프로젝트 소개
든든킷은 우아한테크캠프 6기 마지막 최종 과제로 진행한 프로젝트입니다. 프로젝트는 총 3주(같은 2주..) 동안 진행되었습니다. 첫 주차에는 기능을 정의하고 구현하는 데에만 집중하였고, 둘째 주차부터는 성능 테스트를 곁들여 서비스의 신뢰성, 가용성을 보수하는 작업에 집중했습니다.
저희 팀은 똑똑하고 실력이 있지만, 그 때문에 걱정도 참 많은 팀이었습니다. 코드를 실행하기도 전부터 코드의 결함, 부족한 부분들을 눈으로 찾아내 고치려 했고, 자칫 오버엔지니어링이 되거나, 쓸 데 없는 부분에 너무 많은 시간을 쏟게 되는 느낌을 받았습니다. 회의 때도 당장 급한 문제는 뒤로 하고 InnoDB Lock에 대해 3~4시간씩 떠들고 토론하다 중요한 문제는 말도 못 꺼내보고 지나간 적도 많았습니다.
그래서 저희는 성능 개선 집중 기간인 2주차 시작 시점에 아래 대원칙을 세우게 되었습니다.
성능 개선 대원칙
귀신을 잡으려 하지 말자. 문제를 눈으로 직접 확인하기 전까지는 아무 문제도 발생하지 않았다고 가정한다. 문제의 발생과 해결 과정, 결과를 객관적 수치로 인지하고 문서화하자.
당장 눈에 코드 문제가 보이더라도, 실행 결과를 정확히 확인하고 해결하면 더 객관적으로 문서화할 수 있고, 학습 차원에서도 큰 도움이 된다고 생각했습니다. 이 대원칙은 프로젝트의 대원칙에서 이제 제 개발 인생의 대원칙이 되었습니다.
성능 요구사항
조회 성능이 300 TPS가 측정되는 어떤 서비스를 생각해 봅시다. 약 10명 정도의 유료 고객이 사용하는 작은 규모의 비공개 서비스를 운영하는 회사에서는 300 TPS의 성능은 충분하다고 느낄 것입니다. 반대로 트위터, 페이스북처럼 매우 거대한 서비스를 운영하는 입장에서 조회 TPS가 300정도가 측정된다고 하면, 반대로 큰 성능 문제로 인식할 수 있습니다.
위 대원칙에 따라 객관적 근거에 따라 성능 개선을 진행하기 위해서는, 문제를 문제로 정의할 수 있는 객관적 기준이 되는 수치가 필요했습니다. 따라서 저희는 성능 개선 작업에 앞서 성능 요구사항을 정의하기로 했습니다.
과제에서 명시한 성능 요구사항
아래는 최종 과제에서 기본적으로 지켜야 할 성능 요구사항이었습니다.
100만개의 데이터를 처리
- 관리하는 데이터 중 100만개의 데이터를 처리할 수 있는 기능을 구현
- 가상의 데이터를 구축하고 실제 서비스에서 발생하는 문제를 경험
- 데이터 처리 과정에서 문제를 정의, 이를 해결하는 경험을 팀원들과 가지기
시스템이 100만건의 데이터를 처리할 수 있어야 한다는 성능 요구사항이 있었습니다. 하루에 100만건이 아니고, DB 테이블 내에 100만건의 데이터를 세팅하면 된다는 요구사항이었습니다. 어떤 테이블에 100만건을 넣을지는 선택 사항이었고, 그마저도 저희가 직접 설계하는 것이 과제였습니다.
어떤 값을 기준으로 할까?
이미 사용자를 확보하고 운영 중인 서비스라면, 서비스 운영 통계를 바탕으로 성능 요구사항을 더 객관적으로 세울 수 있을 것입니다. 하지만 저희는 사용자 없이 저희가 가정한 시나리오대로 성능 요구사항을 설계해야 하는 상황이었기 때문에 객관적으로 모두가 납득할 만한 수치를 기준으로 성능 요구사항을 계산해야 했습니다.
저희는 단순하게 돈에 집중하기로 했습니다. 월 매출 100억 원을 목표로 잡고, 월 매출 100억원을 감당할 수 있는 시스템을 설계하는 것을 목표로 하였습니다.
DAU 계산
든든킷은 밀키트를 판매하는 서비스로, 평소 팀원들의 소비 경험 상 주문 당 평균 35,000원 정도 액수로 구매한다고 합니다. 이를 근거로 한 달에 약 285,714건, 매일 일정하게 주문이 발생한다면 하루 9,523건의 주문이 발생한다는 결론을 내렸습니다.
