Factorization Machines
0. Abstract
- 본 논문은 SVM과 Factorization 모델의 장점을 합친 새로운 모델을 설명한다.
1. Introduction
- 본 논문에서는 SVM과 같은 일반적인 예측기지만 매우 높은 sparsity에서도 신뢰성있는 매개변수를 추정해주는 FM을 소개한다.
- FM의 모델 방정식은 linear한 시간으로 계산되며 linear한 숫자의 파라미터만 사용된다. 이를 통해 예측을 위한 훈련 데이터를 저장할 필요 없이 모델 매개변수를 직접 최적화하고 저장한다.
2. Prediction under sparsity
Example 1) 영화 리뷰 시스템의 데이터를 처리해보자.
- rating = {1, 2, 3, 4, 5}
- 특정 시간 에서 어떤 사용자 가 영화(item) 를 평가했는지 기록되어 있다.
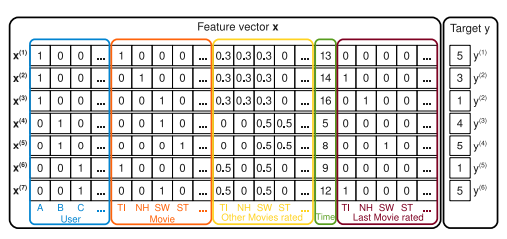
위 그림은 어떻게 S를 통해 feature vector를 만들 수 있는지 보여준다.
- User : 특정 user를 나타내는 binary value
- Movie(item) : 특정 item을 나타내는 binary value
- Other Movies rated: 유저가 평가한 영화들에 대한 정보의 합계가 1이 되게 정규화 된 값
- Time : 시간 정보
- Last Movie rated : 유저가 직전에 평점을 매긴 영화에 대한 binary value
- Target : 평점 데이터
이처럼 MF은 user, movie에 대한 rating만을 사용하지만, FM은 시간을 포함하여 더 다양한 feature를 사용하는 것이 핵심이며, Feature Engineering을 한다는 점에서 SVM과 비슷하다고 주장한다.
3. Factorization Machines(FM)
A) Factorization Machine Model
1) Model 방정식
- : global bias
- : 번째 변수의 가중치
- : 번째 변수와 번째 변수 간의 interaction을 모델링한다.
여기서 우리가 예측해야될 파라미터는 위 세가지이며 n은 faeture의 개수다.
유저 A와 아이템 ST에 대한 interaction을 추정해보자.
유저 A는 ST에 대한 평가를 한 적이 없기 때문에 interaction을 구할 수 없다.
그렇기 때문에 내적을 통해 interaction을 구하는 것이다.
유저 B와 유저 C와의 성향이 비슷한 것을 알 수 있고, 유저 B를 통해 star wars와 star trek은 유사한 interaction을 갖고 있는 것을 알 수 있다.
또한 유저 A와 유저 C의 titanic과 star wars에 대한 평가를 통해 서로 정반대의 성향을 갖고 있는 것을 알 수 있다.
종합해보면 유저 A와 C는 반대성향, 유저 B와 C는 같은 성향, star wars와 star trek은 같은 성향이므로 유저 A의 star trek에 대한 interaction을 구해 예측값 를 찾을 수 있는 것이다.
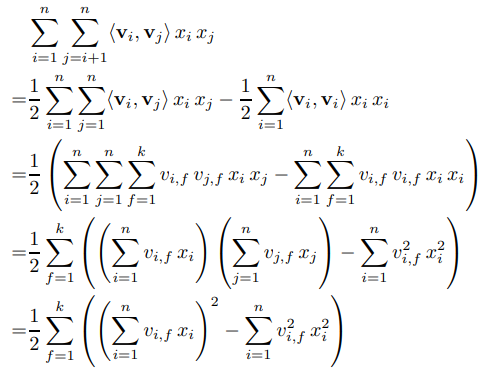
2개의 변수에 대해 직접적으로 영향을 주는 model parameter가 없기 때문에 pairwise interactions은 위와 같이 재구성할 수 있다.
이렇게 재구성 함으로써 complexity를 에서 으로 줄일 수 있었다.
B) Factorization Machines as Predictors
FM은 regression, Binary classification, Ranking 문제를 해결할 수 있으며, L2-norm 을 통해 과적합을 방지했다.
C) Learning Factorization Machines
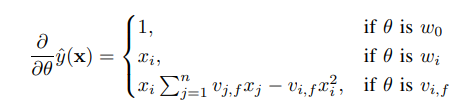
학습은 경사하강법을 통해 이루어지며 SGD를 사용한다.
을 미분했을 때 세 파라미터에 대해 다음과 같은 값을 가지며 는 에 대해 독립적이기 때문에 미리 계산해서 complexity를 감소시킬 수 있다.
D) d-way Factorization Machine
지금까지 설명한 2-way FM은 d-way FM으로 일반화가 가능하다.
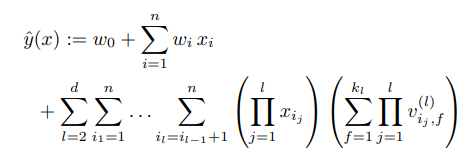
E) Summary
FM은 전체 매개변수화된 interaction 대신 인수분해된 interaction을 사용하여 특정 벡터 x의 값 사이에 가능한 모든 interaction을 모델링한다. 여기엔 두 가지 이점이 있다.
- 높은 sparsity를 가진 데이터라도 interaction을 추정할 수 있다.
- 매개변수의 수와 예측 및 학습시간이 linear하다.
4. FMs vs. SVMs
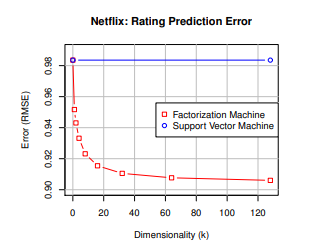
매우 sparse한 문제에 대한 두 모델의 성능 비교 그래프다.
SVM은 차원이 늘어나도 전혀 학습되지 않고 FM은 점점 높은 성능을 보여준다.
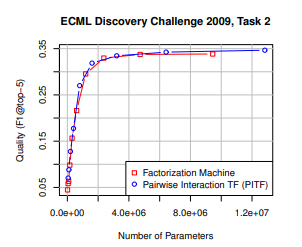
ECML/PKDD 디스커버리 챌린지 2009에서 우승한 PITF모델과 비교한 FM의 성능.
- 결론
- FM은 SVM보다 sparse한 문제를 잘 해결한다.- 여러 모델과 비교함으로써 FM모델이 general하게 적용된다는 것을 증명함.
5. Conclusion and Future Work
- FM은 SVM의 generality한 특성과 factorization model의 이점을 결합했다.
- FM은 매우 sparsity한 데이터를 갖고도 매개변수를 추정할 수 있다.
- 모델 방정식이 linear하다.
