
# CloudFormation 스택 배포 완료 후 kOps EC2 IP 출력
aws cloudformation describe-stacks \
--stack-name mykops \
--query 'Stacks[*].Outputs[0].OutputValue' \
--output text
# 13분 후 작업 SSH 접속
ssh -i ~/.ssh/kp-gasida.pem ec2-user@$(aws cloudformation describe-stacks --stack-name mykops --query 'Stacks[*].Outputs[0].OutputValue' --output text)
# EC2 instance profiles 에 IAM Policy 추가(attach) : 처음 입력 시 적용이 잘 안될 경우 다시 한번 더 입력 하자! - IAM Role에서 새로고침 먼저 확인!
aws iam attach-role-policy \
--policy-arn arn:aws:iam::$ACCOUNT_ID:policy/AWSLoadBalancerControllerIAMPolicy \
--role-name masters.$KOPS_CLUSTER_NAME
aws iam attach-role-policy \
--policy-arn arn:aws:iam::$ACCOUNT_ID:policy/AWSLoadBalancerControllerIAMPolicy \
--role-name nodes.$KOPS_CLUSTER_NAME설치 후 점검
아래 커맨드를 수행하여 배포가 잘 되었는지 확인하여 주십시오.
# 메트릭 서버 확인 : 메트릭은 15초 간격으로 cAdvisor를 통하여 가져옴
kubectl get pod -n kube-system -l k8s-app=metrics-server
kubectl get apiservices |egrep '(AVAILABLE|metrics)'
# 노드 메트릭 확인
kubectl top node
# 파드 메트릭 확인
kubectl top pod -A
kubectl top pod -n kube-system --sort-by='cpu'
kubectl top pod -n kube-system --sort-by='memory'명령어 기반 쿠버네티스 모니터링 도구
모니터링?
작은 회사에서 프로그램을 사용하여 운영하기만 해도 십수개의 컨테이너는 기본적으로 작동합니다. 언제, 어디서 어떻게 작동되고 있는지를 알고있어야 '안전한' 시스템이라 할 수 있겠습니다. 그렇다면 안전한 시스템인지는 어떤 요소들로 파악할 수 있을까요?
메트릭
metrics
Definitions from Oxford Languages
- a method of measuring something, or the results obtained from this.
측정방안 혹은 측정방안을 통해 도출해낸 결과라는 뜻입니다. 그렇다면 소프트웨어 공학에서는 시스템이 얼마만큼의 리소스를 사용중인지를 측정하는 지표라고 볼 수 있겠네요. 주기적으로 수집한다면 그래프화 할 수 있을 것이고 그리면 추이를 알 수 있겠지요. 이러한 요소들로 시스템을 판별할 수 있겠습니다.
또한 쿠버네티스 환경으로 넘어오면서 더더욱 클러스터의 덩치가 쉽게 커질 수 있게 되었습니다. 상기 논의한 방식대로, 인프라에 대한 "가시성"을 확보해야 할 필요가 있습니다.
Push 방식? Pull 방식?
Cloud Native 환경에서는 Container 기반의 Application 을 작게 운영하고 필요할 때마다 확장, 파괴하는 방식을 선택합니다(pull 방식). 동적으로 확장가능한 서버에 수집 에이전트를 일일이 설치하는 것은 불가능하므로(push 방식), 쿠버네티스 API를 통해 동적으로 확장된 서버 endpoint를 discovery 하는 방식으로 운영하는 편이 좋겠지요. 이를 서비스 디스커버리(Service Discovery)라고 합니다.
Prometheus란?
쿠버네티스 상에서 굉장히 인기있는 오픈소스 모니터링 시스템입니다. CNCF 에 속해있단 것 만으로도 그 가치를 증명했지요.
간단한 텍스트 형식으로 메트릭을 쉽게 노출 가능하며, 데이터 모델은 키밸류 형태로 레이블을 집계한 후, Grafana같은 대시보드 시스템에서 그래프로 쉽고 간단하게 Dashboard 를 만들 수 있습니다.
