
클러스터와 노드
클러스터란?
여러 대의 컴퓨 터 혹은 구성 요소들을 논리적으로 결합하여 전체를 하나의 컴퓨터 혹은 하나의 구성 요소처럼 사용할 수 있게 해주는 기술을 말한다.
그렇다면 ElasticSearch 클러스터에서 클러스터와 노드의 개념은?
여러 개의 ElasticSearch 프로세스들을 논리적으로 결합하여 하나의 ElasticSearch 프로세스처럼 사용할 수 있게 해준다. 여기서 각각의 ElasticSearch 프로세스들을 노드라고 부른다.
ElasticSearch에서 여러개의 노드로 클러스터를 구성하는 이유는 무엇일까?
다수의 노드로 클러스터를 구성하면 하나의 노드에 장애가 발생해도 다른 노드에 요청할 수 있기 때문에 안정적으로 클러스터를 유지할 수 있고 이를 통해서 높은 수준의 안정성을 보장할 수 있다.
노드의 종류
-
마스터
- 클러스터의 메타데이터를 관리하는 역할을 하며 반드시 한 대 이상으로 구성해야 한다
-
데이터
- 사용자가 색인한 문서를 저장하고, 검색 요청을 처리해 서 결과를 돌려주는 역할
- 자신이 받은요청 중자신이 처리할 수 있는 요청은 직접 처리하고, 다른 데이터 노드들이 처리해야 할 요청은 해당 데이터 노드에 전달 (관련 정보는 마스터 노드를 통해 받은 클러스터의 전체 상태 정보 를 바탕으로 한다.)
-
인제스트
- 사용자가 색인하길 원하는 문서의 내용 중 변환이 필 요한 부분을 사전에 처리
-
코디네이트
- 실제 데이터를 저장하고 처리하지는 않지만, 사용자 의 색인이나 검색 등 모든 요청을 데이터 노드에 전달하는 역할
하나의 노드가 한번의 여러 개의 역할도 할 수 있다.
또한 클러스터 내에서 메타데이터를 관리하는 마스터 노드는 한 대이다. 여러 대의 마스터 노드가 있더라도 한 대만 실제 메타데이터를 관리하는 역할을 수행하고, 나머지는 현재 동작하고 있는 마스터 노드에 장애가 발생했을 때 새로운 마스터가 될 수 있는 마스터 후보 노드가 된다.
인덱스와 타입
인덱스와 타입의 개념
- 인덱스 : 사용자의 데이터가 저장되는 논리적인 공간
- 타입 : 인덱스 안의 데이터를 유형별로 논리적으로 나눠 놓은 공간
ElasticSearch를 RDBMS와 비교해보면 다음 표처럼 나타낼 수 있다.
| ElasticSearch | RDBMS |
|---|---|
| 인덱스 | 데이터베이스 |
| 타입 | 테이블 |
ElasticSearch는 6.x 버전 이후로는 하나의 인덱스에 하나의 타입만 가질 수 있다. 그래서 타입을 RDBMS의 테이블과 비교했을 때 딱 들어맞진 않지만 문서들을 논리적으로 한 번 더 나눈다는 의미에서 테이블과 비교해서 이해하면 된다.
ElasticSearch 6.x 이후로는 단일 타입만을 허용하기 때문에 큰 이슈가 없다면 _doc을 타입명으로 사용하게 된다.
인덱스의 이름은 클러스터 내에서 유일해야 하며, 동일한 이름의 다른 인덱스를 만들 수는 없다.
멀티 타입
버전 5.x까지는 하나의 인덱스에 여러 개의 타입을 사용할 수 있었기 때문에 인덱스 내에서 타입이 논리적으로 분리될 수 있다.
왜 6.x 버전부터는 멀티 타입을 허용하지 않게 된 걸까?
인덱스에 존재하는 서로 다른 타입에서 동일한 이름의 JSON 문서 필드를 만들 수 있어서 의도치 않은 검색 결과가 나타나는 문제가 발생했기 때문이다.
