
이 내용은 CloudNet@ 에서 진행하는 쿠버네티스 실무 실습 스터디에 대한 연재글입니다.
스터디에서 사용하는 교재는 24단계 실습으로 정복하는 쿠버네티스 입니다.
본 1주차에는 제 1부의 전체 내용을 아우르되, 일부를 살펴보고 있습니다. 전체 컨텍스트를 이해하시기 위해서는 교재를 함께 참고하시기를 추천드립니다.
Prerequisites
쿠버네티스를 클라우드 환경에서 사용하고자 하는 것 자체가 이미 하기 사항들에 대한 기본적인 이해와 준비사항을 요합니다.
이번 연재글에서는 개념에 대한 상세한 추가설명은 가급적 없이 작성하려 합니다. 다만 제가 공부하며 기본적으로 알아야겠다 싶은 연재글에 대해 대신 소개드립니다.
꼭 알아야 할 내용
쿠버네티스란?
쿠버네티스는 대규모 클러스터 환경에서 컨테이너화된 애플리케이션을 자동으로 배포하고 확장, 관리하는데 필요한 여러 요소들을 자동화하는 오픈소스 플랫폼입니다.
쿠버네티스를 이용하여 컨테이너화된 앱을 여러 서버로 구성된 클러스터 환경에 안정적으로 배포할 수 있을 뿐 아니라 부하에 따른 서버/애플리케이션 확장 및 시스템 운영에 필수적인 사항들(E.g., 네트워크, 스토리지, 모니터링, etc.)을 편하게 구축, 관리할 수 있습니다.
쿠버네티스의 기본 개념 및 심화개념들에 대해서는 아래 게시글을 참고하시길 바랍니다.
기본적으로 이런 사항은 알고계시는 것이 좋습니다
- (추천!) 쿠버네티스 입문 영상 ← 반드시 시청하시기를 권장 드립니다! 입문용으로 매우 적절합니다!
- 핵심만 콕 쿠버네티스 (2) - k8s 기본 개념 상기 링크를 통해 얻은 개념에 대해 조금 더 자세히 풀어주셔서 도움이 되었습니다. 표지의 책 또한 크게 도움됩니다.
- AWS, GCP, Microsoft Azure 등의 클라우드 컴퓨팅 서비스에 대한 기본 개념 (온프렘에서도 사용가능 합니다!)
- 기본적인 컨테이너의 특징과 기초 개념
여기까지 알고 보시면 더욱 좋습니다!
- 3부작) 이게 돼요? 도커 없이 컨테이너 만들기
- 글쓰신 분의 블로그에 있는 컨테이너 인터널 시리즈도 보시기를 추천드립니다!
사전 준비사항
- AWS Free Tier 계정(비용문제로 인해 필요합니다!)
- IAM User 생성 후 권한 부여
- 학습을 위해 자신의 작업환경 IP에서만 접근할 수 있도록 하고, 관리자 권한을 주는 식으로 해결해도 좋습니다.
- Route 53 퍼블릭 호스팅 영역
- 혹은 도메인 구매사이트에서 도메인 구매 후, Route 53 설정 지정하기
AWS kOps 소개
본 도서의 가이드와는 다르게 kOps 를 사용하여 배포할 예정입니다.
kOps는 클라우드 플랫폼(AWS, GCP, Azure, etc.)에서 쉽게 쿠버네티스를 설치할 수 있도록 도와주는 도구입니다.kOps는 서버 인스턴스와 네트워크 리소스 등을 클라우드에서 자동으로 생성해 k8s 를 설치합니다.kOps는 AWS 의 다양한 서비스 와 유연하게 연동되어 사용가능합니다.
실습환경 안내
본 강의에 사용될 쿠버네티스 클러스터는 AWS CloudFormation 형식으로 배포될 예정입니다.
참고사항:
CloudFormation 생성에 사용되는 AWS EC2 Key Pair값은
AWS EC2 에 접근 후
네트워크 및 보안 > 키 페어 를 통해 생성하시면 됩니다.
해당 링크를 클릭하여 AWS CloudFormation 페이지를 통해 환경구성을 마칩니다.
kOps로 배포되는 환경은 아래 클러스터 예상도를 참고하여 주십시오.