Prometheus 자체의 PromQL 쿼리 언어를 사용하여 Alert와 Rule set을 정의할 수도 있습니다.
Prometheus 구조에 대해
아래 그림을 통해 구조를 먼저 살펴봅시다.
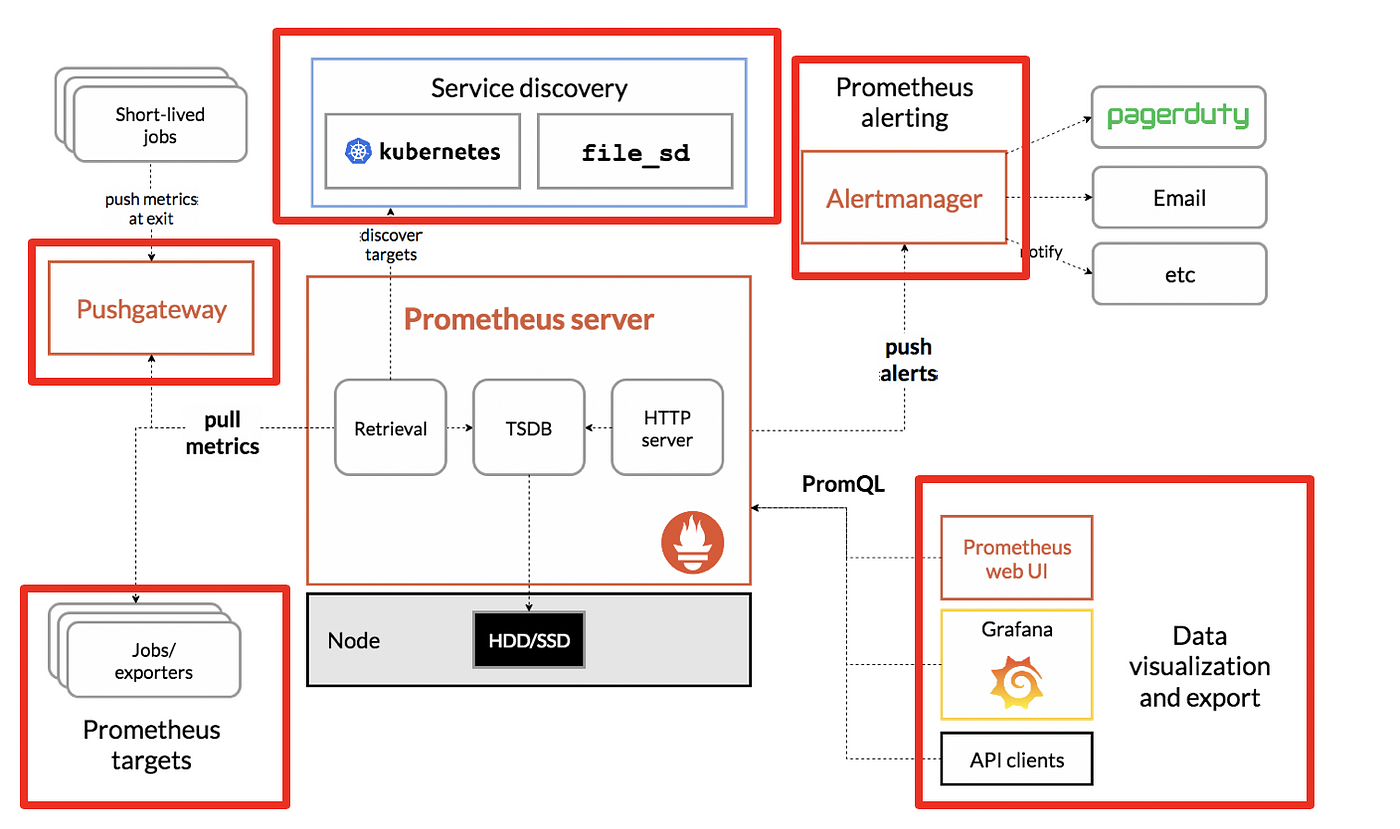
도식에 대한 출처는 링크를 클릭해주십시오.
