
빅쿼리란 무엇인가?
빅쿼리는 페타 바이트급의 데이터 저장 및 분석용 클라우드 서비스이다.
요즘은 페타바이트급의 Data Warehouse로 부르는데, 쉽게말해서 페타바이트급의 데이터를 저장해놓고, 쿼리를 통해서 조회나 통계 작업등을 할 수 있는 DB(?)이다.
빅쿼리의 특징
클라우드 서비스로 설치/운영이 필요 없음(NoOps)
설치해서 사용하는 서비스가 아닌 구글 클라우드 서비스를 통하여 제공되는 빅데이터 저장-분석 서비스이다.
클릭 몇번으로 서비스 사용이 가능하고, 별도의 설정이나 운영이 필요 없다.
SQL언어 사용
기존의 RDBMS에서 사용되는 SQL언어를 그대로 사용하기 때문에, 사용이 매우 쉬우며 접근성이 좋다.
클라우드 스케일의 인프라를 통한 대용량 지원과 빠른 성능
[예제 링크]https://cloud.google.com/blog/products/bigquery/anatomy-of-a-bigquery-query
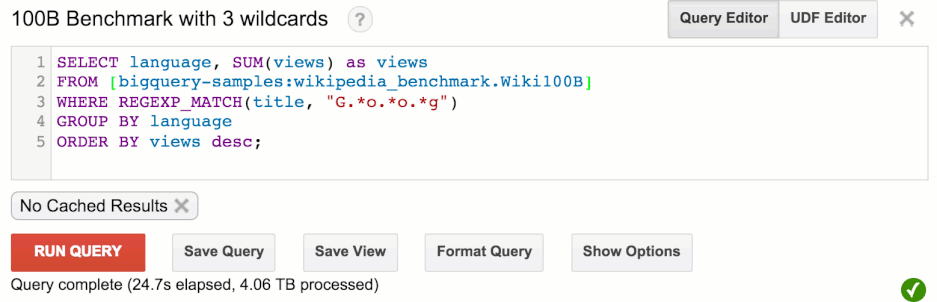
'bigquery-samples:wikipedia_benchmark' DB 내부에서 1000억개의 행, 7TB 용량의 'Wiki100B' 테이블 중 특정문자열을 조회할 경우, 4TB 용량의 데이터가 핸들링 되고, 약 30초가 소요된다.
30초동안 약 3300개의 CPUdhk, 330개의 하드디스크, 330Gigabit의 네트웍이 사용된다.
이 쿼리를 수행하는 데 $20이 소요된다.
일반적인 인프라에서 빅데이터 연산을 하는데, 3300개의 CPU를 동시에 사용하기란 쉽지 않은 일이고, 이런 대용량 연산을 $20에 할 수 있다는 것은 대용량 인프라를 공유하는 클라우드 서비스이기 때문에 가능하다.
데이터 복제를 통한 안정성
데이터는 3개의 복제본이 서로 다른 3개의 데이터센터에 분산되어 저장되기 때문에 데이터에 대한 유실 위험이 적다.
배치와 스트리밍 모두 지원
한꺼번에 데이터를 로딩하는 배치 이외에도 REST API등을 통해서 실시간으로 데이터를 입력할 수 있는 스트리밍 기능을 제공하며, 스트리밍시에는 초당 10만개의 행(row)데이터를 입력할 수 있다.
비용 정책
비용 정책 역시 클라우드 서비스답게, DB 인스턴스와 같은 과금 방식이 아니라서 큰 데이터를 핸들링 하기 위해서 큰 인스턴스를 쓰고, 사용하지 않는 동안에도 과금이 되는 정책이 아니라
저장되는 데이터 사이즈와, 쿼리 시에 발생하는 Transaction 비용만큼만 과금이 된다.
데이터 저장 요금은 GB당 $0.02 이고, 90일이 지나서 사용하지 않는 데이터는 자동으로 $0.01로 가격이 떨어진다.
(가격 정책)https://cloud.google.com/bigquery/pricing
기존 빅데이터 플랫폼과 빅쿼리의 차이점
기존의 빅데이터 분석 플랫폼인 Hadoop, Spark등과 빅쿼리의 차이점은 무엇일까?
쉽다.
보통 하둡이나 스파크 등을 사용하게 되면 Map&Reduce(MR)로직을 사용하거나 SparkSQL을 사용하더라도 일정 수준 이상의 전문성이 필요하다. 또한 MR 로직의 경우 전문성이 있는 개발자가 분석 로직을 개발해야 하기 때문에 시간이 상대적으로 많이 소요되지만 빅쿼리는 로그인 후 SQL만 수행하면 되기 때문에, 상대적으로 빅데이터 분석이 쉽다.
운영이 필요 없다.
하둡이나 스파크와 같은 빅데이터 솔루션의 경우에는 인스톨과 설정, 클러스터의 유지-보수가 보통 일이 아니다.
그래서 별도의 운영조직이 필요하고 여기에 많은 리소스가 소요되지만, 빅쿼리는 클라우드 서비스이기 때문에, 별도의 운영 등에 신경 쓸 필요가 없이 개발과 분석에만 집중하면 된다.
인프라에 대한 투자없이 막강한 컴퓨팅 자원을 활용
빅쿼리를 이용하면 수천개의 CPU와 수백/수천개의 컴퓨팅 자원을 사용할 수 있다.
물론 기존 빅데이터 플랫폼도 클라우드 환경에 올리면 수천개의 CPU를 사용하는 것이 가능하지만, 그 설정 작업과 비용적인 측면에서는 차이가 크다.
빅쿼리 맛보기
- Google Cloud 가입, 정보 입력 후 새 프로젝트 생성