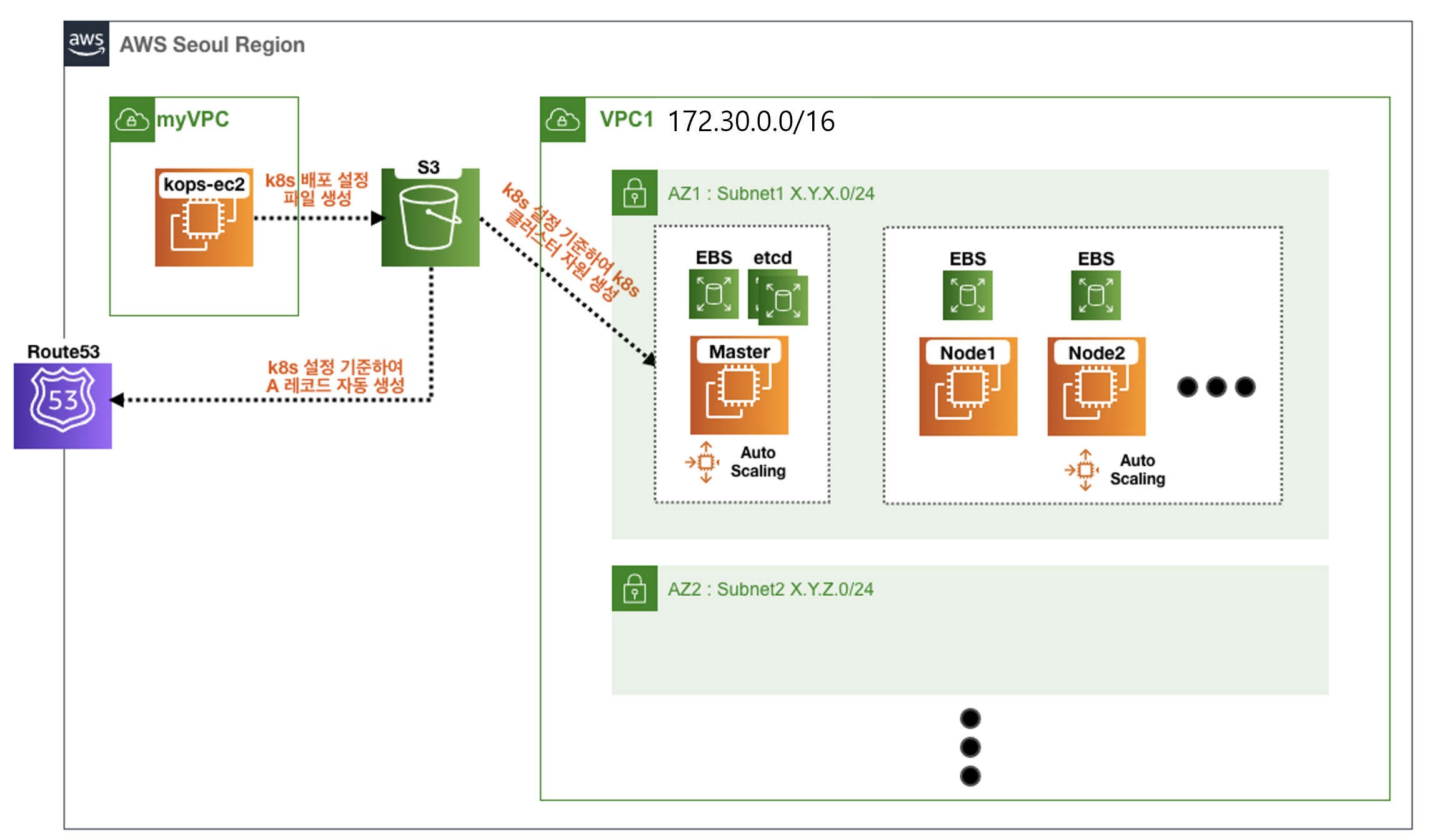
배포되는 클러스터 예상도
쿠버네티스 클러스터 설정
kops-ec2 EC2에 SSH를 통해 로그인 후 아래 명령어를 통해 관리자 권한으로 전환합니다.
# root로 전환합니다.
sudo tail -f /var/log/cloud-init-output.log
sudo su -
# 기본 툴 및 SSH 키 설치 등을 확인합니다.
kubectl version --client=true -o yaml | yh
... gitVersion: v1.26.2 ...
# kOps의 버전을 확인합니다.
kops version
Client version: 1.25.3 (git-v1.25.3)
aws --version
aws-cli/2.10.3 Python/3.9.11 Linux/4.14.304-226.531.amzn2.x86_64 exe/x86_64.amzn.2 prompt/off
ls /root/.ssh/id_rsa*이후 아래 스크립트[^1] 를 통해 쿠버네티스 클러스터 배포를 진행합니다.
#!/bin/bash
echo "클러스터명-도메인을 입력해주세요 : "
read KOPS_CLUSTER_NAME
echo "버킷명을 입력해 주세요 s3:// 는 입력하지 않아도 됩니다. : "
read KOPS_STATE_STORE
# Access Key를 입력 받음
read -p "엑세스키를 입력해주세요 : " ACCESS_KEY
# Secret Access Key를 입력 받음
read -p "시크릿키를 입력해주세요 : " SECRET_KEY
# AWS 계정 구성
aws configure set aws_access_key_id $ACCESS_KEY
aws configure set aws_secret_access_key $SECRET_KEY
echo 'export AWS_PAGER=""' >>~/.bashrc
echo "export REGION=ap-northeast-2" >>~/.bashrc
echo "export KOPS_CLUSTER_NAME=$KOPS_CLUSTER_NAME" >>~/.bashrc
echo "export KOPS_STATE_STORE=s3://$KOPS_STATE_STORE" >>~/.bashrc
# dry-run을 통해 테스트
kops create cluster --zones="$REGION"a,"$REGION"c --networking amazonvpc --cloud aws \
--master-size t3.medium --node-size t3.medium --node-count=2 --network-cidr 172.30.0.0/16 \
--ssh-public-key ~/.ssh/id_rsa.pub --name=$KOPS_CLUSTER_NAME --kubernetes-version "1.24.10" --dry-run -o yaml > mykops.yaml
# 실제 서비스 배포
kops create cluster --zones="$REGION"a,"$REGION"c --networking amazonvpc --cloud aws \
--master-size t3.medium --node-size t3.medium --node-count=2 --network-cidr 172.30.0.0/16 \
--ssh-public-key ~/.ssh/id_rsa.pub --name=$KOPS_CLUSTER_NAME --kubernetes-version "1.24.10" -y
source <(kubectl completion bash)
echo 'source <(kubectl completion bash)' >> ~/.bashrc
echo 'alias k=kubectl' >> ~/.bashrc
echo 'complete -F __start_kubectl k' >> ~/.bashrckops-ec2 EC2에 SSH를 통해 로그인 후 쉘을 하나 더띄워, 아래 명령을 통해 배포 여부를 모니터링 합니다.