- Service discovery : Prometheus는 기본적으로 모니터링 대상 목록을 유지하고 있으며, 대상에 대한 ip나 기타 접속 정보를 설정 파일에 주어서 모니터링 정보를 가져오는 방식을 사용합니다.
- 이러한 환경을 대처하기 위해 서비스 디스커버리를 사용하지만, 오토스케일링을 하는 환경에서는 ip가 동적으로 변경되는 경우가 많습니다.
- 따라서 모니터링 대상이 등록되어 있는 저장소에서 목록을 받아서 그 대상을 모니터링하는 형태를 취합니다. E.g.,
kubelet
- Push gateway : Pushgateway는 쉽게말해 Proxy Forwarding을 해서 접근할 수 없는 곳에 데이터가 존재하는 경우에 사용할 수 있는 대안입니다.
- application 이 push gateway 에 메트릭을 push한 후, prometheus server 가 push gateway 에 접근해 metric 을 pull 해서 오는 방식으로 동작합니다. (push와 pull이 적절히 혼합되어있네요!)
- Exporter & job: Exporter 는 Prometheus 에게 메트릭을 가져가도록 특정 Service 에 metric 을 노출하게 하는 Agent 라고 이해하시면 좋습니다.
- Exporter 는 서버 상태를 나타내는 Node exporter , SQL Exporter 등 다양한 커스텀 exporter 이 개발되어 사용되고 있습니다.
- 이러한 Exporter를 사용하여 metric 을 Prometheus 에 긁어가도록 할 수 있습니다.
- Alert manager: Alert manager 는 metric 에 대한 어떠한 지표 를 걸어놓고 그 규칙을 위반하는 사항에 대해 알람을 전송하는 역할을 합니다.
- Data visualiztion: Data visualiztion은 다양한 모니터링 Dashboard 를 위한 visualization 을 제공합니다. 주로 Prometheus 가 수집한 데이터에 대한 외부 시각화 툴 및 api를 제공하는 역할을 합니다.
Prometheus 설치
Prometheus 스택을 헬름 차트로 사용해봅시다. 후술하겠지만 프로메테우스-그라파나-로키 순으로 설치하여 메트릭 수집 및 시각화를 수행할 것입니다.
# 모니터링
kubectl create ns monitoring
watch kubectl get pod,pvc,svc,ingress -n monitoring
# 사용 리전의 인증서 ARN 확인
CERT_ARN=`aws acm list-certificates --query 'CertificateSummaryList[].CertificateArn[]' --output text`
echo "alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN"
# 설치
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
# 파라미터 파일 생성
cat <<EOT > ~/monitor-values.yaml
alertmanager:
ingress:
enabled: true
ingressClassName: alb
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
alb.ingress.kubernetes.io/success-codes: 200-399
alb.ingress.kubernetes.io/group.name: "monitoring"
hosts:
- alertmanager.$KOPS_CLUSTER_NAME
paths:
- /*
grafana:
defaultDashboardsTimezone: Asia/Seoul
adminPassword: prom-operator
ingress:
enabled: true
ingressClassName: alb
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
alb.ingress.kubernetes.io/success-codes: 200-399
alb.ingress.kubernetes.io/group.name: "monitoring"
hosts:
- grafana.$KOPS_CLUSTER_NAME
paths:
- /*
prometheus:
ingress:
enabled: true
ingressClassName: alb
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
alb.ingress.kubernetes.io/success-codes: 200-399
alb.ingress.kubernetes.io/group.name: "monitoring"
hosts:
- prometheus.$KOPS_CLUSTER_NAME
paths:
- /*
