러닝스푼즈 - Practical Spark 강의 를 요약한 내용입니다.
Spark 는 다양한 실행 모드를 지원하고, 각 실행 모드에 따라 컴포넌트의 실행 위치가 달라짐
- Local 모드라면 단일 JVM 내에 Driver 와 Executor 가 존재
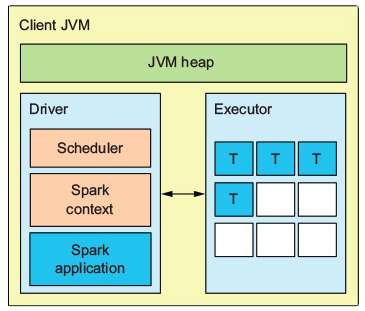
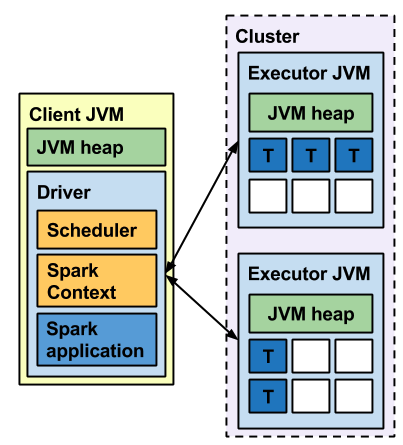
- Client 모드라면 Driver JVM 과 다수의 Executor JVM 이 존재
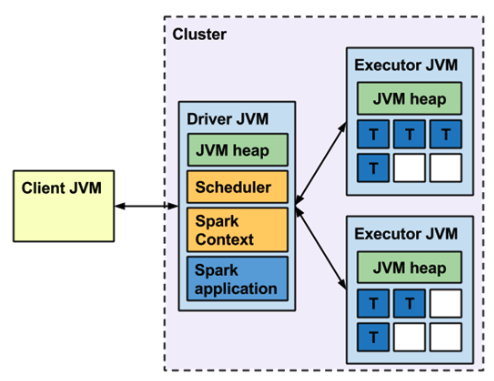
- Cluster 모드라면, JVM 기준으로 Client 모드와 동일하되 Job 을 Submit / Wait 하는 JVM 이 존재
Memory 설정
Spark에서는 다양한 컴포넌트들의 메모리를 조절할 수 있는 옵션을 제공
- Driver
- spark.driver.cores
- spark.driver.memory
- spark.driver.memoryOverhead
- Executor
- spark.executor.cores
- spark.executor.memory
- spark.executor.memoryOverhead
- spark.executor.pyspark.memory
- ETC
- spark.memory.fraction
- spark.memory.storageFraction
- spark.memory.offHeap.enabled
- spark.memory.offHeap.size
- spark.python.worker.memory
- ...
Spark UI 에서 Spark Driver / Executor 의 리소스 설정값 확인이 가능
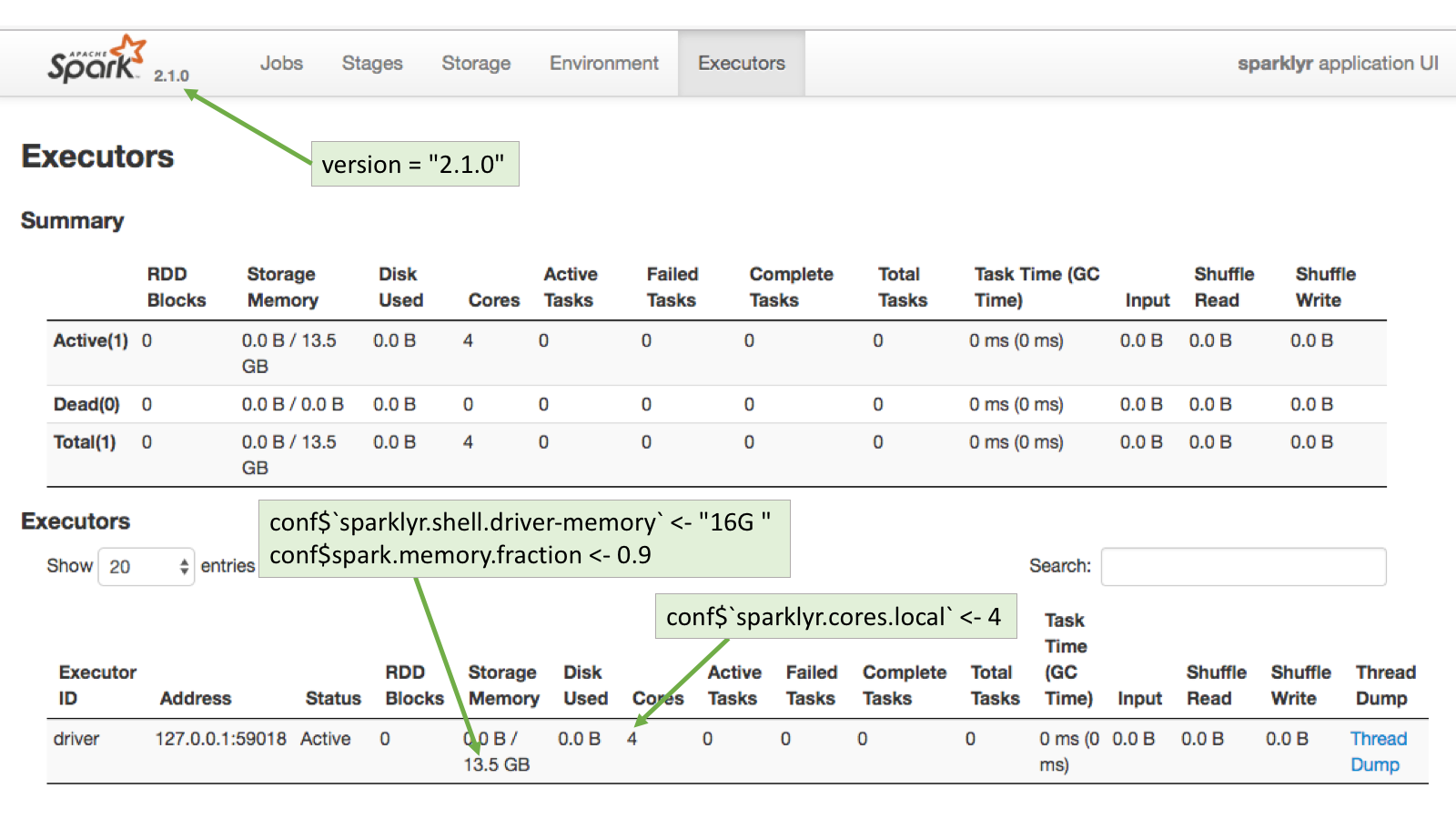
.png)
Spark Executor의 JVM Heap 메모리 구조
- spark.memory.fraction
- spark.memory.storageFraction
- spark.executor.memoryOverhead
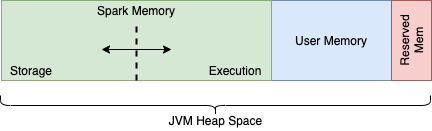
- Spark Memory (
spark.memory.fraction= 0.6, default)- Storage Memory (
spark.memory.storageFraction= 0.5, default)- 캐싱 (DataFrame.cache, CACHE TABLE) 또는 Broadcast, Driver 로 보내는 결과들이 이 영역의 메모리를 사용