while true; do aws ec2 describe-instances --query "Reservations[*].Instances[*].{PublicIPAdd:PublicIpAddress,InstanceName:Tags[?Key=='Name']|[0].Value,Status:State.Name}" --filters Name=instance-state-name,Values=running --output text ; echo "------------------------------" ; sleep 1; done주의!!! 배포 실패 시 아래와 같이 삭제방법이 번거로우니, 배포 전 꼼꼼히 확인하시고 배포하시길 바랍니다. 삭제 방안 링크
주의!!! 아울러 학습 종료 시, 하기 커맨드를 반드시 실행하셔서 추가비용이 발생하지 않도록 주의하여 주십시오.
- kOps 클러스터 삭제
kops delete cluster --yes- (클러스터 삭제 후) AWS CloudFormation 스택 삭제
aws cloudformation delete-stack --stack-name mykops삭제방안
상기 생성방안으로 올바르게 생성되지 않은 경우, 하기 사항을 반드시 확인하셔서 인스턴스 비용을 점검하여 주십시오.
- EC2 Auto Scaling 그룹 : 3개 삭제
- EC2 시작 템플릿 Launch Templates : 3개 삭제
- S3 버킷 비우기
- Route 53에 추가된 A 레코드 3개 삭제
- CloudFormation 삭제
관리 편의성 설정
반복작업 최소화
운영 시 반복되는 커맨드를 입력하거나, 오타를 내어서 다시 입력하지 않도록 합시다. 이를 위한 자동완성 요소를 ~/.bashrc 에 저장하는 편이 좋습니다.
(참고: 아래 내용은 상기 쿠버네티스 클러스터 배포 스크립트를 통해 설정하였습니다)
# 자동 완성 및 alias 축약 설정
source <(kubectl completion bash)
echo 'source <(kubectl completion bash)' >> ~/.bashrc
echo 'alias k=kubectl' >> ~/.bashrc
echo 'complete -F __start_kubectl k' >> ~/.bashrckrew: kubectl CLI 환경의 플러그인 매니저
kubectl CLI 플러그인 매니저인 krew를 설치합니다. 단순히
설치과정
# 설치
curl -fsSLO https://github.com/kubernetes-sigs/krew/releases/download/v0.4.3/krew-linux_amd64.tar.gz
tar zxvf krew-linux_amd64.tar.gz
./krew-linux_amd64 install krew
tree -L 3 /root/.krew/bin
# PATH 추가
export PATH="${PATH}:/root/.krew/bin"
echo 'export PATH="${PATH}:/root/.krew/bin"' >>~/.bashrc
# krew 확인
kubectl krew
kubectl krew update
kubectl krew search
kubectl krew list # `krew` 를 통해 설치한 플러그인의 리스트 보기
kubectl krew플러그인 소개
kube-ctx: 쿠버네티스 컨텍스트 사용kube-ns: 네임스페이스(단일 클러스터 내에서 가상 클러스터) 사용df-pv: kube PV(Persistent Volumes) 사용량을 확인합니다oomd: OOMKilled 파드을 살펴봅니다get-all: 전체 파드를 보여줍니다. (쓰시는 분들 의견으로는kubectl get all보다 낫다고 하네요)ktop: kubernetes topkube-ps1: 현재 클러스터, 네임스페이스의 이름을 프롬프트에 보여주는 플러그인입니다. 설치 내용은 아래를 참고하여 주세요.kube-neat: 쿠버네티스 오브젝트를 YAML 파일 형식으로 export 합니다.
# 설치 및 설정
git clone https://github.com/jonmosco/kube-ps1.git /root/kube-ps1
cat <<"EOT" >> /root/.bash_profile
source /root/kube-ps1/kube-ps1.sh
KUBE_PS1_SYMBOL_ENABLE=true
function get_cluster_short() {
echo "$1" | cut -d . -f1
}
KUBE_PS1_CLUSTER_FUNCTION=get_cluster_short
KUBE_PS1_SUFFIX=') '
PS1='$(kube_ps1)'$PS1
EOT
# 적용
exit
exit
# default 네임스페이스 선택
kubectl ns default기본 사용
책의 예시를 통해 쿠버네티스의 주요 오브젝트를 이해해봅시다.
파드 실행 및 파드에 붙기
# nginx 이미지를 가진 파드을 실행
k run nginx --image=nginxdeployment의 파드 개수 변경과 삭제
# httpd 이미지를 가지는 deployment 형식의 오브젝트 배포
k create deployment httpd --image=httpd
# 원하는 파드의 수량으로 상기 오브젝트 스케일 변경
# 레플리카 10개
k scale deployment httpd --replicas=10
# 0개로 변경할 수도 있고 1개 이상으로 변경할 수도 있음
k scale deployment httpd --replicas=0
k scale deployment httpd --replicas=1
# 파드 삭제.
k delete pod httpd-{임의의이름}
# ...하지만 새로운 파드가 생성됨
# 마지막으로 replicas를 1로 둔 상태를 유지하려 하기 때문
# 내부적으로는 replication-controller 파드가 현재 상태를 체크(watch 이용)하여 desired state와 맞는지 확인 후 자동으로 맞춰줌
k get pod -w디플로이먼트는 {디플로이먼트이름}-{임의해쉬값} 으로 파드의 이름을 지정합니다.