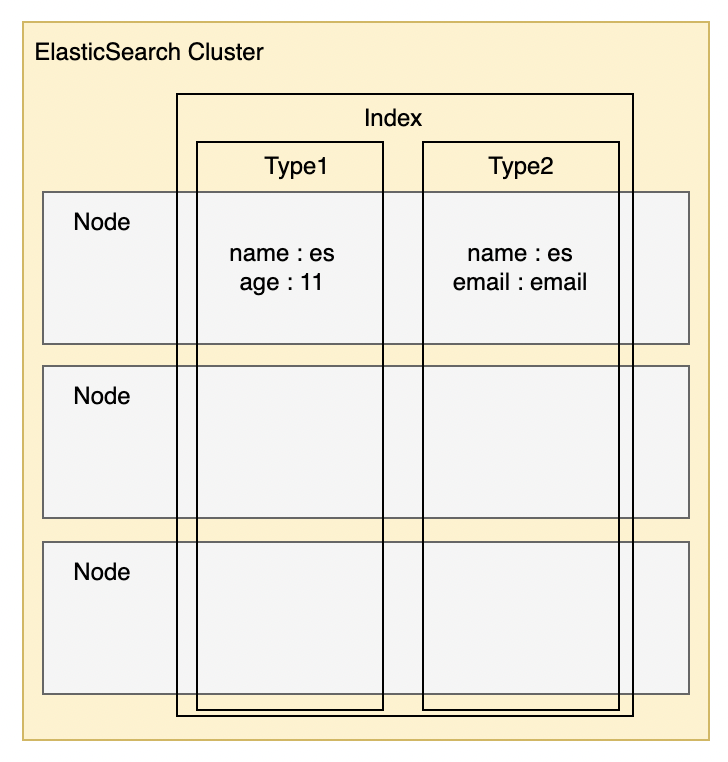
위 그림에서 type1, type2 는 다른 타입이지만 name 이라는 필드를 똑같이 가지고 있고 한 인덱스 안에서 name 이라는 필드로 검색을 할 경우 두 타입 모두 검색되는 일이 발생한다.
ElasticSearch에서는 _doc이라는 이름으로 타입을 사용하도록 권고하며, 이후에는 _doc이라는 이름으로 고정될 예정. 만약 멀티 타입을 사용하는 인덱스가 있을 경우 타입별로 인덱스를 분리 하는 형태로 재구성해야 한다.
스터디를 진행하던 도중 하위 호환성을 포기하면서까지 멀티 타입을 포기한 이유가 궁금해졌고 아래와 같은 문서를 찾을 수 있었다.
- ElasticSearch 공식 문서에서의 설명
https://www.elastic.co/guide/en/elasticsearch/reference/7.17/removal-of-types.html- ElasticSearch github 문서에서의 문제 제기
https://github.com/elastic/elasticsearch/issues/15613내용을 정리해보면 위의 그림에서 처럼 다른 타입이지만 같이 검색되는 이슈가 있고 추가로 루씬 자료구조 상 겹치지 않는 필드에 대해서 검색 성능 이슈 및 메모리 이슈, 동기화 이슈 등으로 멀티 타입이 삭제되었다.
샤드와 세그먼트
샤드와 세그먼트의 개념
- 샤드 : 인덱스에 색인되는 문서들이 저장되는 논리적인 공간
- 세그먼트 : 샤드의 데이터들을 가지고 있는 물리적인 파일을 의미
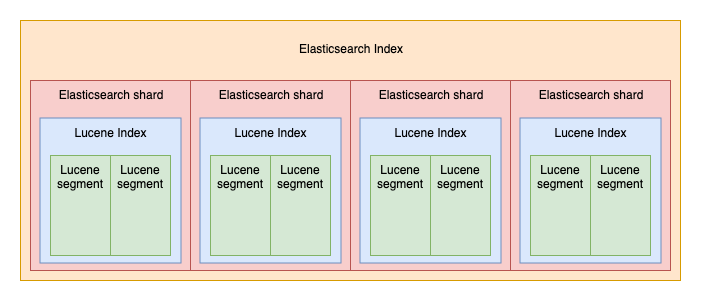
그림 출처 : https://fdv.github.io/running-elasticsearch-fun-profit/003-about-lucene/003-about-lucene.html
하나의 인덱스는 다수의 샤드로 구성되고 하나의 샤드는 다수의 세그먼트로 구성된다. 샤드는 1개 이상의 세그먼트로 구성 되는데 샤드마다 세그먼트의 개수는 서로 다를 수 있다.