사용자가 서비스를 사용하고 구매로 이어지는 비율을 25%로 산정하면, DAU 38,000의 트래픽을 처리해야 한다는 결론을 얻었고, DAU 38,000을 버티는 시스템을 성능 요구사항 목표로 결정했습니다.
월 목표 매출 수정
캠프가 끝나고 나중에 알게 된 사실인데, 통계상 평균 구매 전환율은 약 2%정도라고 합니다. 그러면 실제 DAU는 476,150이 되는데, 처음 계산했던 수치보다 12.5배 높은 수치입니다. 따라서 현재 시스템은 100억원보다 12.5분의 1인, 월 8억원 정도를 감당할 수 있다고 매출 목표치를 낮추어야겠습니다.
Peak TPS 계산
피크타임 1시간동안 전체 트래픽의 80%가 균일하게 발생한다고 가정하면, 1시간동안 30,400명의 사용자가 활동한다고 볼 수 있습니다. 아래 가상 시나리오 항목의 계산 결과를 바탕으로, 1명의 사용자에 의해 모든 요청을 통틀어 평균 21.45회 요청이 발생합니다. 이를 기반으로 계산해 보면, 피크 타임에는 약 180 TPS를 처리할 수 있어야 한다는 성능 요구사항을 도출할 수 있었습니다.
가상 시나리오
DB 데이터 분포
주문, 결제 테이블
어떤 데이터를 100만건으로 채울까 고민하다가, 가장 많이 저장될 것 같은 주문테이블의 데이터를 100만건으로 두기로 결정하였습니다. 주문 테이블의 결제 내역을 저장하는 결제테이블 또한 100만건의 테이터를 채웠습니다.
사용자 테이블
사용자는 평균적으로 일주일에 1번씩 저희 서비스를 이용한다고 가정하였습니다. 따라서 DAU * 7 = 38,000*7 = 266,000건이 총 사용자 테이블의 레코드 수가 됩니다.
상품, 재고 테이블
서비스 개업일부터 하루 9,523건의 주문이 발생하는 현재 상태까지 주문건수가 linear하게 단조증가했다고 가정했습니다.
일일 주문 수 증가량을 d, 총 영업일 수를 t 라 하면 아래 두 식을 만족하게 됩니다.
이제 위 식을 풀어보면 총 210일동안 서비스를 지속한 경우, 100만건의 주문이 쌓인다는 것을 알 수 있습니다.
210일, 30주 동안 매 주 350개의 상품을 추가한다고 가정했고, 존재하는 상품의 재고는 1주일에 한번씩 꼬박꼬박 채운다고 가정했습니다. 재고는 유통기한별로 레코드가 따로 생성됩니다.
따라서 상품 테이블에 10,500건, 재고 테이블에 162,750건의 테스트 데이터를 구축했습니다.
테스트 데이터 구축
테스트 데이터는 엑셀과 mockaroo를 활용했습니다. 수치 데이터는 엑셀을 활용해 데이터가 정규분포를 따르도록 구성했고, 상품명 등 랜덤 문자열이 필요한 경우 mockaroo를 이용해 데이터를 생성했습니다.
사용자 시나리오 분포

팀원들과 머리를 맞대고 어떤 유형의 사용자들이 있을지, 사용자 시나리오를 정의해 보았습니다.
- 메인 조회 및 상품 상세조회만 하고 나가는 사용자
- 메인 조회, 상품 상세조회 이후 바로 단건 주문을 결제하고 주문 내역을 조회하는 사용자
- 주문 내역만 조회해 보는 사용자
- 상품을 조회하며 카트에 담기만 하는 사용자
- 상품을 조회하고 카트에 담고 주문을 결제하고 주문 내역을 조회하는 사용자
- 등등
그리고 보드에 기록하며 로그인한 사용자 당 몇 번의 메인 및 상품 조회가 발생하는지, 상품을 조회한 사용자 중 몇 %가 카트에 담는지, 카트에 담은 사람들 중 몇 %의 사용자가 결제까지 이어질 것인지 각 시나리오별로 확률을 계산하여 표로 정리하였습니다.