네임스페이스 생성
YAML 파일을 이용하여 오브젝트를 생성하는 것이 보통이지만, 간단한 쿠버네티스 오브젝트는 create 명령을 입력하여 생성할 수도 있습니다. deployment, secret, namespace 등이 가능합니다.
예를들어 네임스페이스를 생성하는 방법은 아래와 같습니다.
참고: ns=namespaces 입니다.
# 네임스페이스 생성
k create ns default01
# 네임스페이스 사용
k ns default01쿠버네티스 RBAC(Role-based Access Control) 를 이용하면 각 앱 별로 역할을 분리하여 특정 네임스페이스의 권한망르 갖도록 설정할 수 있습니다.
참고로 네임스페이스는 클러스터를 가상으로 분리하는 단위이기 때문에, 기본설정 상으로는 타 네임스페이스로의 네트워크 연결이 가능합니다[^2].
ExternalDNS 사용
쿠버네티스 서비스/인그레스 생성 시 도메인을 설정하면, AWS(Route 53), Azure(DNS), GCP(Cloud DNS)에 A 레코드를 자동으로 생성/삭제 해줍니다[^3].
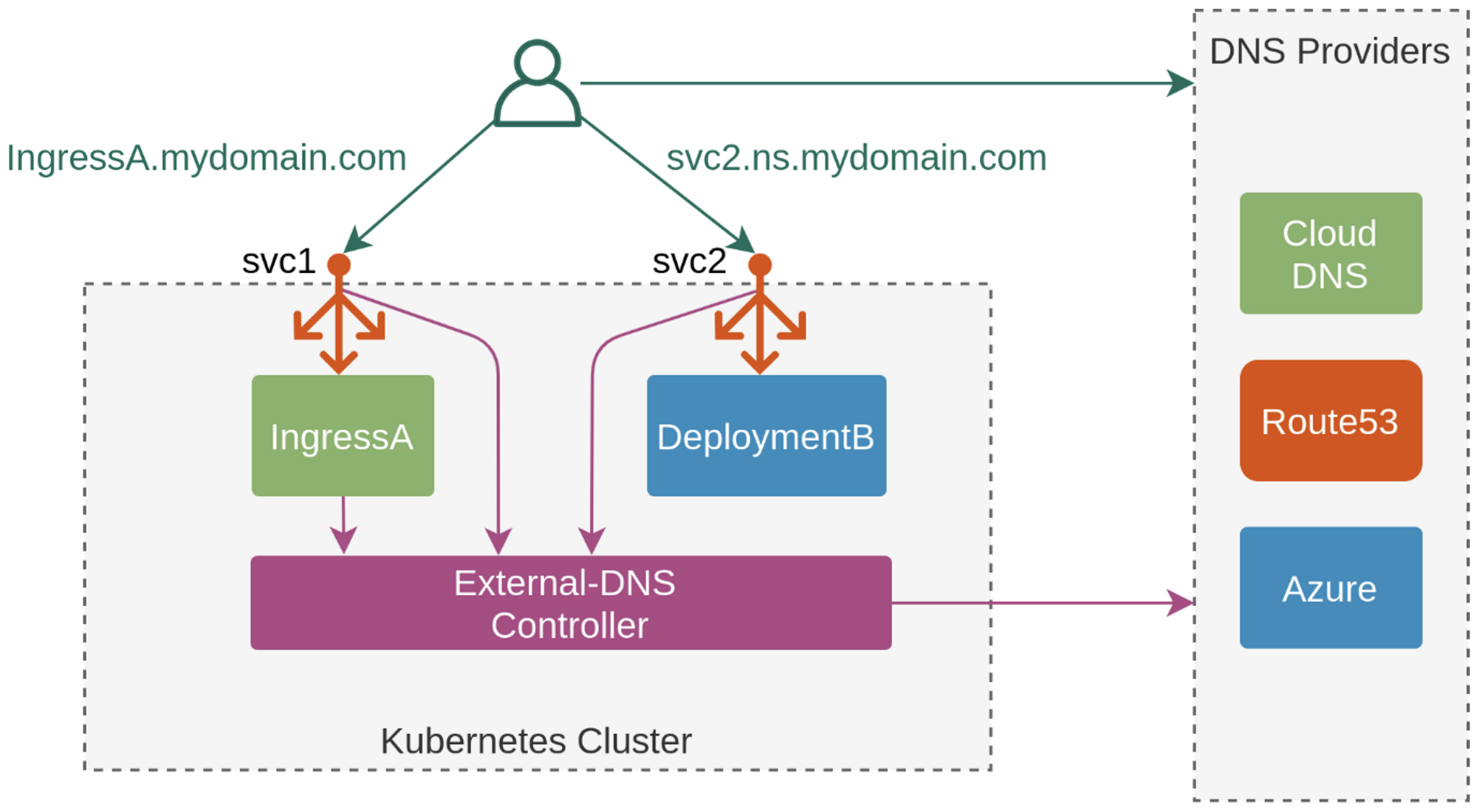
ExternalDNS 컨트롤러를 통해 desired state을 유지하는 것을 볼 수 있습니다.
externaldns 애드온은 아래의 순서대로 설치할 예정입니다.