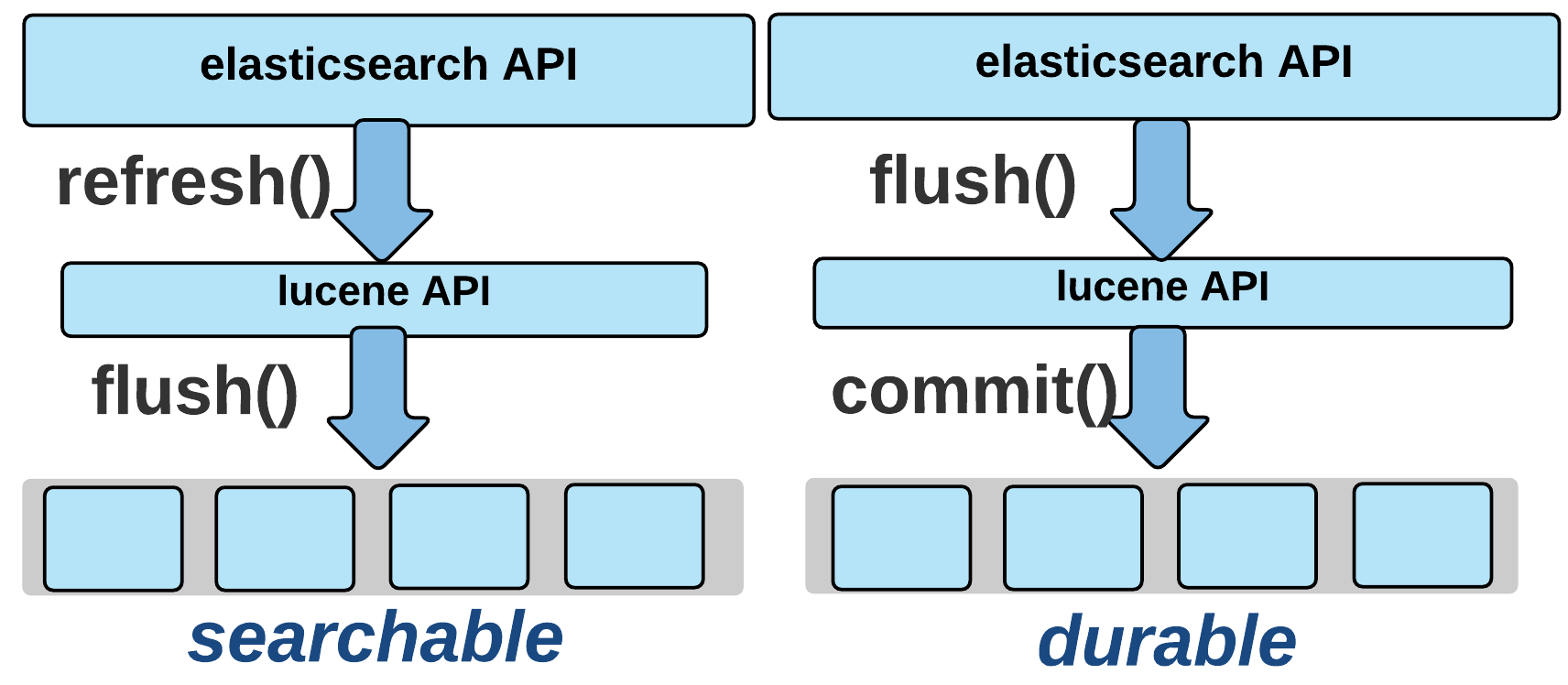
그림 출처 : https://www.elastic.co/kr/blog/nuxeo-search-and-lucene-oh-my
인덱스에 저장되는 문서는 해시 알고리즘에 의해서 샤드들에 분산 저장되고 이 문서들은 실제로는 세그먼트라는 물리적 파일에 저장된다. 하지만 문서가 처음부터 세그먼트에 저장되는 것은 아니다. 색인된 문서는 먼저 시스템의 메모리 버퍼 캐시에 저장되는데 이 단계에서는 해당 문서 가 검색되지 않는다. 이후 ElasticSearch의 refresh라는 과정을 거쳐야 디스크에 세그먼트 단위로 문서가 저장되고 해당 문서의 검색이 가능해 진다.
세그먼트는 불변(immutable)
기존에 기록한 데이터를 업데이트하지 않는다. 문서 id 1을 대상으로 최초 색인한 이후에 동일한 문서 id 1 을 대상으로 재색인하는 과정을 예로 들어보자.
데이터를 업데이트하려고 시도하면 ElasticSearch는 새로운 세그먼트에 업데이트할 문서의 내용을 새롭게 쓰고, 기존의 데이터는 더 이상 쓰지 못하게 불용 처리한다. 이러한 동작은 update뿐 아니라 delete도 마찬 가지다. 사용자가 문서를 삭제하기 위해 delete를 시도하면 바로 지우지 않고 불용 처리만 한다. 이 특성으로 인해 데이터의 일관성을 유지할 수 있다.