메인 조회 - 46.62%
상품 상세조회 - 46.62%
카트 담기만 하고 주문 안하기 - 2.792%
주문 전체 내역 조회 - 2.331%
단건 주문 - 0.233%
카트 주문 - 물품 3개 담고 주문 - 1.165%실제로 계산해 본 결과, 조회 트래픽이 훨씬 더 많이 발생할 것이라고 예측할 수 있었고, 성능 개선 시 어떤 부분에 시간을 더 많이 쏟을지, 중요도를 계산할 수 있는 토대가 되었습니다.
성능 테스트
위에서 설계한 시나리오별 발생 비율을 토대로 전체 시나리오 성능 테스트를 작성해 보았습니다.
private void scenarioMove() {
int dice = random.nextInt(429)
grinder.logger.info("dice : " + dice)
switch (dice) {
case 1..200:
// 1. 메인 조회
메인_조회()
break
case 201..400:
// 2. 상품 상세 조회
상품_상세_조회(getWeightedRandomProductId())
break
case 401..412:
// 3. 단건 주문
카트_담기(getWeightedRandomProductId())
break
case 413..422:
// 4. 카트 담기
주문_전체_내역_조회()
break
case 423:
// 5. 카트 주문
단건_주문(getWeightedRandomProductId())
break
case 424..429:
// 6. 주문 전체 내역 조회
카트_주문(getWeightedRandomProductId(), getWeightedRandomProductId(), getWeightedRandomProductId())
break
}
}랜덤을 활용해 위 표와 똑같은 확률 분포를 따르도록 Groovy 스크립트를 작성하였습니다.
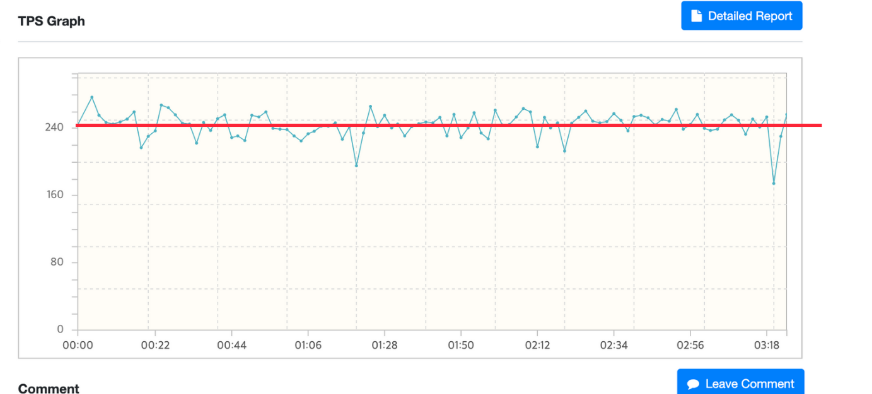
모든 개선 작업을 마치고 데모데이 전날 진행한 최종 성능 테스트에서 약 240 TPS로, 최초로 설계했던 성능 요구사항을 만족시킬 수 있었습니다.
느낀 점
사실 비현실적인 가정도 많았고, 실제 서비스를 운영하는 회사에서는 적용하기 힘든 계산 방식인 것 같습니다. 하지만 학습 프로젝트를 진행하는 과정에서, 실제 트래픽이 어떤 비율로 발생하는지, DB 데이터가 테이블마다 어떤 비율로 분포되어 있을지를 보다 현실적으로 고민하고 상황을 가정했을 때 더 많은 것을 배울 수 있었다고 생각합니다. 또 새로운 서비스를 개발하고 기획하는 과정에서 사용자들이 우리 서비스에서 어떻게 행동할까?에 대해 더 깊게 고민할 수 있게 되었습니다.
시나리오 설계를 하며 현실적으로 계산을 해 보니, 거대한 커머스를 개발하는 소프트웨어 개발자분들이 얼마나 대단한 사람들인지 새삼 느끼게 되었습니다. 22년 7월 기준 쿠팡 DAU가 1100만이었다고 하는데, 정말 대단한 것 같습니다.

백승윤, 그는 신인가? 백승윤, 그는 신인가? 백승윤, 그는 신인가? 백승윤, 그는 신인가? 백승윤, 그는 신인가? 백승윤, 그는 신인가? 백승윤, 그는 신인가? 백승윤, 그는 신인가? 백승윤, 그는 신인가? 백승윤, 그는 신인가? 백승윤, 그는 신인가? 백승윤, 그는 신인가? 백승윤, 그는 신인가? 백승윤, 그는 신인가? 백승윤, 그는 신인가? 백승윤, 그는 신인가? 백승윤, 그는 신인가? 백승윤, 그는 신인가? 백승윤, 그는 신인가? 백승윤, 그는 신인가?