- Execution Memory (
spark.memory.storageFraction를 제외한spark.memory.fraction)- 데이터 집계 과정에서 Shuffle, Aggregation, Sort 등을 위해 사용
- Storage Memory (
- User Memory (전체 JVM Heap 에서
spark.memory.fraction와Reserved Memory를 제외 영역)- Spark 가 사용하는 내부 메타데이터, 사용자 생성 데이터 구조 저장이나 UDF 및 OOM 을 방지하기 위한 대비 (Safeguard) 영역으로 사용
- Reserved Memory (300 Mib)
일반적으로 'Executor 메모리가 부족하다' 라고 말하면 Spark Memory 가 부족한 경우가 대부분이므로, 이 경우에는
- Executor 가 사용하는 전체 JVM 메모리 사이즈를 늘리거나
spark.memory.fraction값을 올릴 수 있음
캐싱을 많이 사용한다면 Storage Memory 가 모자랄 수 있음
spark.memory.storageFraction 값을 늘릴수도 있겠지만, Spark 1.6 부터는 Unified Memory Management 가 도입되면서 Storage와 Execution 이 통합되었기 때문에(Spark Memory) 큰 효과가 없을 수 있음
만약 메모리가 부족하다고 판단이 되면, 전체 메모리를 늘리는 편이 나음
Spark Memory 가 통합되면서
- 캐싱을(Storage) 사용하지 않을 경우, Execution(집계)를 위해 Stroage Memory 영역을 사용 가능
- 캐싱을(Storage) 많이 사용한다면 Execution Memory 영역을 필요 시 더 사용 가능
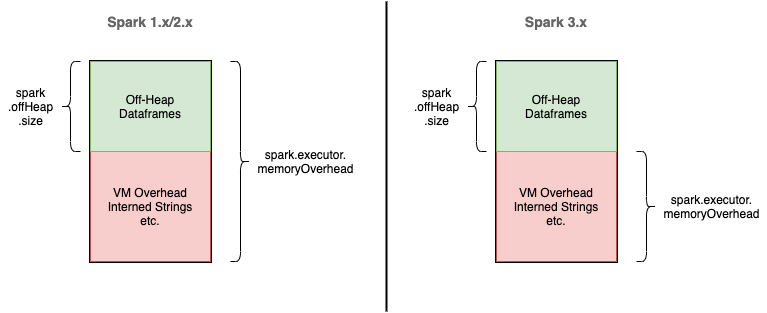
Memory Overhead 및 Off-heap 옵션은 JVM 메모리 외의 영역에서 Spark 가 사용할 메모리를 지정
Spark 3.0+ 를 기준으로 보면 JVM 외 영역에서
spark.executor.memoryOverhead(= executor.memory * 0.1, default)- PySpark 를 사용할 경우 Python Process 의 메모리 (
spark.executor.pyspark.memory) 등 Non-JVM 메모리 영역을 지정
- PySpark 를 사용할 경우 Python Process 의 메모리 (