-
빅쿼리 콘솔로 이동
-
쿼리 실행
공개 데이터셋을 실행해본다.
SELECT
name, gender,
SUM(number) AS total
FROM
`bigquery-public-data.usa_names.usa_1910_2013`
GROUP BY
name, gender
ORDER BY
total DESC
LIMIT
10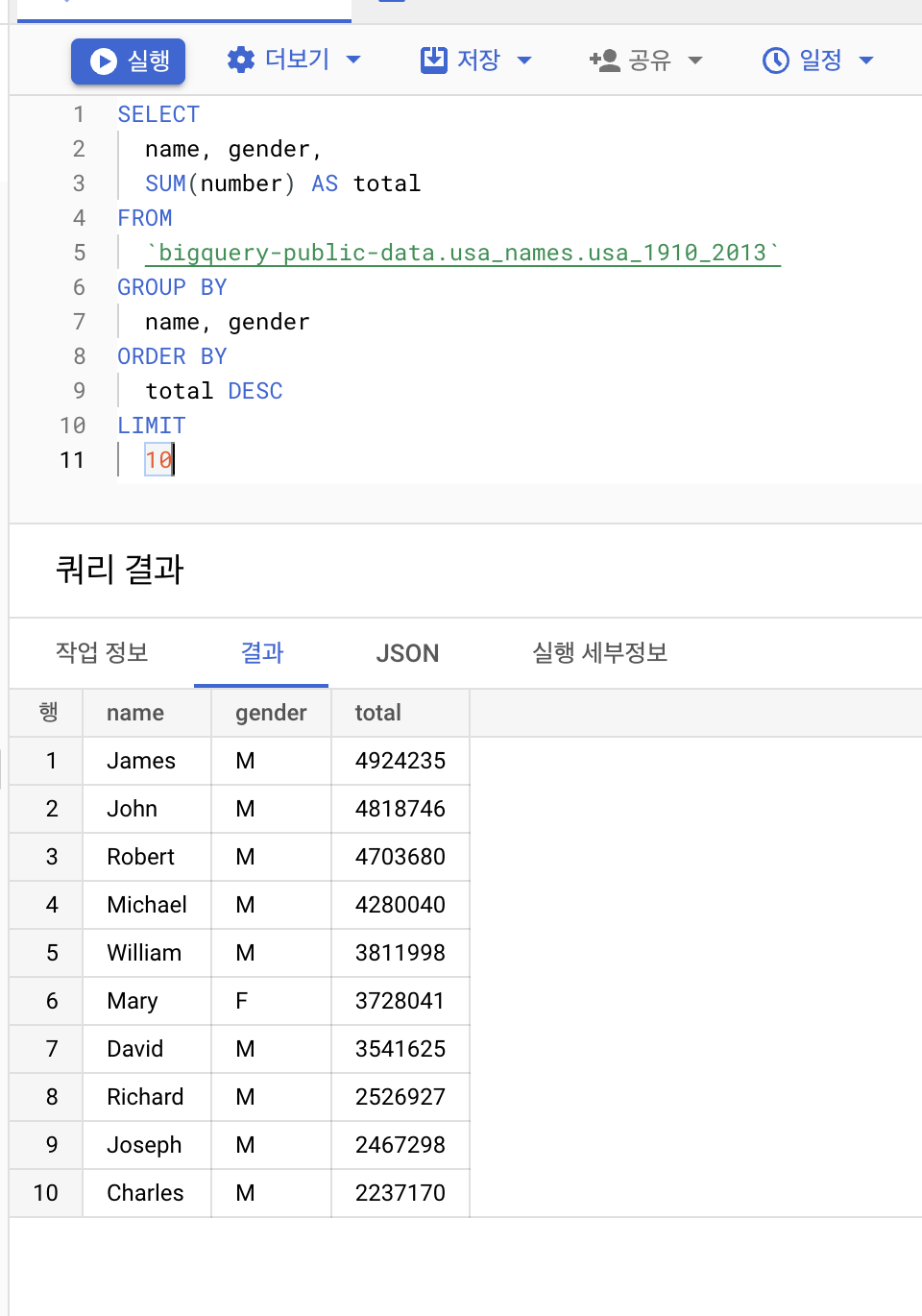
결과 화면

이 쿼리의 실행에 446MB가 처리되었음도 위처럼 나타난다.!
느낀점
대용량 클라우드를 SQL문법으로 간편하고 저렴하게 할 수 있다는 점이 큰 장점이 될 수 있을 것 같다고 느꼈다.
참고
구글 클라우드 공식 문서 - https://cloud.google.com/blog/products/bigquery/anatomy-of-a-bigquery-query
조대협 님의 블로그 - https://bcho.tistory.com/1116

: )