세그먼트 병합(Merging)
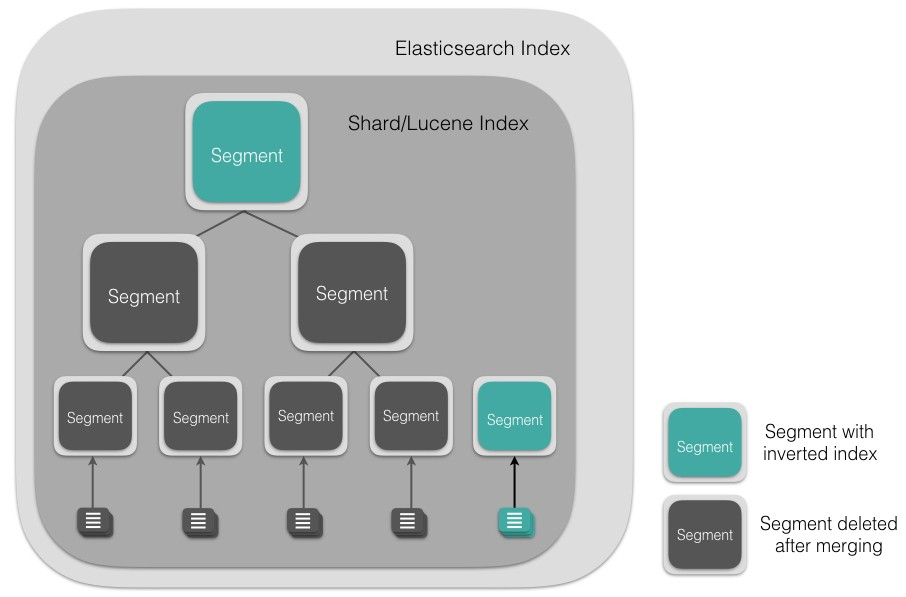
그림 출처 : https://blog.insightdatascience.com/anatomy-of-an-elasticsearch-cluster-part-ii-6db4e821b571
세그먼트 단위로 파일을 생성해서 문서를 저장할 때, 불변의 특성을 유지하기 위해 여러 개의 세그먼트로 사용자의 문서를 색인한다. 따라서 시간이 지나면 작은 크기의 세그먼트가 점점 늘어나 고, 사용자가 문서를 검색할 때마다 많은 수의 세그먼트들이 응답해야 한다는 단점이 생긴다. 또한, 불용 처리한 데이터들로 인해 세그먼트의 크기가 커지게 된다.
프라이머리 샤드와 레플리카 샤드
ElasticSearch는 인덱스를 샤드로 나누고 나뉘어진 샤드에 세그먼트 단위로 문서를 저장한다. 그렇기 때문에 샤드의 상태를 정상적으로 유지하고 장애 상황에서도 유실되지 않도록 관리하는 것은 ElasticSearch 클러스터 서비스의 연속성을 유지하기 위해 꼭 필요한 작업이다. 이 연속성 유지를 위해서 ElasticSearch는 샤드를 프라이머리 샤드와 레플리카 샤드로 나눠서 관리한다.
레플리카 샤드는 프라이머리 샤드와 동일한 문서를 가지고 있기 때문에 사용자의 검색 요청에도 응답할 수 있다. 따라서 레플리카 샤드를 늘리면 검색요청에 대한 응답속도를 높일 수 있다.
- ElasticSearch가 문서를 색인할 때 어떤 번호의 프라이머리 샤드에 문서를 저장할지 결정하는 알고리즘
프라이머리 샤드 번호 = Hash(문서의 id) % 프라이머리 샤드 개수
이 로직 때문에 인덱스 생성 후에는 프라이 머 리 샤드의 개수를 변경할 수 없는 것이다. 만약 프라이머리 샤드의 개수 를 변경한다면 지금까지 저장된 문서들의 프라이머리 샤드 번호가 모두 변경되어야하기 때문이다.
플리카 샤드는 프라이머리 샤드의 복제본 샤드로, 프라이머리 샤드가 저장된 노드와 다른 노드에 저장 된다. 노드 한 대가 장애로 클러스터 에서 이탈할 때 원본과 복제본이 모두 이탈한다면 복제본의 의미가 없기 때문이다.
복제본인 레플리카 샤드는 운영 중에도 샤드 개수를 변경할 수 있다.
샤드의 개수는 색인과 검색의 성능 확보면에서도 중요하다.
- 클러스터에서는 각각의 노드가 색인과 검색 요청을 분배하여 처리한다.
- 하나의 노드로 구성된 클러스터는 레플리카 샤드를 할당할 수 없지만 5대의 노드로 구성된 클러스터는 레플리카를 추가로 구성할 수 있 어 데이터의 안정성을 확보할 수 있다.
매핑
- RDBMS와 비교하자면 스키마와 유사
- ElasticSearch에 저장될 JSON 문서들이 어떤 키와 어떤 형태의 값을 가지고 있는지 정의한 것
- 매핑 정보는 미리 정의해도 되고 정의하지 않아도 된다.
- 정적 매핑 : 미리 정의
- 동적 매핑 : 미리 정의해놓지 않고 사용
- field data type 관련 문서