- Route 53 정책 등록
- AWS Account ID값 을 변수로 지정
- Attach IAM policy to EC2 instance profiles
externalDns설정값 추가- kOps를 통한 롤링 업데이트 수행
# 별도 shell을 띄우고 변동사항을 모니터링
watch -d kubectl get pod -A
# 정책 생성 -> 마스터/워커노드에 정책 연결
curl -s -O https://s3.ap-northeast-2.amazonaws.com/cloudformation.cloudneta.net/AKOS/externaldns/externaldns-aws-r53-policy.json
aws iam create-policy --policy-name AllowExternalDNSUpdates --policy-document file://externaldns-aws-r53-policy.json
# ACCOUNT_ID 변수 지정
export ACCOUNT_ID=$(aws sts get-caller-identity --query 'Account' --output text)
# EC2 instance profiles 에 IAM Policy 추가(attach)
aws iam attach-role-policy --policy-arn arn:aws:iam::$ACCOUNT_ID:policy/AllowExternalDNSUpdates --role-name masters.$KOPS_CLUSTER_NAME
aws iam attach-role-policy --policy-arn arn:aws:iam::$ACCOUNT_ID:policy/AllowExternalDNSUpdates --role-name nodes.$KOPS_CLUSTER_NAME
# 설치
kops edit cluster
--------------------------
spec:
externalDns:
provider: external-dns
--------------------------
# 업데이트 적용
kops update cluster --yes && echo && sleep 3 && kops rolling-update cluster
# externalDns 컨트롤러 파드 확인
kubectl get pod -n kube-system -l k8s-app=external-dns
NAME READY STATUS RESTARTS AGE
external-dns-66969c4497-wbs5p 1/1 Running 0 8m53s아울러, mario 서비스에 도메인 연결을 하는 실습을 통해, mario.클러스터명 으로 도메인이 연결되는지 확인해보겠습니다.
# EC2 인스턴스 모니터링
while true; do **aws ec2 describe-instances** --query "Reservations[*].Instances[*].{PublicIPAdd:PublicIpAddress,InstanceName:Tags[?Key=='Name']|[0].Value,Status:State.Name}" --output text | sort; echo "------------------------------" ;date; sleep 1; done
# 인스턴스그룹 정보 확인
**kops get ig**
# 노드 추가
kops **edit** ig nodes-ap-northeast-2a **--set spec.minSize=2 --set spec.maxSize=2**
# 적용
kops **update** cluster --yes && echo && sleep 3 && kops **rolling-update** cluster
# 워커노드 증가 확인
while true; do kubectl get node; echo "------------------------------" ;date; sleep 1; done
성공적으로 배포되었습니다!
트러블슈팅
쿠버네티스 환경에서 발생하는 트러블슈팅 방안을 알아봅시다.
쿠버네티스 작업 순서는 다음과 같습니다.
Apply → Get → Describe → Logs → Get Event
- YAML 파일을 이용해 오브젝트를 생성(apply) 하고 생성한 오브젝트 리스트는
get명령어로 확인합니다. - 파드가 정상생성되지 않았다면
describe명령어로 확인합니다. - 이후 애플리케이션 에러는
logs로 확인하고, 쿠버네티스 클러스터 관련 메시지는 이벤트 명령어get event로 확인합니다.
잘못된 버전의 파드 배포 후 디버깅하는 과정
문제 파악을 describe, get events 로 수행하는 과정에 집중하여 살펴보십시오.
아울러 patch, update간의 차이는 해당 링크를 참고하십시오.
# 터미널1
watch kubectl get pod
# 잘못된 이미지 정보의 파드 배포
kubectl apply -f https://raw.githubusercontent.com/junghoon2/kube-books/main/ch05/nginx-error-pod.yml
# 확인
kubectl get pod -owide
kubectl describe pod nginx-19
# 터미널2 : 문제 원인이 무엇일까요?
# 원인은 Describe에서도 확인할 수 있습니다.
# ImagePullBackOff는 이미지를 가져오는데 실패했음을 의미합니다.
kubectl get events -w
# 이미지 업데이트 : patch 와 update 의 차이는 무엇일까요?
# patch: YAML 파일을 edit하지 않고 설정을 변경합니다.
# update: patch/edit을 사용하지 않고 디버깅/테스팅 목적으로 강제적용을 하는 식으로 사용합니다.
#
kubectl patch pod nginx-19 --type='json' -p='[{"op": "replace", "path": "/spec/containers/0/image", "value":"nginx:1.19"}]'
# 확인
kubectl get pod
# 클러스터 수준 이벤트 확인
kubectl get events
kubectl get events -w
kubectl get events -n kube-system
kubectl get events -h | grep '#' -A2
# 삭제
kubectl delete pod nginx-19장애사례 처리 예시
노드의 사용 가능한 디스크 용량이 부족한 경우 발생하는 에러와, 에러 처리 프로세스를 살펴봅시다.
쿠버네티스에서는 특정 노드에 문제가 발생하면 다른 노드로 이전 후 실행하여 항상 애플리케이션을 의도한 상태로 유지합니다. 정확히는 deployment-controller 가 watch 기능을 통해 API Server의 변경 상태를 확인하여, 의도한 상태로 유지함을 의미합니다.
다시말해, Pets vs. Cattle 개념을 살펴볼 수 있습니다. 특정 앱에 문제가 생기면, 해당 앱을 종료하고 바로 새로운 파드로 교체하는 전략을 취합니다.