prometheusSpec:
podMonitorSelectorNilUsesHelmValues: false
serviceMonitorSelectorNilUsesHelmValues: false
retention: 5d
retentionSize: "10GiB"
EOT
# 배포
helm install kube-prometheus-stack prometheus-community/kube-prometheus-stack --version 45.7.1 \
--set prometheus.prometheusSpec.scrapeInterval='15s' --set prometheus.prometheusSpec.evaluationInterval='15s' \
-f monitor-values.yaml --namespace monitoring
# 확인
## alertmanager-0 : 사전에 정의한 정책 기반(예: 노드 다운, 파드 Pending 등)으로 시스템 경고 메시지를 생성 후 경보 채널(슬랙 등)로 전송
## grafana : 프로메테우스는 메트릭 정보를 저장하는 용도로 사용하며, 그라파나로 시각화 처리
## prometheus-0 : 모니터링 대상이 되는 파드는 ‘exporter’라는 별도의 사이드카 형식의 파드에서 모니터링 메트릭을 노출, pull 방식으로 가져와 내부의 시계열 데이터베이스에 저장
## node-exporter : 노드익스포터는 물리 노드에 대한 자원 사용량(네트워크, 스토리지 등 전체) 정보를 메트릭 형태로 변경하여 노출
## operator : 시스템 경고 메시지 정책(prometheus rule), 애플리케이션 모니터링 대상 추가 등의 작업을 편리하게 할수 있게 CRD 지원
## kube-state-metrics : 쿠버네티스의 클러스터의 상태(kube-state)를 메트릭으로 변환하는 파드
helm list -n monitoring
kubectl get pod,svc,ingress -n monitoring
kubectl get-all -n monitoring
kubectl get prometheus,alertmanager -n monitoring
kubectl get prometheusrule -n monitoring
kubectl get servicemonitors -n monitoring
kubectl get crd | grep monitoring(참고) 삭제 시에는 아래 명령을 수행하여 주십시오.
# helm 삭제
helm uninstall -n monitoring kube-prometheus-stack
# crd 삭제
kubectl delete crd alertmanagerconfigs.monitoring.coreos.com
kubectl delete crd alertmanagers.monitoring.coreos.com
kubectl delete crd podmonitors.monitoring.coreos.com
kubectl delete crd probes.monitoring.coreos.com
kubectl delete crd prometheuses.monitoring.coreos.com
kubectl delete crd prometheusrules.monitoring.coreos.com
kubectl delete crd servicemonitors.monitoring.coreos.com
kubectl delete crd thanosrulers.monitoring.coreos.comGrafana
- 그라파나는 시각화 솔루션으로 데이터 자체를 저장하지 않습니다! → 현재 실습 환경에서는 데이터 소스는 상기 말한 Prometheus와 함께 사용하지요.
접속정보확인 및 로그인을 수행해봅시다. 기본 계정정보는 (admin/prom-operator) 입니다.
# ingress 확인
kubectl get ingress -n monitoring kube-prometheus-stack-grafana
kubectl describe ingress -n monitoring kube-prometheus-stack-grafana
# ingress 도메인으로 웹 접속
echo -e "Grafana Web URL = https://grafana.$KOPS_CLUSTER_NAME"Grafana Dashboard
기본 대시보드
- 스택을 통해서 설치된 기본 대시보드 확인해봅시다! : Dashboards → Browse
- (대략) 분류 : 자원 사용량 - Cluster/POD Resources, 노드 자원 사용량 - Node Exporter, 주요 애플리케이션 - CoreDNS 등
- K8S / CR / Cluster, Node Exporter / Use Method / Cluster 와 같은 요소를 확인해봅시다.
