딥러닝에서 확률론이 필요한 이유
- 딥러닝은 확률론 기반의 기계학습 이론에 바탕을 두고 있다.
- 기계학습에서 사용되는 손실함수들의 작동원리는 데이터 공간을 통계적으로 해석해서 유도하게 된다.(예측이 틀릴 위험을 최소화하도록 데이터를 학습하는 원리는 통계적 기계학습의 기본원리이다)
- 회귀 분석에서 손실함수로 사용되는 L2노름은 예측오차의 분산을 최소화하는 방향으로 학습이 되도록 유도한다
- 분류문제에서 사용되는 교차엔트로피(cross-entropy)는 모델 예측의 불확실성을 최소화하는 방향으로 학습하도록 유도
- 분산 및 불확실성을 최소화하기 위해서는 측정하는 방법을 알아야한다( 두 대상을 측정하는 방법을 통계학에서 제공한다. 따라서 확률론의 기본개념도 알아야 한다)
-
확률변수는 확률분포에 따라 이산형(discrete)와 연속형(continuous)확률변수로 구분하게 된다.
-
이산형 확률변수는 확률변수가 가질 수 있는 경우의 수를 모두 고려해 확률을 더하여 모델링 한다.
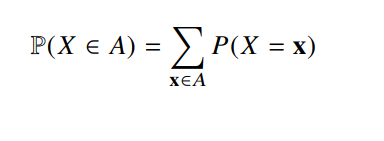
-
연속형 확률변수는 데이터 공간에 정의된 확률변수의 밀도(density)위에서의 적분을 통해 모델링 한다.
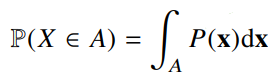
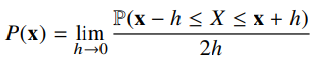
척도에 따른 데이터 구분
범주형 : 몇개의 범주로 나누어진 자료를 의미
- 명목형 : 성별, 성공여부, 혈액형 등 단순히 분류된 자료, 값이 달라짐에 좋고 나쁨이 없음
- 순서형 : 개개인의 값들이 이산적이며 그들 사이에 순서관계가 존재, 값이 커짐에 따라 단계부여가능(만족도, 성적표, 병의단계)
수치형 : 이산형과 연속형으로 이루어진 자료를 의미
- 이산형 : 이산적인 값을 갖는 데이터로 출산횟수 등을 의미, 소수점으로 표현 불가능(불량품 수, 사고 건수, 차량대수)
- 연속형 : 연속적인 값을 갖는 데이터로 신장, 체중 등을 의미, 소수점으로 표현가능(시간, 길이)
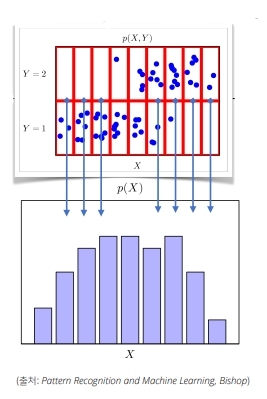
결합분포 P(x,y)는 실제데이터의 확률분포를 모델링 한다.
(실제 데이터의 확률분포는 이론적으로 존재하는 확률분포로 사전에 알 수 없다)

위 그림에서 각 네모칸 마다 파란 점을 셀 수 있다. 이렇게 결합분포마다 분포를 추출 할 수 있고 이를 이용해 실제 데이터의 확률분포를 모델링한다.(원래 데이터가 이산형이거나 연속형 인것에 따라 결합분포가 결정되는것이 아니다. 데이터의 모양을 보고 적절하게 결합분포가 이산형 혹은 연속형인지 정하는것)
P(x)는 입력 x에 대한 주변확률분포로 y에 대한 정보를 주진 않는다.
주변확률분포는 결합분포p(x,y)를 각각의 y에 대해 모두 더해주거나 적분을 통해 얻을 수 있다.
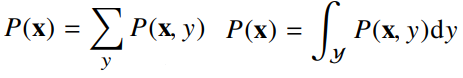
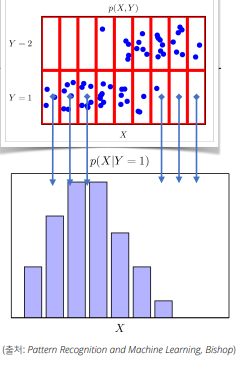
조건부확률분포 p(x|y)는 데이터 공간에서 입력 x 와 출력 y 사이의 관계를 모델링한다.(P(x|y)는 특정 클래스가 주어진 조건에서 데이터의 확률분포를 보여준다)
조건부확률 P(y|x)는 입력변수 x에 대해 정답이 y일 확률을 의미한다.
로지스틱회귀에서 사용했던 선형모델과 소프트맥스함수의 결합은 데이터에서 추출된 패턴을 기반으로 확률을 해석하는데 사용된다.
회귀의 경우 연속형확률변수를 다루기 때문에 확률로 해석하긴 어렵다. 보통 밀도함수로 해석, 조건부기대값E[y|x] 으로 추정(조건부기대값은 E∥y − f(x)∥2 (L2노름식)을 최소화하는함수f(x)와일치한다)
기대값
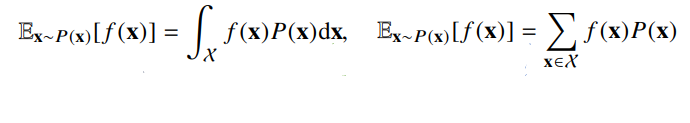 연속확률분포의 경우엔 적분을, 이산확률분포의 경우엔 급수를 사용한다.
연속확률분포의 경우엔 적분을, 이산확률분포의 경우엔 급수를 사용한다.
기대값을 이용해 분산, 첨도, 공분산 등 여러 통계량으 계산 할 수 있어서 매우 중요하다.
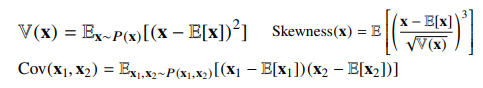
몬테카를로 샘플링
- 기계학습의 많은 문제들은 확률분포를 명시적으로 모를때가 대부분이다.
- 확률분포를 모를 때 데이터를 이용하여 기대값을 계산하려면 몬테카를로 샘플링 방법을 사용해야한다.( 독립추출만 보장되면 대수의 법칙에 의해 수렴성을 보장한다)
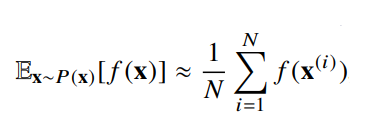
Monte Carlo는 쉽게 말해 통계적인 수치를 얻기 위해 수행하는 ‘시뮬레이션’ 같은 것이다.
"통계적인 특성을 이용해 무수히 뭔가를 많이 시도해본다" 는 의미