# 터미널1
watch kubectl get pod -owide
# 터미널2
kubectl get pod -w
# 디플로이먼트 배포
curl -s -O https://raw.githubusercontent.com/junghoon2/kube-books/main/ch05/busybox-deploy.yml
cat busybox-deploy.yml | sed -e 's/replicas: 10/replicas: 6/g' | kubectl apply -f -
# 워커 노드 Public IP 확인
aws ec2 describe-instances --query "Reservations[*].Instances[*].{PublicIPAdd:PublicIpAddress,InstanceName:Tags[?Key=='Name']|[0].Value}" --filters Name=instance-state-name,Values=running --output table
# 워커 노드 Public IP 변수 지정
W1PIP=<워커 노드 1 Public IP>
W2PIP=<워커 노드 2 Public IP>
W1PIP=3.38.209.81
W2PIP=3.37.55.210
# 워커 노드 스토리지 확인
ssh -i ~/.ssh/id_rsa ubuntu@$W1PIP df -hT -t ext4
ssh -i ~/.ssh/id_rsa ubuntu@$W2PIP df -hT -t ext4
# 노드2에 디스크에 큰 파일 생성
ssh -i ~/.ssh/id_rsa ubuntu@$W2PIP fallocate -l 110g 110g-file
# 노드2에 디스크에 용량 확인 >> 90% 넘김!
ssh -i ~/.ssh/id_rsa ubuntu@$W2PIP df -hT -t ext4
Filesystem Type Size Used Avail Use% Mounted on
/dev/root ext4 124G 114G 11G 92% /
# 파드 상태 확인 >> 노드2에서 쫓겨남 확인!
kubectl get pod -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
busybox-6d8496d56f-2pcvb 1/1 Running 0 41m 172.16.231.12 k8s-n3 <none> <none>
busybox-6d8496d56f-4pqn6 1/1 Running 0 49m 172.16.231.11 k8s-n3 <none> <none>
busybox-6d8496d56f-5m87k 0/1 Evicted 0 42m <none> k8s-n2 <none> <none>
...
# 노드의 이벤트이므로 클러스터 이벤트 확인
kubectl get events
53m Warning FailedKillPod pod/busybox error killing pod: failed to "KillContainer" for "busybox" with KillContainerError: "rpc error: code = NotFound desc = an error occurred when try to find container \"9649217ee98a458575be91366be62ab7b9cde1fd0149f309de5cdfb1b9be253b\": not found"
50m Normal ScalingReplicaSet deployment/busybox Scaled up replica set busybox-6d8496d56f to 10
38m Warning EvictionThresholdMet node/k8s-n2 Attempting to reclaim ephemeral-storage
43m Normal NodeHasDiskPressure node/k8s-n2 Node k8s-n2 status is now: NodeHasDiskPressure
41m Warning FreeDiskSpaceFailed node/k8s-n2 failed to garbage collect required amount of images. Wanted to free 4237015449 bytes, but freed 0 bytes
36m Warning FreeDiskSpaceFailed node/k8s-n2 failed to garbage collect required amount of images. Wanted to free 4237351321 bytes, but freed 0 bytes
31m Warning FreeDiskSpaceFailed node/k8s-n2 failed to garbage collect required amount of images. Wanted to free 4239841689 bytes, but freed 0 bytes
26m Warning FreeDiskSpaceFailed node/k8s-n2 failed to garbage collect required amount of images. Wanted to free 4242352537 bytes, but freed 0 bytes
21m Warning FreeDiskSpaceFailed node/k8s-n2 failed to garbage collect required amount of images. Wanted to free 4253202841 bytes, but freed 0 bytes
16m Warning FreeDiskSpaceFailed node/k8s-n2 failed to garbage collect required amount of images. Wanted to free 4255717785 bytes, but freed 0 bytes
11m Warning FreeDiskSpaceFailed node/k8s-n2 failed to garbage collect required amount of images. Wanted to free 4258220441 bytes, but freed 0 bytes
6m46s Warning FreeDiskSpaceFailed node/k8s-n2 failed to garbage collect required amount of images. Wanted to free 4260731289 bytes, but freed 0 bytes
106s Warning FreeDiskSpaceFailed node/k8s-n2 failed to garbage collect required amount of images. Wanted to free 4263233945 bytes, but freed 0 bytes
53m Normal Killing pod/nginx-19 Stopping container nginx-pod
kubectl describe nodes
# 삭제
kubectl delete deploy busybox
ssh -i ~/.ssh/id_rsa ubuntu@$W2PIP rm -rf 110g-file조치 프로세스 가이드
learnk8s에서 제공하고, 한국어로 번역된 게시글에 대해 링크를 공유합니다. 필요할 때마다 두고두고 챙겨봐야겠습니다.
끝으로
컨테이너 환경은 보통 이식성이 좋습니다. 이러한 이유로 에러 메시지를 확인하여 기존 파드를 없애고 새로운 파드를 바로 시작하거나 문제가 있는 노드를 재부팅하는 방식으로 해결하는 경우가 많습니다.
헬름(Helm) 에 대하여
쿠버네티스를 통해 애플리케이션을 실행하기 위해서는 쿠버네티스 리소스가 많이 필요한 경우가 많습니다. 파드의 노출을 담당하는 Service, 애플리케이션 설정과 관련된 ConfigMap, 기밀 정보를 다루는 Secret 등을 하나의 앱에 포함시킵니다.