공식 대시보드 가져오기 - 링크
- [**1 Kubernetes All-in-one Cluster Monitoring KR**] Dashboard → Import → 13770 입력 후 Load ⇒ 데이터소스(Prometheus 선택) 후 Import 클릭
- [**Kubernetes / Views / Global**] Dashboard → Import → 15757 입력 후 Load ⇒ 데이터소스(Prometheus 선택) 후 Import 클릭
kube-state-metrics-v2를 가져와봅시다 : Dashboard ID copied! (13332) 클릭 - 링크- [kube-state-metrics-v2] Dashboard → Import → 13332 입력 후 Load ⇒ 데이터소스(Prometheus 선택) 후 Import 클릭
- [**Node Exporter Full**] Dashboard → Import → 1860 입력 후 Load ⇒ 데이터소스(Prometheus 선택) 후 Import 클릭
kwatch
kwatch는 쿠버네티스 상의 알람을 제공해주는 서비스입니다. 물론 앞서 작성하였던 Prometheus 룰에 입각한 알람을 받는 것이지요.
- 슬랙, 디스코드, 등으로 알람을 받을 수 있습니다.
구축해보기
# configmap 생성
cat <<EOT > ~/kwatch-config.yaml
apiVersion: v1
kind: Namespace
metadata:
name: kwatch
---
apiVersion: v1
kind: ConfigMap
metadata:
name: kwatch
namespace: kwatch
data:
config.yaml: |
alert:
slack:
webhook: 'FIXME!!!!!'
#title:
#text:
pvcMonitor:
enabled: true
interval: 5
threshold: 70
EOT
kubectl apply -f kwatch-config.yaml
# 배포
kubectl apply -f https://raw.githubusercontent.com/abahmed/kwatch/v0.8.3/deploy/deploy.yamlLoki
메트릭에 대한 논의는 어느정도 마쳤습니다. 그렇다면 컨테이너로 구동되는 서비스의 로그를 중앙화 한다면 더 좋겠다는 생각이 자연스럽게 들테지요. 기왕이면 여러 파드의 로그들을 중앙 서버에 저장하고 이를 조회할 수 있으면 더 좋을 것입니다. 이러한 것을 가능케하는 기술이 Loki 입니다.
Loki에 저장한 그는 LogQL(PromQL과 유사)을 이용해 조회 할 수 있으며, 그라파나 웹이나 logcli를 이용해 조회 가능합니다. 전체 로그 기반 인덱스를 생성하지 않고, 메타데이터를 기준으로 인덱스를 생성하여 자원 사용량이 현저히 적습니다!
자원 삭제
헬름차트 삭제
# nginx 삭제
helm uninstall nginx
# promtail 삭제
helm uninstall promtail -n loki
# loki 삭제
helm uninstall loki -n loki
kubectl delete pvc -n loki --all
# 프로메테우스 스택 삭제
helm uninstall -n monitoring kube-prometheus-stackkOps 클러스터 삭제 및 AWS CloudFormation 스택 삭제
실습 마무리를 수행합니다.
kops delete cluster --yes && aws cloudformation delete-stack --stack-name mykops마무리
제 4장에서는 Prometheus, Grafana, Loki 및 kwatch를 활용한 모니터링 서비스 구축에 대해 살펴보았습니다.
이번 장에서는 아래 내용을 반드시 기억하셨으면 좋겠습니다.
- 컨테이너 환경 또한 주요 메트릭을 수집하여 모니터링 할 수 있어야 합니다. 시스템을 안정적으로 운영하기 위한 필수요소입니다!
- 메트릭을 수집하는 구성요소에 대해 살펴보았습니다.
- Prometheus를 통해 메트릭을 pulling 하여 중앙에서 살펴보는 시스템을 꾸릴 수 있습니다.
- Loki를 통해 각 컨테이너로부터 수집되는 로그 또한 중앙화 할 수 있었습니다.
- Grafana를 통해 서비스 로그 , 서비스 메트릭 을 중앙에서 모아보는 시스템을 꾸릴 수 있었습니다.
- kwatch 및 Prometheus alert manager를 통해 문제사항을 빠르게 대처할 수 있는 알람 시스템을 구축할 수 있었습니다.
이것으로 제 3장을 마칩니다. 긴 글 읽어주셔서 감사합니다.
