🚪들어가며...
현재 우리팀에서는 elasticsearch, kibana, filebeat를 활용해서 로깅 시스템을 구축하고 있다.
- filebeat가 로그 파일을 읽어와서 es 에 부어줌
- es에서 인덱스 템플릿을 만들어서 로그 관리
- kibana에서 해당 로그 조회
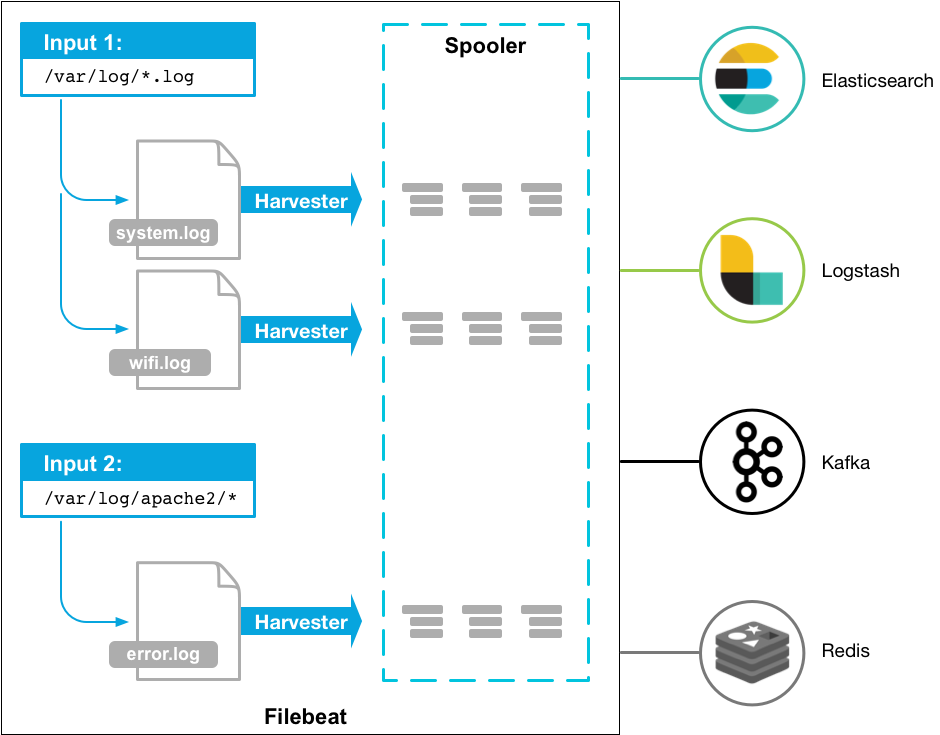
간단히 표현하면 아래와 같은 플로우가 되겠다.
log 파일 -> filebeat -> es -> kibana
시간이 지나 새로운 es / kibana 클러스터로 교체할 시기가 오게 되었고 내가 해당 업무를 맡으면서 이야기가 시작된다...🧚♀️
간단한 사전 조사
- filebeat란?
(Filebeat overview 참고)
특정 서버에 설치하여 원하는 위치에 존재하는 로그 파일을 읽어서 인덱싱을 위해 es 나 logstash로 포워딩해주는 프로그램
간단하게 말하면 Harvester
진행 순서
es 클러스터를 교체하기 위해서 바로 교체하는 것이 아니라 먼저 신 / 구 버전의 es 클러스터를 함께 사용하고 신 버전의 es 클러스터가 안정화된 것이 확인하면 구 버전의 es 클러스터를 종료하기로 했다. 그래서 정리한 진행 순서는 아래 내용이었다.
- 로그 파일이 생성되고 있는 애플리케이션 클러스터에서 filebeat가 부어줄 es 의 주소를 추가
- 새로운 es 클러스터에 인덱스 템플릿 등록 및 ILP(index lifecycle policy) 설정
참고한 블로그 : ElasticSearch를 활용한 Kubernetes 로깅 환경 구성
filebeat 설정
하나의 서버 인스턴스에서 filebeat 를 실행하고 있다면 인스턴스에 접속해서 filebeat 설정 파일을 수정했겠지만 filebeat를 실행하고 있는 환경이 하나의 클러스터였기 때문에 쿠버네티스의 configMap을 이용하여 설정 파일을 수정해야 했다.
(kubernetes의 configMap의 역할 : 비밀 정보가 아닌 값을 키-밸류 형식으로 저장하기 위함)
나는 인그레스 노드와 워커 노드에만 configMap 내용을 수정하여 반영했다.
kubectl apply -f (configMap.yaml)
# 아래 명령어 or 대시보드에서 확인 가능
kubectl get configmaps -n (namespace)
kubectl describe configmaps (configMap 이름) -n (namespace)그리고 이를 위해서 kubernetes에서 daemonSet을 설정해준다.
(kubernetes의 daemonSet의 역할 : deployment와 유사하게 pod를 생성하거나 관리하지만 특정 pod를 더 세분화해서 관리가 가능)
kubectl apply -f (daemonSet.yaml)
# 재시작해서 daemonSet 설정 적용
# 클러스터에서 systemctl restart (프로세스)와 같은 역할
kubectl rollout restart daemonset (daemonSet 이름) -n (namespace)es 인덱스 템플릿 설정
es 에서 filebeat가 보내주는 로그에 따라 어떻게 인덱스를 생성해서 문서들을 넣을지를 결정해주는 인덱스 템플릿을 설정한다.
이 과정에서 shard, replica 개수를 설정하고 어떤 데이터 필드를 가지는지, 이 인덱스의 이름은 어떻게 설정할지를 결정한다.
이 과정에서 이전에 쓰던 es의 버전이 6점대 였기 때문에 이전의 템플릿으로 등록이 안되는 현상이 발생했다. 검색해보니 es 7점대부터 type이 사라졌다고 한다. 그래서 include_type_name=true를 이용해서 type 이 존재하는 형태의 template을 등록했다. es 는 버전에 따른 차이가 다른 애플리케이션과 비교해서 더 큰 것 같다..!
참고 자료 : https://www.elastic.co/blog/moving-from-types-to-typeless-apis-in-elasticsearch-7-0
추가적으로 생성된 인덱스에는 ILP(index lifecycle policy)를 설정해서 과도하게 오래된 데이터들이 저장공간을 차지해서 성능을 저하하지 않도록 했다.