이 같은 경우, 다양한 리소스를 각각 관리하지 않고 하나의 패키지로 관리하는 도구가 Helm(이하 헬름) 입니다.
헬름이 좋은 이유
아래의 이유로 헬름을 사용해야합니다.
- 다양한 환경/설정에서 하나의 템플릿으로 재사용
- 필요한 모듈만 배포 가능
- 안정적인 헬름 차트 생태계에서 필요한 오픈소스 설치
- 이미 대부분의 애플리케이션 제조사에서 직접 헬름 파일을 제공합니다. 이는 안정성, 고가용성 측면에서 검증된 케이스에 기반하여 만들어집니다.
헬름의 기본 개념
- 헬름 차트(Charts)
- 애플리케이션 설치에 사용되는 네트워크, 스토리지, 보안과 관련된 여러 쿠버네티스 리소스를 묶어놓은 패키지입니다.
- 헬름 차트의 디렉토리 구조는 아래와 같습니다[^4]
헬름차트 디렉토리/ Chart.yaml # 차트에 대한 정보를 가진 YAML 파일 LICENSE # 옵션: 차트의 라이센스 정보를 가진 텍스트 파일 README.md # 옵션: README 파일 values.yaml # 차트에 대한 기본 환경설정 값들 values.schema.json # 옵션: values.yaml 파일의 구조를 제약하는 JSON 파일 charts/ # 이 차트에 종속된 차트들을 포함하는 디렉터리 crds/ # 커스텀 자원에 대한 정의 templates/ # values와 결합될 때, 유효한 쿠버네티스 manifest 파일들이 생성될 템플릿들의 디렉터리 templates/NOTES.txt # 옵션: 간단한 사용법을 포함하는 텍스트 파일 - 헬름 리포지토리(Repositories)
- 다양한 헬름 차트를 저장하고 공유하는 저장소 입니다.
- 많은 업체들이 직접 헬름 리포지토리를 제공하기도 합니다.
- 헬름이 관리하는 공식차트는 ArtifactHub에서도 찾을 수 있습니다.
- 헬름 템플릿(Templates)
- 헬름은 템플릿을 이용하여 설치와 관련된 파일을 관리합니다.
- 이는 일정한 형식 또는 포맷을 의미하며, 사용자는 이름/날짜 등의 특정 변수만 수정하면 해당 파일을 사용할 수 있습니다.
yalues.yaml파일에서 키-값 형식으로 관리합니다.- resources아래의 requests/limits를 통해 자원 요청량 및 사용가능 자원의 한계를 지정할 수 있습니다.
노드 최대 파드 배포
워커 노드의 인스턴스 타입 별 파드 생성 갯수 제한
- Secondary IPv4 addresses : 인스턴스 유형에 최대 ENI 갯수와 할당 가능 IP 수를 조합하여 선정합니다
- 인스턴스 타입 별 ENI 최대 갯수와 할당 가능한 최대 IP 갯수에 따라서 파드 배치 갯수가 결정됩니다.
- 단, aws-node 와 kube-proxy 파드는 호스트의 IP를 사용함으로 최대 갯수에서 제외합니다.
아래는 최대 파드 생성갯수에 대한 수식입니다.
최대 파드 생성 갯수 : (Number of network interfaces for the instance type × (the number of IP addressess per network interface - 1)) + 2
워커 노드의 인스턴스 정보 확인
# t3 타입의 정보(필터) 확인
aws ec2 describe-instance-types --filters Name=instance-type,Values=t3.* \
--query "InstanceTypes[].{Type: InstanceType, MaxENI: NetworkInfo.MaximumNetworkInterfaces, IPv4addr: NetworkInfo.Ipv4AddressesPerInterface}" \
--output table
--------------------------------------
| DescribeInstanceTypes |
+----------+----------+--------------+
| IPv4addr | MaxENI | Type |
+----------+----------+--------------+
| 15 | 4 | t3.2xlarge |
| 6 | 3 | t3.medium |
| 12 | 3 | t3.large |
| 15 | 4 | t3.xlarge |
| 2 | 2 | t3.micro |
| 2 | 2 | t3.nano |
| 4 | 3 | t3.small |
+----------+----------+--------------+
# 파드 사용 가능 계산 예시 : aws-node 와 kube-proxy 파드는 host-networking 사용으로 IP 2개 남음
((MaxENI * (IPv4addr-1)) + 2)
t3.medium 경우 : ((3 * (6 - 1) + 2 ) = 17개 >> aws-node 와 kube-proxy 2개 제외하면 15개
# 워커노드 상세 정보 확인 : 노드 상세 정보의 Allocatable 에 pods 에 17개 정보 확인
kubectl describe node | grep Allocatable: -A6
Allocatable:
cpu: 2
ephemeral-storage: 59763732382
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 3854320Ki
pods: 17최대 파드 생성 및 확인
그렇다면, 최대 파드 이상을 생성해보고, 어떤 에러가 발생하는지 살펴봅시다.