spark.memory.offHeap.size(= false, default)- String 을 저장하는 등 Java (JVM) 이 내부적으로 사용하는 용도 및 Spark 의 특정 기능을 위해 사용
JVM 및 Non-JVM 메모리 영역(Executor Memory 전체)
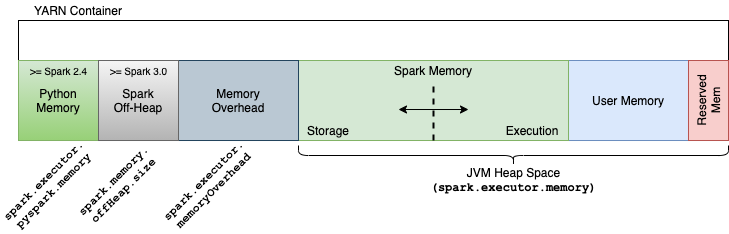
Pyspark w/ Apache Arrow
PySpark 를 사용한다면 다음 두 가지의 메모리 옵션을 설정 가능
spark.python.worker.memory(512m, default) 는 JVM 내에서 Python Worker 의 집계를 위해 사용되는 영역spark.executor.pyspark.memory(설정되지 않음, default) 는 실제 Python Process 의 메모리spark.executor.pyspark.memory는 기본값이 설정되어 있지 않으므로 PySpark 사용시 DataFrame 대신 일반 Python 객체와 함수를 이용해 가공하는 등 메모리를 많이 사용할 경우 메모리가 터질 수 있음
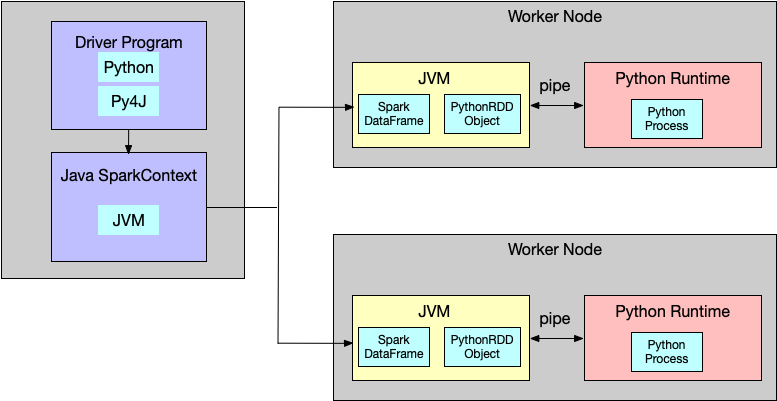
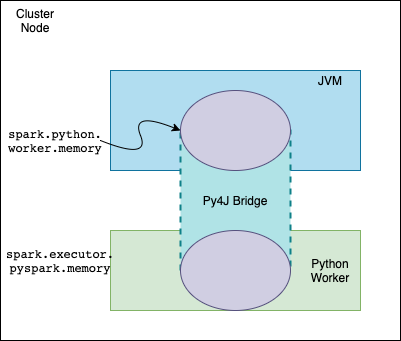
- PySpark 를 사용하면 Scala Spark 를 사용할때와는 다르게 Python 프로세스가 존재
- Python Driver Process 는 Py4j 를 이용해서 별도 JVM 프로세스에 Spark Context 를 생성
- PySpark 에서도 spark.sparkContext 객체가 존재하지만, 이 것은 명령을 내리기 위한 객체이며 실제로는 명령을 받은 JVM 내의 SparkContext 가 필요한 작업을 수행
- 같은 노드 내에 있더라도 Python Process 와 JVM Process 는 서로 다른 프로세스이므로, 데이터 (메모리) 를 공유할 수 없음
- IPC (Inter-process Communication) 간 통신을 위해 Socket 을 이용 (Executor 는 Pipe 를 사용)
- Scala Spark 를 이용할 경우 필요 없을 Socket 통신을 이용해 데이터를 주고 받으므로 PySpark 는 느린 경우가 많음
- Arrow 와 같은 공통화된 메모리 직렬 포맷을 이용한다면 Serialization / Deserialization 을 효율적으로 수행 가능
- PySpark 의 toPandas 는 Arrow 가 활성화 되어 있을 경우 이를 이용하도록 구현

# data engineering