# 워커 노드 EC2 - 모니터링
watch -d "ip link | egrep 'ens|eni'"
while true; do ip -br -c addr show && echo "--------------" ; date "+%Y-%m-%d %H:%M:%S" ; sleep 1; done
# 작업용 EC2 - 터미널1
watch -d 'kubectl get pods -o wide'
# 작업용 EC2 - 터미널2
# 디플로이먼트 생성
kubectl apply -f https://raw.githubusercontent.com/gasida/PKOS/main/2/nginx-dp.yaml
# 파드 확인
kubectl get pod -o wide
kubectl get pod -o=custom-columns=NAME:.metadata.name,IP:.status.podIP
kubectl ktop
# 파드 증가 테스트 >> 파드 정상 생성 확인, 워커 노드에서 eth, eni 갯수 확인
kubectl scale deployment nginx-deployment --replicas=8
# 파드 증가 테스트 >> 파드 정상 생성 확인, 워커 노드에서 eth, eni 갯수 확인 >> 어떤일이 벌어졌는가?
kubectl scale deployment nginx-deployment --replicas=10
# 파드 증가 테스트 >> 파드 정상 생성 확인, 워커 노드에서 eth, eni 갯수 확인 >> 어떤일이 벌어졌는가?
kubectl scale deployment nginx-deployment --replicas=30
# 파드 생성 실패!
kubectl get pods | grep Pending
nginx-deployment-7fb7fd49b4-d4bk9 0/1 Pending 0 3m37s
nginx-deployment-7fb7fd49b4-qpqbm 0/1 Pending 0 3m37s
...
kubectl describe pod <Pending 파드> | grep Events: -A5
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling 45s default-scheduler 0/3 nodes are available: 1 node(s) had untolerated taint {node-role.kubernetes.io/control-plane: }, 2 Too many pods. preemption: 0/3 nodes are available: 1 Preemption is not helpful for scheduling, 2 No preemption victims found for incoming pod.
# 디플로이먼트 삭제
kubectl delete deploy nginx-deployment이에 대한 해결책은 2주차에 살펴보겠습니다.
kOps 활용
kOps를 이용하여 쿠버네티스 클러스터를 관리하는 다양한 방안에 대해 살펴봅시다.
# EC2 인스턴스 모니터링
while true; do aws ec2 describe-instances --query "Reservations[*].Instances[*].{PublicIPAdd:PublicIpAddress,InstanceName:Tags[?Key=='Name']|[0].Value,Status:State.Name}" --output text | sort; echo "------------------------------" ;date; sleep 1; done
# 인스턴스그룹 정보 확인
kops get ig
# 노드 추가
kops edit ig nodes-ap-northeast-2a --set spec.minSize=4 --set spec.maxSize=4
# 적용
kops update cluster --yes && echo && sleep 3 && kops rolling-update cluster
# 워커노드 증가 확인
while true; do kubectl get node; echo "------------------------------" ;date; sleep 1; done- kOps에 Node local DNS cache 설정하기
#
kops edit cluster
-----------------
spec:
kubeDNS:
provider: CoreDNS
nodeLocalDNS:
enabled: true
memoryRequest: 5Mi
cpuRequest: 25m
...
-----------------
# 적용 : 모든 노드 재생성으로 10~15분 정도 시간 소요
kops update cluster --yes && echo && sleep 3 && kops rolling-update cluster- AWS kOps Audit Logging 설정하기 - 링크
- AWS kOps Private Cluster 설정하기 - 링크 링크2
- AWS kOps Rolling Updates 실행해보기 - 링크
- AWS kOps 인스턴스그룹에 spot 인스턴스 사용해보기 - 링크
- kops로 손쉽게 spot instance 요청하기
- AWS kOps multiple master 설정하기 - 링크 링크2
- kOps dns-controller compatibility mode - 링크
- AWS kOps의 ETCD 백업, 복구, 암호화 해보기 - 링크
- AWS kOps에 IRSA 설정하기 - 링크
- 기존에 존재하는 VPC 에 AWS kOps 클러스터 설치하기 - 링크
- AWS kOps에 Karpenter 활용하기 - 링크 링크2
마무리
제 1장에서는 1부의 내용을 기록하느라 사실 꽤나 길어졌습니다. 그만큼 다룰 것이 많음을 반증하는 것이지요.
이번 장에서는 아래 내용을 반드시 기억하셨으면 좋겠습니다.
kOps를 활용한 쿠버네티스 배포 및 다양한 활용방안에 대해 배웠습니다.- 클러스터 관리 편의성을 위해 아래 사항을 고려해보았습니다.
- 명령어 입력에 대해 alias 값을 두었습니다.
krew와 같은 CLI 플러그인을 이용하여 필요한 기능을 확장하였습니다.
- 쿠버네티스 기본 사용을 통해 기초사항을 다시 한 번 되돌아보았습니다.
- ExternalDNS를 통해 배포와 동시에 도메인 배포자동화 방안에 대해 살펴보았습니다.
- 쿠버네티스 환경에서의 트러블슈팅 방안에 대해 살펴보았습니다.
- 헬름을 통한 애플리케이션 배포 방안에 대해 살펴보았습니다.
이것으로 제 1장을 마칩니다. 긴 글 읽어주셔서 감사합니다.
[^1]: linuxer 님의 스크립트를 원본으로 사용하였습니다. 감사합니다.
[^2]: 쿠버네티스의 네트워크 정책을 이용하면 네임스페이스/파드 단위로 네트워크 접근을 차단할 수 있습니다. 참고 링크
[^3]: RBAC 환경에서의 ExternalDNS는 해당 글을 참고하여 주십시오.
[kubernetes] ExternalDNS란? 개념부터 설치까지 정리(AWS EKS)
kubernetes + Kops + ExternalDNS 정리 – 2
[^4]: 상세한 사항은 해당 링크를 참조하십시오.
